中國阿里巴巴的數據技術及產品部副總裁,同時也是暢銷書<<決戰大數據>>作者車品覺今天來臺在第二屆資料科學愛好者年會演講。他表示,本身是虔誠的資料信仰者,喜歡用資料做決策,像是他會比對阿里巴巴面試官給面試者的評語以及考績,找出不適任的面試官,抑或是分析Linkedin上的資料,找出不常更新履歷卻深藏不露的潛在人才。車品覺以8年時間打滾於資料界的經驗,發展了資料十誡,現在已到了4.0版本。
一切從定義「問題」開始,已知到未知的過程
「不是每一個問題都是資料的問題,不是每一個問題都是大資料的問題」車品覺說,要知道問題是否能靠資料解決,必須先思考5件事定義需要解決的問題,這是什麼問題?誰的問題?這問題你來解決嗎?需要現在解決嗎?資料能解決嗎?當這5個問題的答案皆為是,那或許就是當下可以靠資料解決的問題。中國現在每個城市都極力朝向智慧城市發展,但是對於城市來說,怎麼樣才是智慧,他說,如果沒有定義智慧,那就不知道做出來的應用該如何衡量成效,「定義問題是從知道到不知道的過程。」
思考問題時,不能把沒有資料當作藉口,因為現在可以取得資料的方式太多了。車品覺舉例,調查研討會的品質當可以用最傳統的問卷,也可以在場內跟場外架設手機探測器掃描會眾手機ID,便能記錄會眾進出場內外的狀況,進一步分析演講品質。另外,如果想改善滴滴打車計程車服務品質,降低司機拒載的機率,那在當司機拒載的時候,提供客戶評價的機制,而這也是取得解決問題的一種資料來源。「只要問題定義好,需要的資料都存在,思考應該凌駕在資料技術之上,思考方法才是產生價值最重要的一點。」
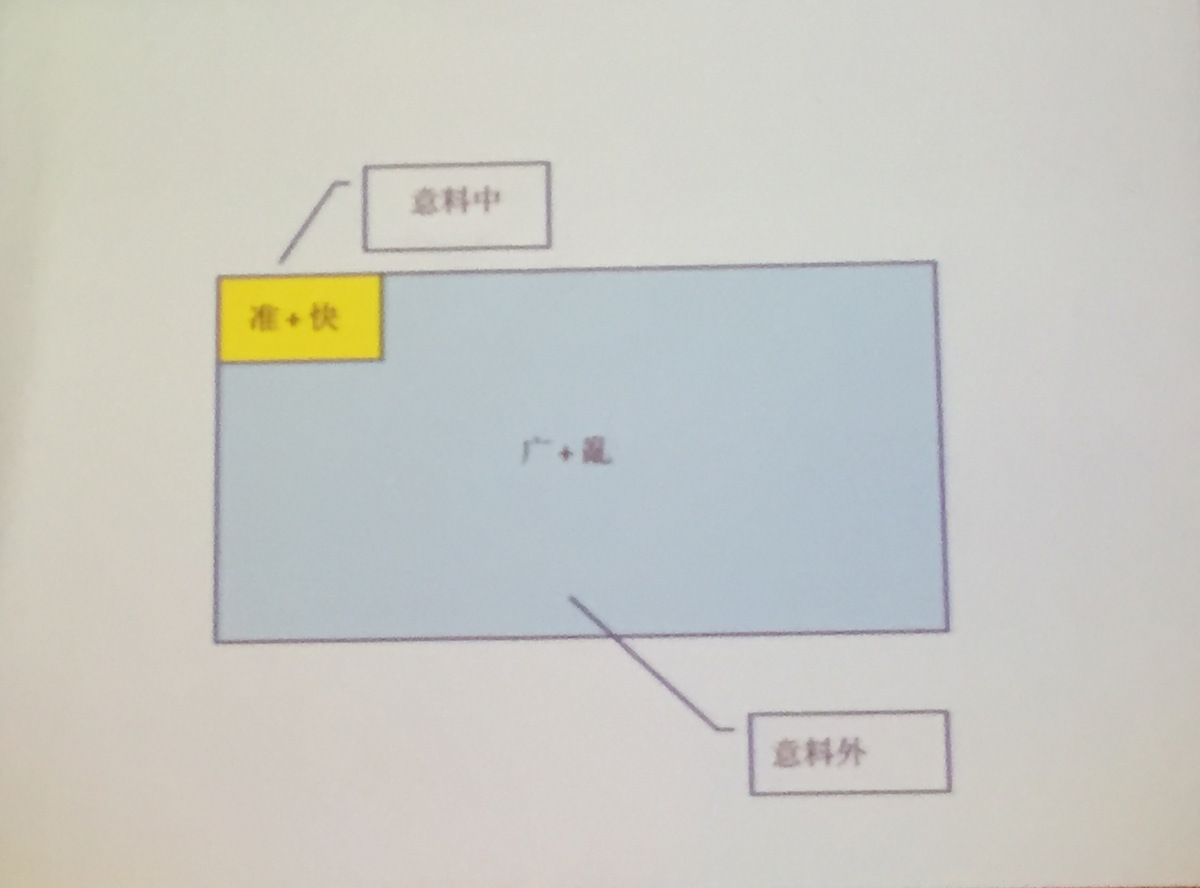
而資料來源非常多,車品覺將資料分為四個象限,以能否預料以及意見的正反向作為X與Y軸。他認為,其實企業要用資料解決的問題都圍繞著商業公式(Business Equation ),思考產生更多商業價值的方法,像是怎麼用更低的成本招攬更多的客戶?如何留住客戶?怎麼定價?不少企業用問卷的方式,意圖更了解客戶的想法,但往往蒐集的資料有所偏頗。
中國阿里巴巴的數據技術及產品部副總裁車品覺將資料分為四個象限,以能否預料以及意見的正反向作為X與Y軸,用以思考企業收集資料的完備性。

他舉例,客人來吃了什麼餐點,這是一個預料中的正向記錄(Expect Positive),而預料中但反向(Expect Negative)的例子則是客人沒吃完餐點的紀錄,另一個電子商務例子則是,當有人到周大福買珠寶,記錄了客戶買了哪一個商品,這就是Expect Positive的紀錄,而調查客戶看了哪5個商品才買到了想要的戒指,則是Expect Negative,車品覺說,Expect Negative對於機器學習是重要的訓練樣本。
而預料之外的意見,則是大資料價值的機會所在,車品覺認為,大部份人思考方法都是演繹法形式,從已知推論未知,但是運用大資料技術可以逆轉這個程序。他以行銷作為例子,過去一項產品的行銷,企業會主動設定目標客群,或許是三十幾歲的女性等,針對這群人投放廣告,但是現在的方法,可以透過歷史的銷售資料,找出購買行為的特徵,逆向圈出目標客群。
資料科學處理資料有2個派別,其一是用龐大的模型和複雜的演算法分析資料,另一種用簡單的演算法,但是分析大量或是過去沒有蒐集過的資料,車品覺傾向後者,他認為,因為複雜的演算法,發生問題的機率也比較高,使用複雜演算法預測出來的結果,要仔細檢視預測對與錯的機率,以及其結果的穩定性,往往壽命只有6個月,之後又要開始一項新的專案解決同一個問題。
讓資料去助力描述、診斷、預測以及行動建議
資料在不同周期上能提供的價值也不同,以天為周期的資料可以描述狀況,而1周需要知道的則是,上星期做的決策是正確還是錯誤的,1個月就必須了解競爭對手的策略與狀態,1季就需要檢討組織是否達到設定的KPI。車品覺從以前必須求老闆看看他做的資料,到現在老闆會挑惕他準備的資料沒有用,他認為,這是企業利用資料進化的結果,他發現美國許多企業不只擁有資料科學家,現在還多了決策科學家,負責用資料替公司做決定。
「阿里巴巴使用資料最大的分水嶺在於從看到用」,車品覺前些日子在做的工作,正是把一整個部門淘汰改為完全自動化,他說,在那個時候他領悟到,資料的目的直接影響對資料品質的要求,因為僅用於觀察還是實際使用,所需要的資料完全不同等級,他提到,像是無人機的控制,多個複雜模型交互作用下,必須依靠穩定充足的資料來源才能動作,而在這個找出可用資料來的過程,會發現底下有很多資料基本功沒扎穩。「當沒有資料就無法提供服務,那企業就走在對的道路上」,企業看待資料中斷應該要等同於IT系統錯誤一樣的嚴重,必須有人要受懲罰負責。
不只是自動化的服務,需要有非常完整的資料,在很多情境下,當沒有完整的資料提供全面的資訊,往往會把某些結果歸因於運氣,但其實是沒有被資料描述出來。像是在零售業中,顧客的購物的慾望可能起始於朋友推薦,經過了商品搜尋以及品牌官網收集資訊,顧客逛了電子商務網站,最後卻在大賣場購買,這樣的過程或許看似大賣場比較幸運最後成功銷售商品給這位顧客,但其實不然。
車品覺表示,企業要知道的了解的資訊太多了,要有區分顧客喜好等級是有興趣還是熱愛這類細節的能力,以運動高爾夫球來說,顧客有興趣頂多是看看比賽,但是熱愛的話,可能就會想要購買高爾夫球竿,但是如果推薦高爾夫球用品給只是有興趣的人,那等同於無用的廣告。他提到,有時候顧客的小資料,卻對結果影響超大,像是信用卡的還款時間,顧客因為要繳交信用卡的費用感到心痛,因此購物慾望下降,此時要顧客消費是困難重重,這雖然只是一項小資料,卻也是整個顧客購物鍊很重要的一環,他認為,企業應該檢視所蒐集的資料是否完整。
快加準的資料,能從已知規律產生價值
車品覺認為,多數人對使用資料有誤解,應該分為快加準以及廣加亂的資料。快加準的資料是那些公司很常在使用,能從已知的規律中產生價值,需要做的改善是加速資料更新的頻率,或是加速資料整合的速度,以支援更快速的做出決策,以前要3小時才拿得到資料,現在期望能進步到即時,所以很適合用Spark這類大資料即時串流的解決方案。快加準的資料,要思考的議題是「有沒有、準不準、細不細、全不全、穩不穩以及快不快。」
相對於快加準的資料是廣加亂,廣加亂的資料能從發現中顛覆已知,他認為,今天大資料絕大多數屬於廣加亂的資料,而這樣也才能發現意料之外的事情,因此從這些資料提煉出來的資訊也比較有明顯的價值,而Hadoop是適合用於這類應用的解決方案。
中國阿里巴巴的數據技術及產品部副總裁車品覺將企業的資料應用分為兩類,快加準以及廣加亂,而廣加亂的資料正是大資料的特性,從廣加亂資料提煉出來的資訊比較有明顯的價值。
資料從布點/收集、儲存/刷新、辨識/關聯、挖掘/決策以及行動/反饋形成一個循環,車品覺認為,值得注意的是資料的刷新,像是有位顧客到北京旅行,如果企業立刻把顧客的居住地資料更新為北京就不太適當,他說,有時候反而要推延資料更新的時間。
另外,他認為辨識也是很重要的細節,以銀行來說,很多時候帳戶名字是先生的,但是因為妻管嚴,所以幾乎多為太太代為處理帳務問題,銀行應該有能力辨識帳戶性別是女性,甚至有能力知道這個帳戶有兩個行為ID,女生占70%男生占30%。
也因為大資料多為廣加亂的資料,因此車品覺認為,大資料不能只是獨奏,而是不斷連接無處不在的資料,各個產業共同分享的資料,能激發出更有價值的資訊,而資料生態系的連接,必須建立標準與規範。他分享企業跨組織共享資料的經驗,他說,必須先要串連意願強烈的合作夥伴,制定溝通的協定,進一步是設立公共資料資料槽,促使多方資料交換共享,車品覺說,阿里巴巴走得更前一步,他們已將資料資產化。
而當企業認為,大資料技術就是加速和累積資料、分析、服務的能力時,正是朝向成功大資料公司的路上,車品覺直言「大資料是一種能力,企業要有愛因斯坦的大腦以及健壯的身體」,大資料能力組成的因素有思想、血液以及骨骼,思想就是資料運算邏輯或模型等,血液則是資料,而骨骼是基礎的硬體設備。
中國阿里巴巴的數據技術及產品部副總裁車品覺認為,大資料是一種能力,企業要有愛因斯坦的大腦以及健壯的身體

最後,他說大資料其實就是許多小資料的組成,或許不久後大資料這個詞就會消失,但是資料是一種信仰,用資料解決問題的精神會永遠存在。
熱門新聞

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23

2026-02-23