
資料倉儲龍頭Teradata,近日於中國北京舉辦2016 Teradata大數據峰會,Teradata大中華區首席執行長辛兒倫表示,Teradata旗下開源大數據顧問服務Think Big將擴展至中國市場。除此之外,Teradata近日也宣布將旗下的資料倉儲產品線延伸至混合雲環境,並瞄準IoT資料分析市場,成立全球IoT資料分析部門。
【中國北京現場報導】資料倉儲龍頭Teradata(天睿公司),近日於中國北京舉辦2016 Teradata大數據峰會來展示擁抱開源的新進展,上千名金融、電信等各產業的資料分析領域專家及高階主管參與。Teradata近日陸續揭露多項新戰略,包括旗下開源大數據顧問服務Think Big將擴展至中國市場、成立全球IoT資料分析部門,也將旗下的料倉儲產品線延伸至混合雲環境。
今年特別將「開源融合」這四個字放進大會主題,可以看到這個過去39年專注於資料倉儲、資料庫及資料分析領域的老牌大數據公司,現在也要再朝開源更進一步,積極擁抱並且推動開源技術。
戰略一 擴大開源布局
在開源布局上,Teradata也與Facebook(臉書)合作推動開源專案Presto,Presto是臉書專為資料導向組織所開發的互動式資料查詢系統,可即時處理PB等級的資料,目前以開放原始碼方式釋出。透過Presto的單一查詢,不僅可存取Hadoop、Cassandra平臺上的資料,也能串連至其他關聯式資料庫,如MySQL和PostgreSQL。臉書自身便採用Presto來處理超過300PB的資料,每天有上千名員工透過Presto來進行多達3萬次的查詢,除此之外,Airbnb及Dropbox也都採用Presto這套互動式資料查詢系統。
而Teradata目標是加速Presto開源專案推動,讓Presto可更適用於企業環境,提供如強化監控與管理功能、YARN平臺整合,ODBC/JDBC驅動程式支援、生態系統整合與BI工具認證等。
另外,Teradata也在這次大會中正式介紹剛於3月底進軍中國的旗下開源大數據技術顧問公司Think Big,可幫助企業部署資料湖、打造如Hadoop、Spark、Kafka、HBase等大數據平臺的服務。Think Big於2010年成立,2014年被Teradata併購後,目前其開源服務已經擴展至美洲、歐洲、亞洲,並於11個國家設置辦公室,包括Facebook、Intel、NetApp、NASDAQ、美國運通等採用。
Think Big創辦人兼總裁Ronald Bodkin表示,目前Think Big團隊在中國已經有超過10人的規模,並以技能領域來畫分,其中包含資料科學家、資料工程師,也有負責營運與推動計畫的人,其中資料工程主要協助企業對資料進行整合、管理,並打造資料湖及資料相關的應用。
大數據分析需求已無法用單一平臺或技術來滿足
Teradata大中華區首席執行長辛兒倫在大會上表示,Teradata除了提供資料分析解決方案、產品與服務,讓企業選擇在公有雲、私有雲或混合雲環境中運行之外,主要產品策略是協助企業建立資料分析的生態系統,也就是先前推出的統一資料架構平臺UDA(Unified Data Architecture)。
統一資料架構平臺UDA可用來整合並分析所有類型的資料,支援Aster資料庫、開源技術如Hadoop、R語言,也支援SAS、MongoDB及Oracle資料庫等。目前Teradata主要產品還包括基於開源Kafka專案的產品Teradata Listener、可以無縫查詢多個異質資料庫的QueryGrid平臺、Aster圖像式的資料挖掘探索平臺,此外,在資料分析層,也支援R、Spark,Giraph等,並支援多項BI存取工具。
辛兒倫歸納出三大維度的資料類型與分析應用需求,包括在深度上,需要更快速地整合分析來自企業跨部門之間,屬於關係性強、結構性強的業務型資料;寬度上,企業開始需要進一步融合公司內、外部的資料,屬於關係不明確、且結構不清晰的大數據,最後則是在跨度上,於產業內,甚至各產業之間,建立跨界的資訊共享機制。
從資料分析流程來看,IT資料部門與公司內外部的最終用戶,要先定義出一個共同認可的價值場景,再建立一套資料採集、獲取、整合與建立模型、查詢以及分析應用的流程。他認為,企業常遇到的資料分析問題,包括不同資料來源的資料結構程度不同、各應用場景要求的資料精確度不同、資料分析應用要求的反應敏捷度不同、各種資料來源間連結上的關係性不強或是不確定,資料對每個場景的價值與含金量不同,以及各資料本身的易用性也有落差。
辛兒倫表示,當今的資料分析領域,已經無法採用單一平臺,或是單一技術,來有效處理這些大數據分析需求。因此,如何有效解決資料之間求同存異的共同需求,建立資料管理體系及架構,整合統一管理資料,提升使用者滿意度,成為所有企業皆可能面臨的最大課題。
戰略二 瞄準IoT資料分析市場
另外一項新戰略,則是瞄準IoT發展趨勢,設立新的全球IoT資料分析部門(Global IoT Analytics Unit)。Teradata去年開始組織重整,陸續退出行銷應用業務領域,可見Teradata不僅將重心擺回資料分析本業,更計畫搶進物聯網的資料分析市場,並往雲端化邁進。
Teradata全球技術長Stephen Brobst表示,大數據以前聚焦B2C如零售產業,但是現在的物聯網更多是B2B模式,而過去Teradata客戶以金融、電信產業為最大宗,現在將擴展至更多製造業,以及任何具有大量IoT資料分析需求的產業。全球IoT分析部門隸屬於Teradata實驗室之下,該開發部門由資料科學家、資料工程師及軟體設計師所組成,將專注開發IoT應用領域的創新資料分析服務,並打造新雲端化的資料分析解決方案。
Stephen Brobst也表示,成立全球IoT分析部門是為協助企業更容易移轉如感測器所產生的大量資料,以因應IoT資料流,並藉由優化資料管理系統,進行即時的大數據進階分析,提供可用來分析IoT資料的工具與技術,希望幫助企業簡化IoT資料的進階分析、資料搬移與資料庫管理流程。
全球IoT分析部門主要負責幾件事情,包括基於Teradata資料分析平臺Aster Analytics 6.21版本開發新的開發工具包Teradata Aster Scoring SDK,可在運行環境中執行建立於Aster資料庫中的分析模組,Aster Scoring SDK能協助分析師快速部署 Aster的IoT分析模組,並讓開發者建立複雜分析模組,可實際部署於任何IoT先進伺服器、公有雲環境或是資料中心。
此外,也將負責拓展基於Kafka開源專案的產品Teradata Listener ,Teradata Listener 可用來追蹤多個感測器與IoT資料串流,並將這些資料廣播到整個分析生態圈中的多個平臺上進行資料處理流程。接下來,新成立的全球IoT分析部門也將在系統管理及DevOps 任務中,結合新的機器學習與進階分析技術,藉由在Teradata 系統上採用機器學習技術,快速解決系統中所產生的複雜績效與工作量擁塞問題(Workload Congestion Problems)。
戰略三 延伸支援混合雲架構
在雲端布局方面,Teradata要將旗下資料倉儲產品線進一步延伸至創新的混合雲平臺上提供,讓企業的跨平臺系統之間具有更大的彈性與整合性。
新發表的Teradata混合雲服務,可協助企業打造跨本地部署、代管雲及公有雲端環境的混合雲架構,並提供簡單好用的功能讓企業進行資源調度,如自動化同步(Automatic Synchronization)、優化查詢路由(Optimized Query Routing),以及跨生態系統之間的端對端管理。
除此之外,Teradata也推出可進行大規模平行運算架構Teradata IntelliFlex,以及支援AWS雲端平臺環境的Teradata資料庫,而既有的Teradata代管雲也預計在今年下半年擴展至歐洲市場。
其中,Teradata IntelliFlex是新一代的大規模平行處理架構(Massively Parallel Processing,MPP),以光纖架構為基礎提供多維度擴充性,企業可依據當前的業務需求轉變,自行提升處理能力,或是擴充儲存容量。Teradata IntelliFlex也提供了大容量的記憶體資源配置,可進行高效能的記憶體式運算(In-memory),並適用於企業資料中心裡的高密度機櫃空間。Teradata表示,IntelliFlex的記憶體容量是現有Teradata資料倉儲產品的3倍,效能上也有顯著提升。
而Teradata資料庫也正式支援AWS平臺,整合了Teradata資料庫軟體生態圈中的進階分析能力,並提供多項自助式服務,可快速方便的透過單鍵來訂閱,提供以年計價和以小時計價選擇,Teradata表示,未來幾個月也預計要支援其他公有雲平臺。
延遲綁定與支援JSON、非結構化資料是現今的關鍵資料處理方法
除了祭出3項新戰略之外,Stephen Brobst在大會上也分享了現今資料分析的關鍵作法與技術,包括採用延遲綁定(Late Binding)的資料處理模式,及支援JSON(JavaScript Object Notation)語法及非結構化資料,其中,延遲綁定技術與以前的作法不同,不會在取得資料時便定義資料結構(Schema),而是在要使用資料時,也就是需要查詢、讀取時才建立資料結構,以保留其資料應用的靈活性,而Teradata的做法便是將JSON當作資料庫第一層,當要讀取資料時再決定資料的結構。
他表示,如Teradata推出的QueryGrid技術,可無縫查詢多個異質資料庫,採用QueryGrid的UDA架構中,可以包含如儲存客戶資料的Teradata 6800、紀錄Session路徑的Aster平臺、Hadoop叢集中的非結構化文件、R伺服器網格(R Server Grid),及用來記錄點擊流量的Teradata 1700等,Teradata透過這樣可串連多種資料來源的統一架構,並整合許多既有的軟硬體,來協助企業打造資料分析生態系統。
Stephen Brobst將企業進行資料探索的流程分為蒐集(Capture)、梳理(Curation)及分析(Analysis)三大部分,其中蒐集包括從內、外部將資料採集至儲存平臺中,供資料工程師或資料科學家來存取使用,在梳理方面,企業需找到適當的資料結構,來對應不同的資料儲存體,建立可描述資料儲存模式與欄位的中介資料,並對多個儲存體進行整合以進行週期性管理。最後分析部分,才是找出資料之間的關聯性以及可進行分析預測的模式。
而他認為,現在企業最大的問題是,在資料梳理這部分做的不夠好,且多數企業不願意去正視這個問題,因此,儘管許多企業都已經建立資料湖(Data Lake),把大量資料透過低成本的方式存到同一個地方,但是卻沒有讓資料湖中的資料發揮最大價值。
Stephen Brobst指出一項Gartner在2015年揭露的調查與預測數據,到2018年時,全球將有高達9成的資料湖會失去價值,這些已部署的資料湖將充滿過多因不確定性案例而採集的資料資產不堪負荷。Stephen Brobst表示,企業使用資料湖的方式是錯的,且不應該用資料湖的規模大小來衡量成功,此外,很多時候,企業會將重複的資料丟到資料湖中,卻未對這些資料加以管理或有效應用,或是對於已經放進資料湖中的資料不夠了解,若是如此,即使存放了再多資料,最終只會成為無用的資料沼澤(Data Swamps)。
他認為,最容易被忽略的事情是不斷去追蹤這些內、外部資料的來源(Provenance),此外,也缺乏對資料與資料來源的關聯性,導致對資料品質不信任,而產生資料重複複製,或是重複操作的狀況,資源利用效率低。而要掌握資料來源,得知道誰在什麼時候建立了這筆資料資產、建立這項資產的原始數據來源為何、建立該資料資產使用了哪些處理流程、這些資料資產已知的缺陷為何,以及所使用的演算法等。
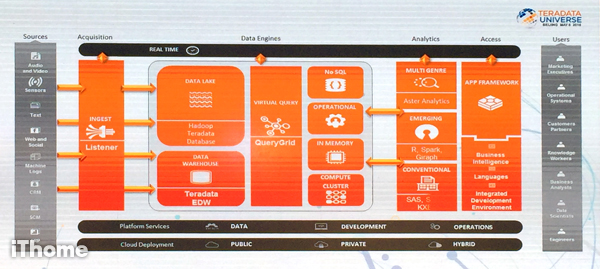
Teradata大中華區首席執行長辛兒倫表示,目前Teradata主要產品還包括基於開源Kafka專案的產品Teradata Listener、可以無縫查詢多個異質資料庫的QueryGrid平臺、Aster圖像式的資料挖掘探索平臺,此外,在資料分析層,也支援R、Spark,Giraph等,並支援多項BI存取工具如Tableau。
熱門新聞

2026-03-06



2026-03-06

2026-03-09


2026-03-09

2026-03-09