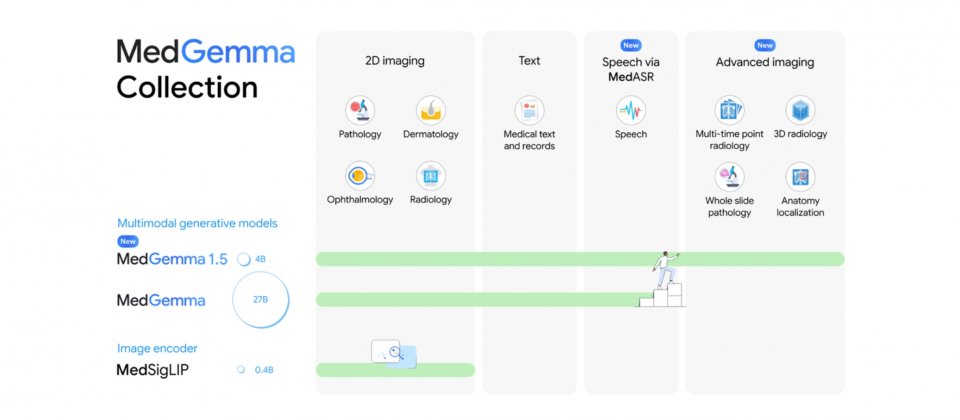
Google更新開放權重醫療生成式AI模型MedGemma至1.5版,強化醫療影像解讀與醫療文字任務的基準能力,並同步釋出醫療語音轉文字模型MedASR,滿足醫療聽寫與臨床口述的轉錄需求,讓開發者能把語音內容轉成文字後,銜接資訊整理或推理。
MedGemma為開發起點而非可直接上線的成品系統,Google提醒,模型輸出不應直接用於臨床診斷或治療決策,落地前仍需依各自場域完成驗證與調校。
Google此次先釋出MedGemma 1.5的4B多模態版本,主打較省算力,作為評估與微調的起點,要是需要更複雜的文字型任務或更大模型容量,開發者仍可沿用MedGemma 1的27B版本,包含純文字與多模態兩種變體。相較前一代以2D影像為主,1.5版把支援範圍擴展到高維度影像,包含電腦斷層掃描CT、核磁共振MRI,以及更大尺度的病理影像,並可用多張切片或多個影像區塊搭配提示詞完成任務。
Google揭露部分內部基準結果。以疾病相關3D影像所見的分類任務為例,MedGemma 1.5 4B在CT的宏平均準確率由58.2%提升到61.1%,在MRI則由51.3%提升到64.7%。Google也指出,這些能力仍處早期,實務上通常需要以自家資料微調,才能在特定流程中取得更穩定的表現。
除高維度影像外,MedGemma 1.5也加強胸部X光的應用情境,例如在不同時間點影像之間進行前後比較,或對影像中的解剖位置做定位。另一個面向是醫療文件理解,例如從檢驗報告抽取結構化資料,方便後續統計分析或系統串接。Google雲端也針對MedGemma提供DICOMweb整合,釋出可接受DICOMweb連結的新容器與部署流程,讓應用能以連結方式在伺服器端讀取與前處理CT、MRI等影像,再交由模型推理,以降低傳輸負擔並貼近臨床系統整合需求。
一起釋出的還有MedASR模型,針對醫療詞彙與口述習慣微調的自動語音辨識模型。Google以通用語音辨識模型Whisper v3 Large作為對照,在一組胸部X光相關語音資料集中,Whisper v3 Large的詞錯率為12.5%,MedASR在搭配6-gram語言模型解碼時可降至5.2%。另在多個內部醫療聽寫資料集上,MedASR搭配6-gram語言模型的詞錯率約落在4.6%至6.9%,Whisper v3 Large則約25.3%至33.1%。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-02

2026-03-03