DeepMind
Alphabet子公司DeepMind近日已發展一人工智慧型系統,只要觀察2D影像就能建立其3D場景。
DeepMind的研究人員說明,人們理解視覺場景時並不只光靠眼睛,還必須仰賴腦袋裡的知識進行推理,例如在一個房間裡看到一張桌子的三隻腳時,人們會推論還有一隻同樣形狀與顏色的腳藏在看不見的地方,就算是無法看到整個房子的場景,也能想像或畫出它的布局。
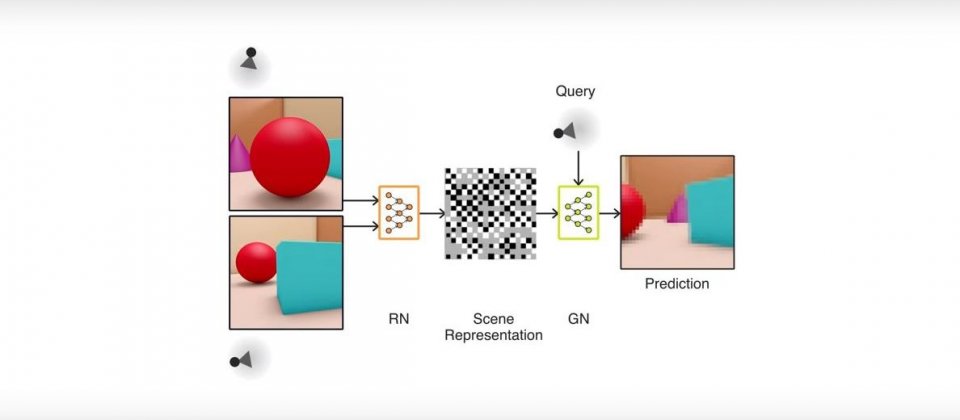
這樣的視覺與認知對人類來說似乎毫不費力,但對人工智慧(AI)系統而言卻是重大挑戰,目前最先進的視覺辨識系統是利用由人類建立並註解的大量資料集進行訓練,只是建立這些資料集的工程非常耗大,這使得DeepMind開發了生成查詢網路(Generative Query Network,GQN)框架,讓AI得以藉由它們在場景中移動時所獲得的資料進行訓練,學習如何感知周遭的環境。
GQN框架介紹:
換句話說,GQN是個自主學習系統。GQN是由表現網路( representation network)與生成網路(generation network)所組成,前者基於代理人的觀察輸入了數據,以產生場景的描述,後者則是自未觀察到的視點預測場景的樣貌。
表現網路必須盡可能精確地描述場景,包括物件的位置、顏色與房間的布局,生成器在訓練中學到了環境中的物件、功能、關係與規律性,於是,表現網路是以高度壓縮及抽象的方式描述場境,而生成網路則是負責填補詳細的資訊。
在DeepMind的實驗中,他們部署了一個3D的世界,內有隨機擺設的各種物件、顏色、形狀、紋理及光源等,在利用這些環境進行訓練後,由表現網路來形成一個新的場景,顯示出生成網路能夠從全新的視野來想像從未被觀察到的場景,產生一個不管是光線或形狀都正確的3D場景。生成網路還能從表現網路所觀察到的積木平面圖,畫出完整的3D積木配置。或者是在視野受阻的迷宮中來回地觀察,結合眾多有限的資源描繪出正確的3D場景。
研究人員表示,與傳統的電腦視覺技術相較,此一方法仍有諸多限制,而且目前只能於合成場景中訓練,但隨著新資料的出現與硬體能力的提升,GQN框架將能應用至實體場景與更高解析度的影像,DeepMind也會探索GQN在場景理解上的更多應用,例如查詢空間與時間來學習物理與運動的常織,或是應用在虛擬與擴增實境上。
如何讓AI學習看見:
熱門新聞

2026-02-20

2026-02-23

2026-02-23
2026-02-20


2026-02-23

2026-02-21