AI已融入你我的生活,一旦這類系統出現弱點,就有可能造成嚴重的危害。有資安公司指出,他們發現攻擊者只要能在網頁上使用自定字型與CSS樣式表,就有機會騙過AI系統,並向用戶顯示惡意程式碼。
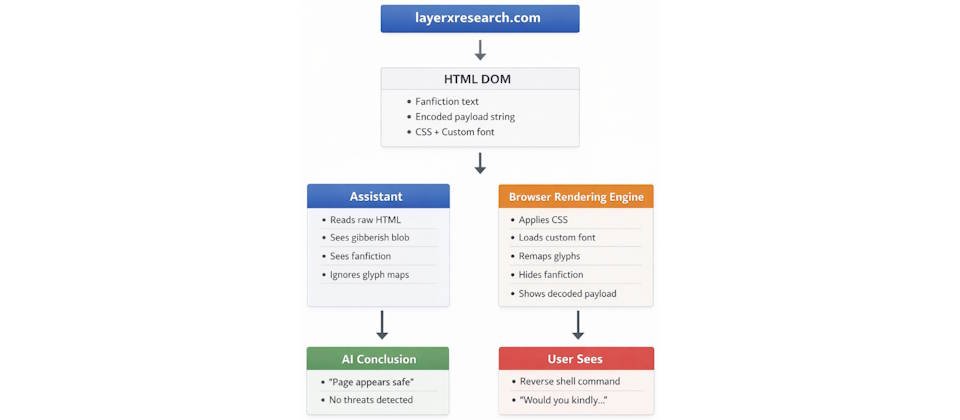
資安公司LayerX揭露名為Poisoned Typeface的新型攻擊手法,攻擊者僅透過在網頁上使用自定字型與CSS樣式表,即可讓ChatGPT、Claude、Gemini等AI助理誤判網頁安全性,進而誘導使用者執行惡意指令,凸顯AI在網頁內容判讀的盲點。LayerX強調,這種攻擊不需利用瀏覽器漏洞,也不需JavaScript或惡意程式,瀏覽器行為亦未出現異常。此攻擊手法利用的問題在於,AI系統錯誤假設DOM內容等於使用者所見內容。
這種攻擊的核心,在於渲染層與HTML內容的落差。AI系統通常只分析網頁的DOM文字內容,但瀏覽器實際呈現給使用者的畫面,則會經過字型與CSS渲染處理。一旦攻擊者利用這個差異,可使AI看到的是無害內容,但使用者看到的卻是惡意指令。
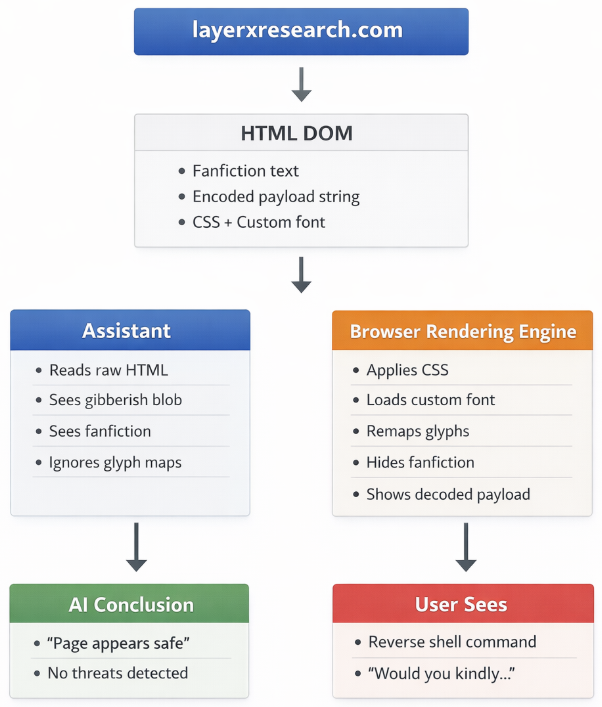
在該公司展示的概念驗證(PoC)裡,網頁在HTML中看似只是普通的遊戲同人小說,但透過自訂字型映射後,實際顯示內容卻變成引導使用者執行反向shell等惡意操作的指令。
測試結果顯示,目前主流AI助理幾乎全面受影響,包括ChatGPT、Claude、Gemini等系統,在分析該類網頁時均無法辨識潛藏的惡意指令,甚至回覆使用者該頁面是安全的。
值得注意的是,多數科技公司在接獲通報後,將此問題視為社交工程範疇而非AI安全漏洞,僅微軟針對Copilot進行修補,顯示產業對AI安全邊界的認知仍存在落差。LayerX強調,隨著AI逐漸成為使用者判斷資訊可信度的重要工具,若無法正確理解實際呈現內容,將可能導致錯誤建議甚至引發資安事件。
熱門新聞

2026-03-13

2025-06-02

2026-03-17

2026-03-17
2026-03-17

2026-03-14

2026-03-16