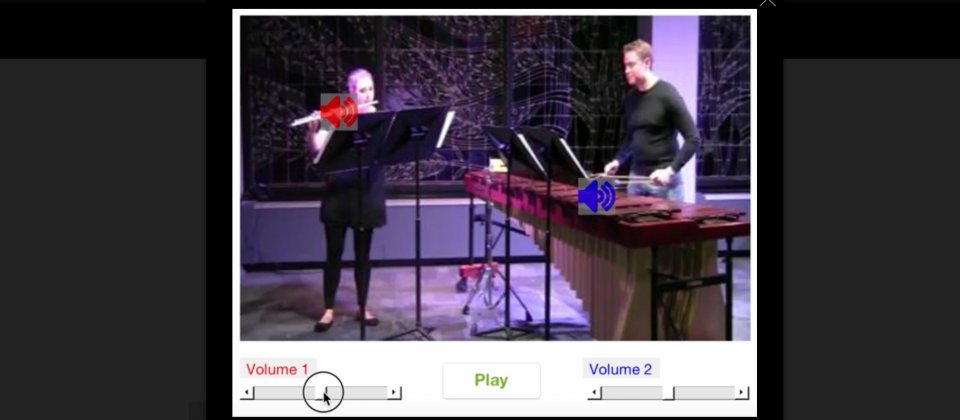
MIT發展出名為PixelPlayer的人工智慧系統,由演算法自我監督觀看60小時的音樂表演影片後,不需要人類介入訓練,便可以自動辨識出20種樂器的聲音,並且理解聲音與畫面中樂器的對應關係,提供使用者獨立編輯聲音的能力,對於舊音樂再製有很大的幫助。
MIT的電腦科學與人工智慧實驗室(CSAIL)發展出以深度學習辨識樂器表演影片,除了能分離出特定樂器聲音外,還能對這些聲音進行個別編輯的系統。這個稱為PixelPlayer的系統,經過60小時的音樂會影片訓練,可以辨識超過20種樂器,論文第一作者Hang Zhao提到,儘管該系統現在還無法細膩的處理類似聲音之間的細微差異,像是PixelPlayer現在還分不出中音薩克斯風與男高音的差別,但只要有越多的訓練資料,系統就能辨識越多種類的樂器。
PixelPlayer使用深度學習的方法,以類神經網路在影片裡尋找資料的模式,系統包含3個類神經網路,其中一個用於影片的視覺分析,第二個用於影片的聲音分析,第三個合成器能將特定的像素與聲音關聯,並獨立分離出來。系統會先定位出影片中發出聲音的區域,再將聲音分離出來,並與這些像素關聯。
研究團隊提到,這個方法使用自我監督(Self-supervised)的深度學習,人工智慧在沒有人類介入告知聲音與樂器的關聯,就能自動理解之間的關係。過去分離聲源的研究通常專注在聲音上,而這也需要大量的人為標籤,但PixelPlayer則是額外加入的視覺要素,以視覺元素取代人為標籤,以達到人工智慧自我接督學習的目的。
Hang Zhao表示,他們原本預期系統的最佳案例,就只是讓系統分辨不同樂器的獨特聲音,而現在卻可以額外在空間中,以像素等級定位出樂器,這樣的能力開啟了更多可能,使用者可以直接透過點擊影片中的樂器,進行聲音編輯。
這項研究的貢獻在於,有助於工程師提高舊音樂的錄製音質,製作人甚至可以分開聆聽不同樂器演奏的聲音,除了可以單獨調整個別音量外,還可以於後製階段,更換演奏的樂器,另外,這項研究也能被應用在機器人開發上,使其能更好的理解環境物體所產生的聲音,像是正在吠叫的狗或是發出引擎聲的車輛。
MIT開發的AI音樂影片編輯系統:
熱門新聞
2025-12-24

2025-12-26

2025-12-26

2025-12-26

2025-12-26

2025-12-29

2025-12-26