攝影/王若樸
衛福部昨(1/14)揭露FHIR一條龍轉換工具的最新進展,這套工具主打兩大核心能力:先潤飾病歷、把病歷內容寫清楚,再幫病歷「對好國際編碼」。經三家醫學中心、超過1.2萬份病歷的驗證下,整體編碼推薦準確率已達91.3%。
這項工具是衛福部次世代數位醫療平臺計畫的重要成果之一,下一步,團隊計畫導入AI代理(AI Agent),來讓錯誤回饋與修正流程更自動化。
為什麼要做FHIR一條龍工具?
時間拉回2024年8月,衛福部資訊處處長李建璋提出「次世代數位醫療平臺計畫」的新方向,希望臺灣醫療資訊系統(HIS)能逐步接軌國際標準,達成三個目標:
第一,資料格式要統一。也就是導入國際醫療資料標準FHIR,讓電子病歷內容不再各寫各的。
第二,規則要統一。透過臨床品質語言CQL(Clinical Quality Language)建立規則圖書館(Rule Library),把健保申報與醫療品質規則寫成可重複使用的邏輯,提高醫療品質和行政效率。
第三,應用程式要統一,導入國際SMART on FHIR應用程式標準,作為HIS與行動醫療應用程式的共同標準,未來才能發展智慧醫療應用市集,促進智慧醫療生態發展。
為了落實這三個方向,衛福部也採取「分級推動」策略。針對基層衛生所,資訊處將與工研院和協力廠商,開發公版電子病歷系統;針對區域與地區醫院,則要建置臺灣HIS共用數位底盤PAUL,來協助升級電子病歷系統,同時保留客製彈性。
至於醫學中心,重點並非全面汰換HIS,而是建置FHIR資料中臺,讓既有病歷能被轉譯、交換。
要做到這一點,第一步就是把現有病歷,轉成符合國際標準的編碼,包括用於檢查檢驗的LOINC、用於臨床描述的SNOMED CT,以及用於藥品描述的RxNorm等三大編碼。轉換好的資料,才會以FHIR格式檔案,上傳到FHIR資料伺服器,在國家電子病歷資料中臺交換。
於是,衛福部委由工研院開發一套FHIR一條龍轉換工具,來解決醫學中心最頭痛的編碼轉換問題。
FHIR一條龍工具瞄準潤飾和編碼推薦2大功能
開發該工具的核心成員、工研院資通所技術副組長游家鑫解釋,衛福部推動醫院導入3大國際編碼,是因為現行的ICD-10國際疾病分類代碼的語義顆粒度太粗,不利於後續資料分析及延伸應用。導入這些國際編碼後,則有助於機器閱讀和各項AI應用。
因此,團隊自2024年底,開始設計這套以大型語言模型(LLM)為核心的轉換工具,並聚焦兩大階段功能。首先是潤飾和優化病歷,比如針對病歷常見的縮寫(如HNT, DM, c/o chest pain),擴寫成完整、可被機器理解的句子,例如The patient, with a history of hypertension and diabetes mellitus, complains of chest pain.
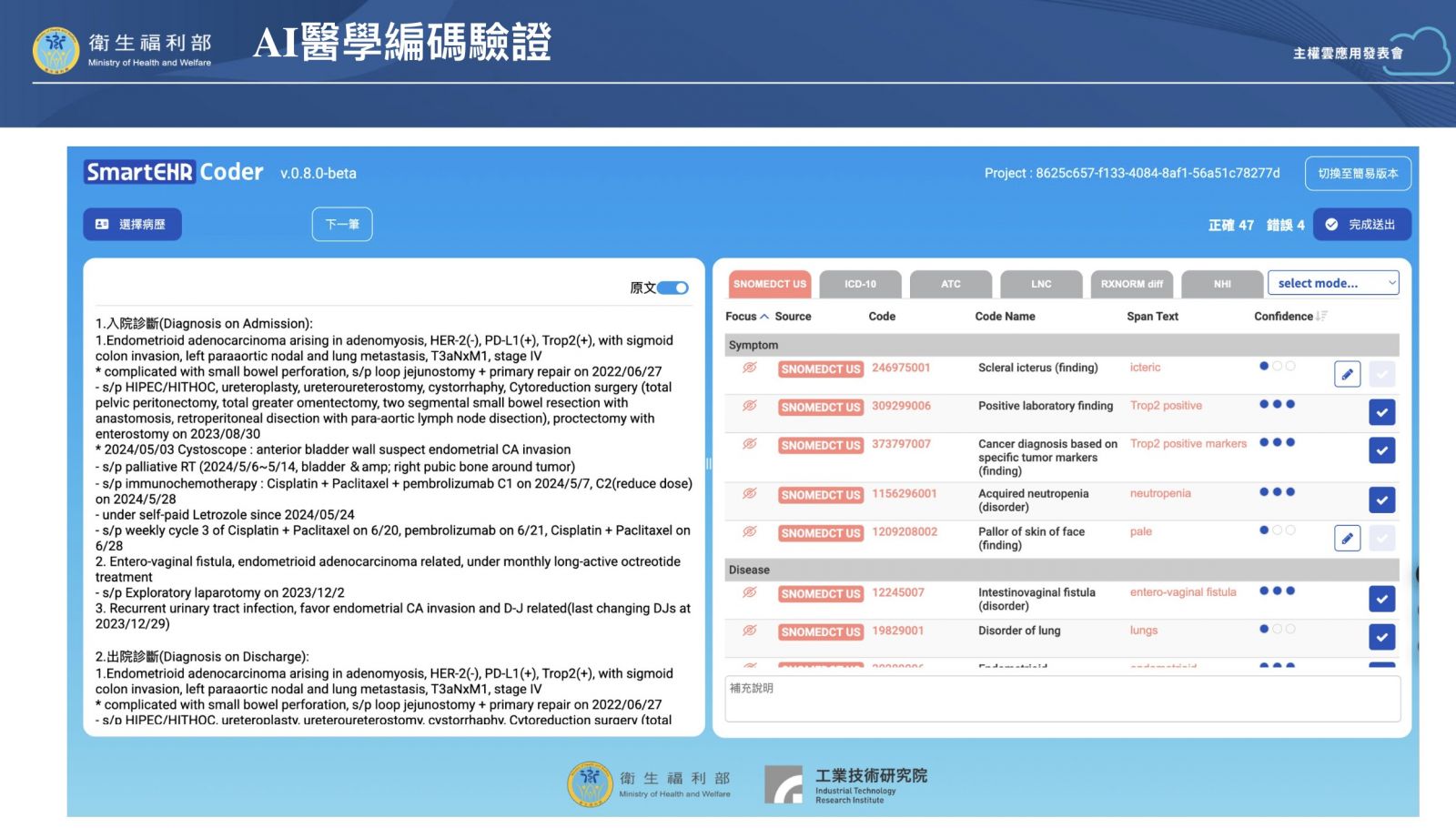
接著,系統會根據潤飾後的病歷內容,自動推薦對應的SNOMED CT、LOINC與RxNorm編碼。(如下圖)

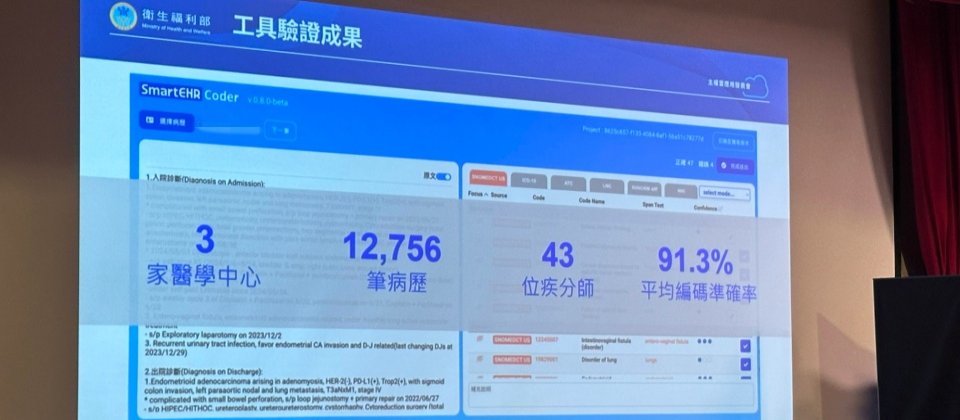
為驗證FHIR一條龍工具的實際可用性,衛福部資訊處和工研院聯手3家醫學中心(臺北馬偕、林口長庚、中山附醫)進行測試。他們共使用12,756份病歷,並由43名疾病分類師逐筆驗證工具推薦的編碼是否正確。結果顯示,整體準確率已達 91.3%。
圖說:左側為病歷內容,右側為系統推薦的編碼結果,疾分師可逐筆勾選是否正確。
下一步將導入AI代理,來讓除錯回饋更自動化
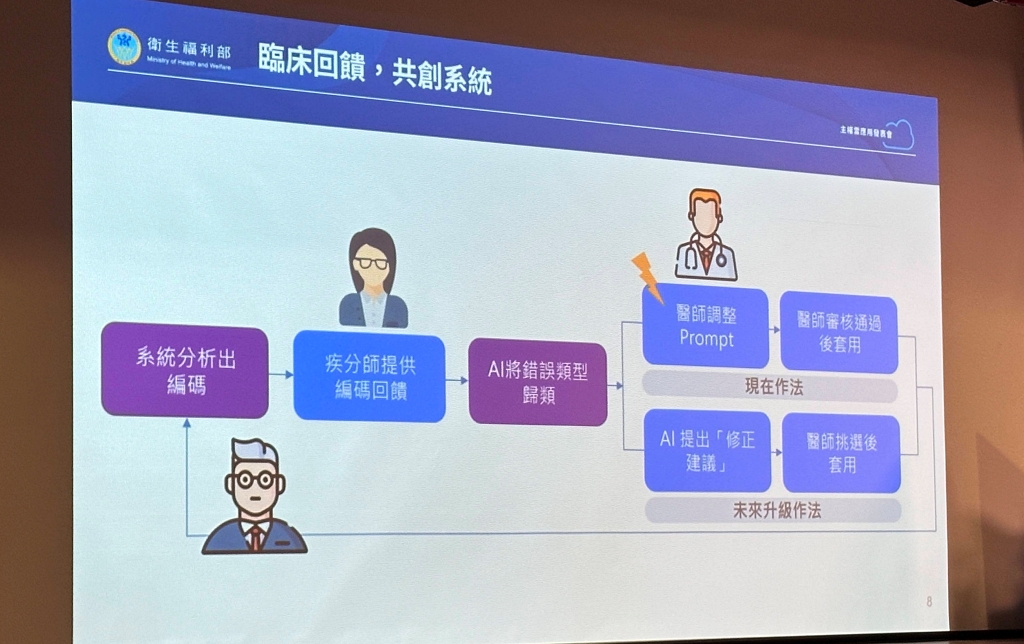
目前的除錯流程,仍以人工回饋為主。游家鑫說明,當系統給出推薦編碼後,會由疾病分類師判斷是否正確,並標註錯誤類型,例如「SNOMED CT編碼階層不夠細」或「出現不存在的編碼」,再由工研院調整提示(Prompt),經醫師確認後更新套用。
接下來,團隊希望導入AI代理,讓系統學習這些「錯誤歸類邏輯」。如此,AI就能先提出修正建議,再由醫師快速挑選、確認即可,大幅降低人工調整的負擔。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02