由Apache Spark技術團隊所創立的Databricks釋出開源機器學習平臺MLflow,不只對社群開放原始碼,進一步使用開放介面,要支援既有的機器學習函式庫、演算法以及工具,同時Databricks也提供MLflow的託管服務,不過,MLflow仍在早期的測試階段,想嘗鮮的開發者可以在GitHub上取得專案程式碼。
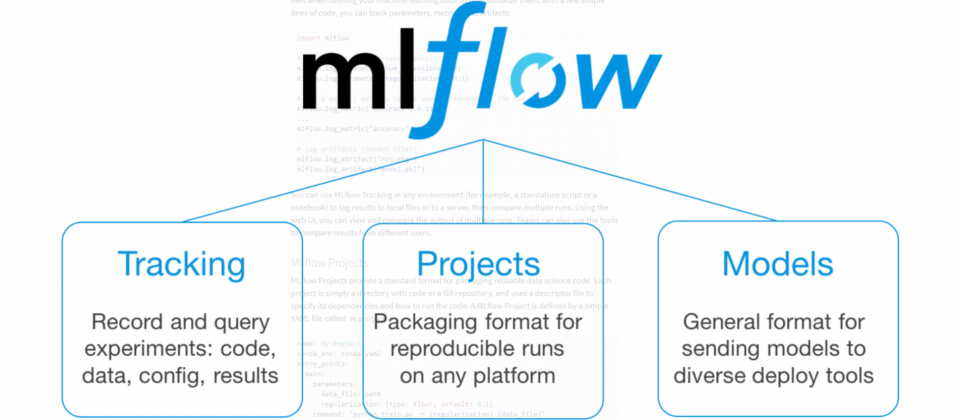
MLflow包含三大部分,追蹤(Tracking)、專案(Projects)以及模型(Models)。MLflow追蹤是用於日誌參數、程式碼版本、指標以及輸出檔案的API和使用者介面,使用者以腳本或是筆記本檔案紀錄日誌結果,可以選擇儲存在本地端或是伺服器上,之後可以使用網頁介面讀取來比較不同的執行結果。
而MLflow專案提供可重複使用的科學程式碼標準格式,每個專案都單獨為一個目錄或是Git程式碼儲存庫,並由YAML檔案來定義MLproject。MLflow專案可以在套件管理器Conda環境中建立相依性,而MLflow會自動設定適合的環境執行專案,而且當專案有使用MLflow追蹤API,MLflow還會記錄專案的版本以及相關參數,開發者可以隨時重新執行完全相同的程式碼。MLflow專案提供了良好的重現性、可擴展性以及實驗性,讓企業或是開源社群都可以更容易地共享資料科學應用。
MLflow的第三部分模型,MLflow的機器模型包稱為MLmodel,其中可以包含任意檔案以及一個MLmodel描述文件。MLflow提供輸出工具,可以把常用的模型格式部署到不同平臺上,官方提到,開發者可以將支援Python_function的模型部署到基於Docker的REST伺服器,也可以選擇部署到各種雲端平臺,像是Azure ML或AWS SageMaker,或是在Apache Spark提供的批次或是串流推測中,作為用戶自訂義功能。
Databricks不只開源MLflow的程式碼,也選擇使用開放介面,官方表示,MLflow是設計來搭配任何的機器學習函式庫、演算法、開發語言以及工具,以REST API以及提供簡單資料格式做為設計理念,開發者可以把MLflow的模型看做是一個Lambda函式,能被不同的工具使用,因此Databricks提到,MLflow好處就是可以立刻增加到既存的機器學習程式碼中,開發者馬上就能執行使用。
之所以會有MLflow這個專案,官方提到,現在市面上的機器學習工具千百種,但是除了不容易追蹤機器學習的實驗外,還很難重現相同的結果,而且也缺乏搬遷模型的標準,因此機器學習的應用常會被工具以及環境綁住,開發者害怕移植後會有不可預期的問題,而開源機器學習平臺MLflow的出現,便是要試圖解決這些問題。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-06


2026-03-09