
在這個架構中,每家醫院參與者都是一個Worker,必須主動向中央Server表明要加入哪些任務,Server端收到請求後,才會進行任務分派。
攝影/王若樸
衛福部資訊處於1月28日正式啟動高算力中心暨跨國聯邦學習平臺,並同步揭露國家級聯邦學習驗證機制。三軍總醫院數位醫療中心人工智慧核心實驗室主任林嶔指出,國家級聯邦學習平臺的目的,不只是兼顧醫療資料隱私,也能提升AI模型的泛化能力、更通用,還讓參與醫院能在相同標準與環境下共同訓練模型。
這套平臺以Nvidia開源聯邦學習平臺NVFLARE為基礎,參與單位主要需完成兩個步驟:一次性配置與驗證,以及準備訓練腳本(Script)。目前,衛福部已指定16家醫院加入聯邦學習平臺,其中三軍總醫院已有2項專案正在進行中。
為何需要聯邦學習?
林嶔首先強調,對醫療AI而言,外部驗證(External validation)至關重要。
因為,一個在A醫院訓練完成、表現良好的醫療AI模型,實際部署到其他醫院後,準確度往往會下降,背後原因主要來自三種偏移。
第一是資料領域偏移(Data domain shift),例如不同醫院使用的影像設備廠牌、掃描參數或影像品質不同,都會影響AI對影像的判讀結果。
第二是族群偏移(Population shift),各醫院病人的年齡結構、共病比例與疾病盛行率不盡相同,也會影響模型表現。
第三則是工作流程偏移(Workflow shift),包括醫師開立醫囑的習慣不同、臨床流程不同,甚至有些醫院未必具備特定欄位,導致 AI 接收到的資料結構與使用時機改變,進而影響準確度。
他也補充,美國食品藥物管理局(FDA)已在2025年1月7日提出指引草案,指出AI臨床驗證至少需要來自三個不同地理區域的美國臨床場域資料,目的正是避免模型過度擬合於單一醫療場景,提升通用性。
資料不出院,如何完成外部驗證?
相較之下,臺灣尚未提出類似的明確規範,但要實際完成跨院外部驗證,本身就不容易。林嶔指出,醫院高度重視醫療資料隱私與法規遵循,資料通常不會離開院內,更不可能無償提供給其他醫院,用來驗證AI模型。
為解決這個困境,衛福部看好聯邦學習(Federated Learning)。這項技術可在資料不出院的前提下,讓多家醫院各自使用院內資料同步訓練同一套AI模型,並僅交換經處理後的模型權重,來提升模型整體表現與泛化能力。
因此,衛福部推動國家級聯邦學習計畫,結合自建高算力中心、採用NVFLARE平臺,並指定16家醫院參與。
林嶔形容,建置國家級聯邦學習平臺,就像是「讓所有人開同一臺車」,不只統一開發環境,也使用相同的資料格式(如HL7 FHIR)、一致的系統版本與訓練流程,大幅降低跨院溝通與整合成本。
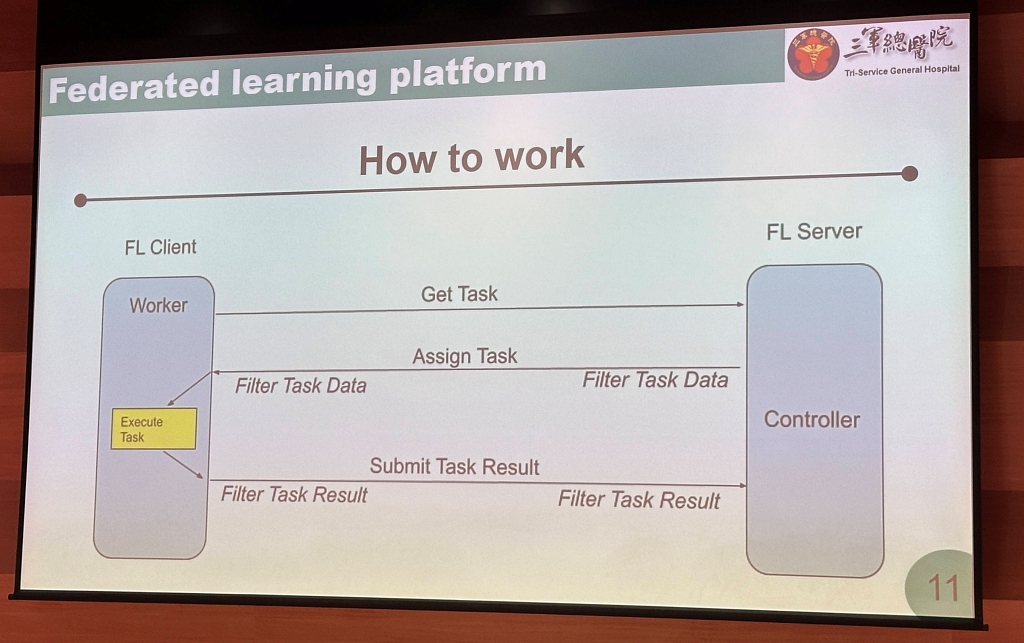
國家級聯邦學習平臺如何運作?
在技術架構上,聯邦學習平臺分為兩大端點:中央端的 FL Server(由衛福部負責),以及各醫院端的 FL Client。
流程上,中央Server會將初始模型發送給各醫院,各院在院內完成一輪模型訓練後,僅回傳經加密與差分隱私處理的模型權重。中央Server彙整後更新模型,再發送回各院,反覆進行多輪訓練,直到模型表現穩定為止。
林嶔說明,醫院加入聯邦學習平臺後,第一步是進行一次性配置(Provisioning),用來設定參與權限、安全連線、數位身分、治理與評估規則等。這項配置只需設定一次,後續所有聯邦學習專案皆可沿用。

完成配置後,醫院還需進行簡單驗證,確認連線是否正常。系統管理者也能查看其他加入聯邦學習的主機狀態,但並無權限進行操作。
第二步則是準備訓練腳本(Script)。林嶔指出,模型開發者需以電子郵件方式將腳本發送給各參與者,而非由衛福部Server直接下發。每一個聯邦學習專案都會被視為一個獨立的專案(Job),需要個別設定。

醫院也能依不同Job分配硬體資源,例如設定使用多少CPU或GPU,避免影響院內既有的日常運算工作。他特別提醒,每個任務在啟動前都需要重新設定(Re-set),確保訓練條件正確。
在這個架構中,每家醫院參與者都是一個Worker,必須主動向中央Server表明要加入哪些任務,Server端收到請求後,才會進行任務分派。醫院也可自行選擇是否參與特定Job,並非每個專案都必須加入。
資安、隱私與可稽核性設計
至於資料共享範圍,林嶔強調,只有經差分隱私處理後的模型權重與準確度會被分享,其餘資料全數留在醫院端。
尤其,NVFLARE的設計假設所有參與方皆不可信,因此內建嚴謹的身分驗證、加密與通訊安全機制,以確保各方資料安全。
此外,平臺也會完整記錄所有操作行為,每個任務皆有獨立ID與執行日誌,可滿足臺灣食藥署(TFDA)對智慧醫材的審查需求與當責要求。
聯邦學習平臺的兩項實例
最後,林嶔分享三軍總醫院目前進行中的兩項聯邦學習驗證專案。
第一項是以AI判讀胸部X光,評估民眾是否罹患肺結核。為滿足TFDA智慧醫材取證需求,團隊需明確定義肺結核與病人特徵(Patient characteristics),並列出聯邦學習所需的資料規格,包括DICOM胸部X光影像、影像報告、病人基本輪廓與特定ICD-10編碼的病史資料。

第二項專案則聚焦於乳房攝影,由AI判讀影像是否存在乳癌,同樣需要DICOM乳房攝影影像、乳攝報告、病人基本資料與病史。

林嶔也指出,在這些專案中,團隊發現既然已蒐集病人病史資料,其實也能進一步強化模型預測能力。實務上,僅透過ICD-10病史資料,就能對未來事件或疾病風險做出相當準確的預測。
他最後補充,雖然目前TFDA在智慧醫材取證上,尚未明確要求審查聯邦學習的運作紀錄,但由於國家級聯邦學習平臺能完整保存所有操作日誌,未來TFDA在評估AI模型時,或許可將這類日誌納入參考,作為下一階段產品審查的標竿。
熱門新聞

2026-02-02

2026-02-03

2026-02-02

2026-02-02

2026-02-03

2026-02-01