
全球頂尖企業的研究人員和資料科學家團隊,都致力於創造需要被訓練且更複雜的人工智慧模型,而且他們動作還得快。
這就是為什麼想要在人工智慧領域坐穩領導地位,先得在人工智慧基礎設施取得領先地位,而這也正解釋了日前發佈的 MLPerf 人工智慧訓練成果會如此重要的原因。
NVIDIA 達成 MLPerf 六項基準測試的耀眼成績,展現出世界級的卓越效能表現和多功能性。NVIDIA 的人工智慧平台在訓練效能方面創下八項記錄,其中包括三項大規模整體效能紀錄及五項基於每個加速器的效能紀錄。
|
紀錄類別 |
基準測試 |
紀錄 |
|---|---|---|
|
最大規模 |
物體偵測 (高複雜度) - Mask R-CNN |
18.47 分鐘 |
|
翻譯 (Recurrent) - GNMT |
1.8 分鐘 |
|
|
強化學習 – MiniGo |
13.57 分鐘 |
|
|
每個加速器 |
物體偵測 (高複雜度) - Mask R-CNN |
25.39 小時 |
|
物體偵測 (低複雜度) - SSD |
3.04 小時 |
|
|
翻譯 (Recurrent) - GNMT |
2.63 小時 |
|
|
翻譯 (Non-recurrent) - Transformer |
2.61 小時 |
|
|
強化學習 - MiniGo |
3.65 小時 |
表1:NVIDIA MLPerf 人工智慧紀錄
每個加速器的比較結果取自於先前提出之單一 NVIDIA DGX-2H (16個 V100 GPU) 與其它同規模相比較的 MLPerf 0.6 的效能 (除 MiniGo 採用的是搭載8個 V100 GPU 的 NVIDIA DGX-1) 最大規模 | MLPerf ID Max Scale: Mask R-CNN: 0.6-23,GNMT: 0.6-26,MiniGo: 0.6-11 | 每個加速器 MLPerf ID: Mask R-CNN,SSD,GNMT,Transformer:皆使用 0.6-20,MiniGo: 0.6-10
Google、Intel、百度、NVIDIA及創造 MLPerf 人工智慧基準測試套件的數十間頂尖科技公司和大學支持著這些測試結果數據,並將其轉化為具有重要創新意義的內容。
簡單來說,過去要花上一整個工作天才能完成訓練的人工智慧模型,NVIDIA 的人工智慧平台如今只要不到兩分鐘的時間便能完成。
企業明白要釋放這種生產力才是致勝關鍵。超級電腦現在儼然成為人工智慧領域的重要工具,而想要在人工智慧領域站上領導地位,需要有強大人工智慧運算基礎設施的支持。
我們最新的 MLPerf 測試結果充分展現出將 NVIDIA V100 Tensor Core GPU 用在超級運算等級基礎設施所能帶來的優點。
2017年春季,搭載 V100 GPU 的 NVIDIA DGX-1 系統花了一整個工作天,也就是八個小時來訓練影像辨識模型 ResNet-50。
如今同樣搭載 V100 GPU 的 NVIDIA DGX SuperPOD 與 Mellanox InfiniBand 進行串連,再使用經 NVIDIA 優化後用於分散式人工智慧訓練的最新人工智慧軟體,只用了 80 秒便完成了訓練影像辨識模型 ResNet-50 任務。這比煮一杯咖啡的時間還要短。
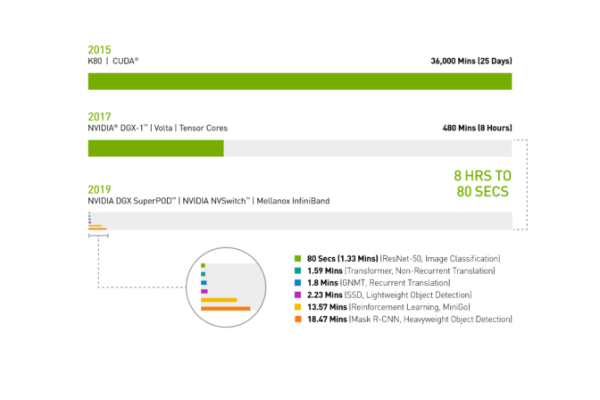
圖 1:AI 的時光機
2019 MLPerf ID (圖中從上到下):ResNet-50: 0.6-30 | Transformer: 0.6-28 | GNMT: 0.6-14 | SSD: 0.6-27 | MiniGo: 0.6-11 | Mask R-CNN: 0.6-23
人工智慧的基本工具:DGX SuperPOD 可以更快完成工作負載
仔細觀看今日的 MLPerf 結果,顯示出 NVIDIA DGX SuperPOD 是唯一一個以不到 20分鐘便完成 MLPerf 六項測試的人工智慧平台:
.png)
圖 2:DGX SuperPOD 打破大規模人工智慧紀錄 大規模 MLPerf 0.6 效能 | 大規模 MLPerf ID: RN50 v1.5: 0.6-30, 0.6-6 | Transformer: 0.6-28, 0.6-6 | GNM: 0.6-26,0.6-5 | SSD: 0.6-27,0.6-6 | MiniGo: 0.6-11,0.6-7 | Mask R-CNN: 0.6-23,0.6-3
更進一步觀察便會發現,在高複雜度物體偵測及強化學習這兩項最困難的人工智慧問題上,NVIDIA 人工智慧平台於總訓練時間方面脫穎而出。
使用 Mask R-CNN 深度神經網路進行高複雜度物體偵測,可為使用者提供進階的實例分割。其用途包括將其與攝影機、感應器、超音波等多個資料來源搭配使用,以精確辨識並對特定物體進行定位。
這類人工智慧工作負載有助於訓練自動駕駛車,對行人及其它物體進行精確定位。另一個實際用途,便是協助醫師在醫療掃描影像中找尋和辨識腫瘤,其意義非凡。
NVIDIA 花不到 19 分鐘便完成了高複雜度物體偵測測試,效能幾乎是第二名的兩倍。
強化學習同屬不易處理的高難度類別,這種人工智慧方法可以用於訓練工廠車間的機器人,以簡化生產流程;在市區也能用它來控制紅綠燈,以舒緩塞車情況。NVIDIA 使用 NVIDIA DGX SuperPOD,在破紀錄的 13.57 分鐘內便完成對 MiniGo AI 強化訓練模型的訓練。
咖啡還沒好,任務便完成:即時人工智慧基礎設施提供領先全球的效能表現
打破基準測試紀錄並非我們的目標,加速推動創新才是。這正是 NVIDIA 為什麼打造出功能強大且易於設定的DGX SuperPOD。
使用者可以從 NGC 容器 registry 免費下載已完成優化的 CUDA-X AI 軟體,對 DGX SuperPOD 進行全面設定,便能立即享受到領先全球的人工智慧效能。
NVIDIA 與生態系中超過130萬名的 CUDA 開發者合作,致力於支援各種人工智慧框架及開發環境。
我們已經協助優化了數百萬行程式碼,無論是在雲端、資料中心或是網路邊緣,只要在能找到 NVIDIA GPU 的地方,我們的客戶便能夠部署其人工智慧專案。
人工智慧基礎設施現在已經夠快,未來還會更快
更棒的一點在於這個平台的速度還在不斷提升。NVIDIA 每個月都會發佈 CUDA-X AI 軟體最新的優化及效能增進內容,加上可以從 NGC 容器 registry 免費下載整合軟體堆疊,其中包括容器化的框架、預先訓練好的模型和腳本。
拜 CUDA-X AI 軟體堆疊的創新內容所賜,NVIDIA DGX-2H 伺服器的 MLPerf 0.6 處理量較我們七個月前發佈的結果提升了 80%。
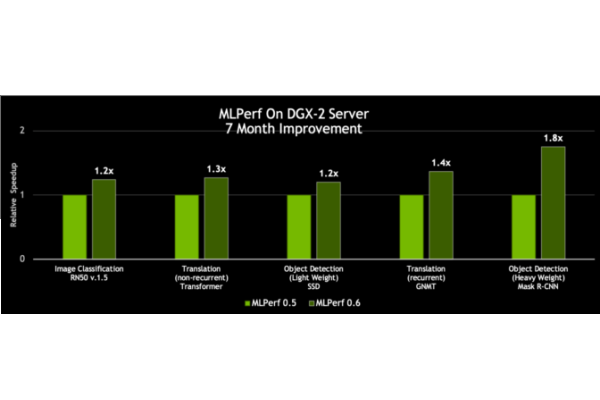
圖 3:與同一時期單一 DGX-2H 伺服器的處理量相比,同一伺服器的效能提升達 80% (資料集單次通過神經網路) | MLPerf ID 0.5/0.6 比較:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
這些成果加總起來,背後代表著數百億美元的投資和心力,這一切都是為了讓你能夠在今日快速完成工作,以及未來在更短的時間內完成工作。
在 NVIDIA 開發者部落格中有更深入介紹這些效能測試結果。請一併參考此資訊圖表。
從八小時到八十秒:NVIDIA 大幅縮短訓練人工智慧的時間,NVIDIA為唯一在六個類別裡皆表現卓越的公司
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06


2026-02-10