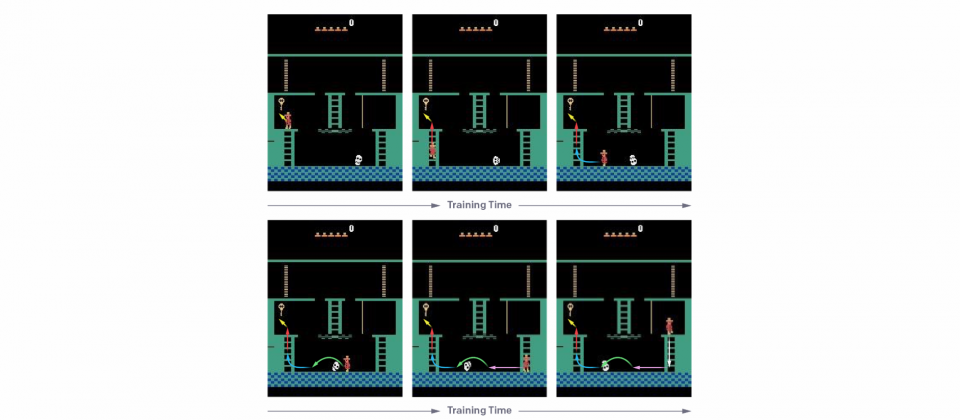
人工智慧越來越會玩遊戲了,除了Dota2全人工智慧代理人(Agent)OpenAI Five團隊已經可以打敗人類外,OpenAI的最新研究,人工智慧代理人只要看過人類示範遊玩蒙特祖馬的復仇(Montezuma’s Revenge)一次,便能學習遊玩技巧並獲得74,500的高分。而與其他研究不同的是,OpenAI不再要求代理人(AI玩家)模仿人類行為,而是更直覺的對取得高分的行為做最佳化。
OpenAI使用了簡單的演算法,只要從人類遊戲示範中挑選一段適當的狀態(階段),這個狀態指的是某一段遊戲示範的歷程,代理人再接著狀態後繼續遊玩,並在示範過程使用近端政策最佳化(Proximal Policy Optimization,PPO)的增強學習,如此就能達到與人類相當的遊玩程度。
OpenAI提到,要解決使用增強學習的問題,有兩個重點,第一是屬於探索問題,為了找出一系列趨向正面獎勵的行動,第二則是學習問題,代理人要可以記得行動序列,並在些微不同的情況下稍微改變策略。
而探索是一件困難的事,一般常用的策略是,藉由採取隨機行動以政策梯度(Policy Gradients)或是Q-learning這類無模型的增強學習方法進行探索。最佳的情況為,剛好隨機選擇到了有益的行動而獲得獎勵,那這些行動便會被增強,代理人未來將有更大的機率選擇這些有益的行動。當隨機行動的獎勵足夠頻繁,隨機行動便更容易以合理的機率獲得獎勵。但OpenAI指出,像蒙特祖馬的復仇這類複雜的遊戲,需要比較長序列的具體行動才能獲得獎勵時,要隨機到特定序列的行動組合簡直不可能發生。
儘管無模型增強學習適合短序列行動,難以應付長序列的行動,OpenAI表示,他們的策略則是將大任務拆成許多子任務,這些子任務就可以用短序列行動解決。OpenAI都以人類的示範,開始每一個增強學習的章節(Episode)。
在訓練初期,代理人在示範結束時,開始每一增強學習訓練章節,一旦代理人能在至少20%剩餘遊戲部分中,擊敗或是與示範者的得分平手,便開始把代理人遊戲的起始點往前移動,這個過程不停重複,直到代理人不再需要使用示範,而這也表示這個代理人已經能夠打敗人類,最糟的狀況也只會跟人類打成平手。

透過漸漸的把代理人遊戲起始點往前移的過程,代理人已經能夠解決大部分剩餘的遊戲,便能確保其遇到的都是簡單的探索問題,OpenAI提到,他們將增強學習的問題解釋為動態程式設計的一種形式,也就是當要從由N個行動組合而成的特定序列獲得獎勵,則這個序列能以線性而非指數時間被學習。研究人員指出,代理人有人類示範,對於成果好壞至關重要。
由於Google旗下DeepMind,最近也展示了人工智慧遊玩蒙特祖馬的復仇這款遊戲的成果,OpenAI表示,DeepMind是以模仿學習(Imitation Learning)來學習遊戲,這個方法的優點是,他們不需要對執行環境進行控制,不需要特別設置遊戲的狀態(階段),而且不會假設代理人會遭遇到人類示範中的所有遊戲狀態,但缺點就在於,這方法讓代理人去學習人類的行為,而這也只會讓代理人的遊戲技巧頂多跟人類一樣。
OpenAI的方法直接對遊戲的目標,也就是分數做最佳化,而非僅要代理人模仿人類行為,OpenAI強調,他們的方法不會過度適應潛在的次優示範,並可以在多玩家遊戲中仍然獲得優勢。該方法所使用的PPO與OpenAI Five相同。這個研究的價值在於,允許代理人偏離示範行為,因此有機會考慮人類示範者沒有想過的解決方案。
熱門新聞

2026-02-20

2026-02-23

2026-02-23
2026-02-20

2026-02-23


2026-02-21