
不少人觀賞YouTube上的影片內容,會發現YouTube會推薦許多你可能感興趣的內容,Google今天揭露這項服務背後的關鍵技術為機器學習,透過機器學習過濾出使用者可能感興趣的內容,以提供用戶個人化的體驗。
全球每分鐘約有超過500小時的影片被上傳到YouTube,這些大量的內容中,如何找出使用者可能感興趣的內容推薦給他們,成為YouTube服務團隊的任務之一。YouTube工程研發副總裁Cristos Goodrow表示,YouTube的工作之一就是幫用戶在大量的內容中找到他們想看的,進而改善他們的服務體驗、提昇滿意度。
為了達到這個目標,YouTube持續優化服務,例如2011、2012年間將演算法從觀看次數(Views)改為觀看時間(watchtime),雖然這麼做導致了觀看次數在一天內下降20%,但觀看時間卻從平均120秒提高到140秒,到如今,2017年全球每天YouTube觀看時數已達到10億小時。從觀看次數轉為觀看時數,代表YouTube更看重使用者的黏著度,也就是用戶可能感興趣的內容。
由於觀看行為的改變,人們從PC觀看YouTube逐漸轉向在手機、平板電腦上觀看,據統計現已有超過60%觀看時間是在行動裝置上,YouTube也在2014年到2015年優化行動網頁,讓頁面的排版更個人化外,還導入了Google Brain團隊的機器學習技術,改善YouTube影片推薦的準確性,讓影片觀賞經驗更個人化。
去年到今年YouTube大大小小共推出190個更新,目的為提昇用戶滿意度、維持新鮮感,讓網頁更個人化,並重新設計行動首頁,使介面更簡潔,首頁顯示和使用者相關的個人化推薦影片。種種改善造就現今超過70%的觀看時間來自YouTube自動推薦的內容,YouTube首頁每天推薦2億支不同內容影片,在首頁點擊推薦影片的觀看時間,三年來成長了20倍之多。

全球YouTube用戶超過7成的觀看時間來自自動推薦影片,YouTube如何在龐大的影音內容中挖掘出使用者可能感興趣的內容推薦給用戶,背後的功臣是Google在2015年開源的TensorFlow的機器學習技術,打造YouTube影片推薦系統。
以TensorFlow架構的機器學習模型,讓深度神經網路系統更快運作、更有彈性:
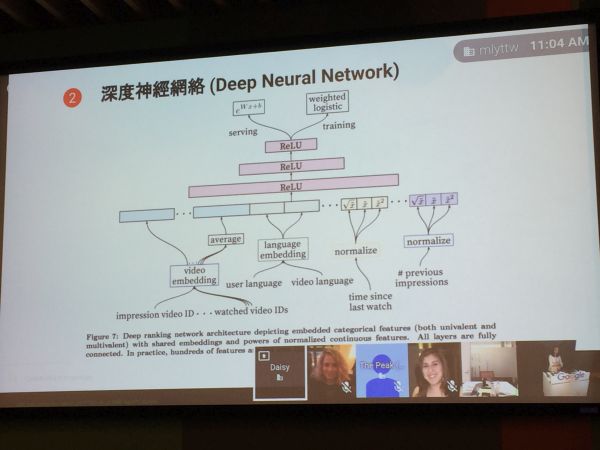
TensorFlow被運用在Google Photos及翻譯服務中,而在YouTube影片推薦系統結合了兩個神經網絡,候選生成模型(Candidate Generation Model)及排名模型(Ranking Model)。

如上圖所示,推薦系統會先從候選生成模型,考量使用者過去的瀏覽影片歷史、捜尋歷史、人口變項等變數,將YouTube的影音資料庫中的數百萬個影音資料篩選出數百個和使用者相關的影音資料,以貼近使用者的喜好。
接下來再經過排名模型(Ranking Model),通過提名特徵(Nominating features),特徵包括了人口統計資如地理位置、最受歡迎影音、使用者語言、影片使用的語言、近期觀看紀錄、使用者和該頻道過去的連結等等特徵,以權重評分找出和使用者有關鏈性的訊號(Signals),以產生數十個影片推薦給使用者。為使用戶感受到YouTube瞭解使用者的喜好,YouTube隨時會準備100小時用戶可能感興趣的內容。
Cristos表示,候選生成模型就像去賣場購物時,將商品從貨架上放到購物車中,而排名模型則是從中排序,挑出你想要的。透過機器學習技術打造的推薦系統,讓YouTube能夠自動推薦使用者想看的。
值得注意的是,YouTube的推薦系統不僅針對個人喜好,還細緻化到個人所使用的不同裝置。YouTube大中華與紐澳技術管理負責人葉佳威表示,YouTube為實現個人化體驗,隨時會為用戶準備100小時用戶感興趣的內容,即便相同的使用者在不同的裝置上觀看YouTube,系統也會依不同的裝置推薦適合的影片給用戶,例如在家透過Chromecast在電視上看YouTube,通常觀看的時間會比較長,而和在外面以手機看YouTube, 觀看時間會比較短,不適合推薦較長時間的內容,因此系統會考量不同的使用裝置推薦YouTube內容。
在推薦系統上採用機器學習,提供用戶個人化的內容,讓使用者可以更容易的在YouTube上找到他們想要看的,推薦的內容更合乎使用者的心意,YouTube認為對廣告主、內容創作者也有好處,廣告主更容易鎖定目標群,創作者的上傳內容也容易被感興趣的人看到,但YouTube也承認自動化的影片推薦可能讓受歡迎的內容變得更受歡迎,影響其他內容被看到的機會,也是未來還需克服的。
除了YouTube推薦系統採用機器學習,為避免YouTube遭到濫用,散佈恐怖主義、暴力內容,今年6月YouTube也開始用機器學習協助辨識不當內容,過去仰賴使用者檢舉不當內容,運用機器學習後,YouTube團隊審核了超過100萬部影片,作為機器學習訓練實例,提昇辨別的準確度,根據9月的數據,83%的暴力極端主義內容在被檢舉前就被辨識出來。
另外,Google也嘗試以AVA(Atomic Visual Actions,原子視覺化動作)數據學習模式,運用機器學習瞭解YouTube影片中的人物行為動作,做法是從YouTube影片中截取15分鐘的片段,再將片段均分為300組時間只有3秒的小片段,已事先定義的人類原子動作下標籤,例如走路、踢球、握手,再依標籤下註解,AVA將人類行為分為姿勢或移動、人與物互動行為、人與人互動三類。目前以AVA分析超過57萬個影片片段,產生21萬個標籤,標註了9.6萬組人類動作,日前已釋出了這些人類行為資料集,希望拋磚引玉,吸引更多研究投入,發展出更多應用。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02