獨立模型評測機構Artificial Analysis更新智慧指標(Intelligence Index)至v4.0,調整評測組合,讓評測重心更貼近實務任務與可靠性行為。官方同時提醒,合成指標可用來比較模型,但仍有侷限,不必然能直接套用到每一個使用案例,並在方法論中強調評測應兼顧公平性與真實世界適用性。
Intelligence Index v4.0移除MMLU-Pro、AIME2025與LiveCodeBench等常見測試,改採新的評測組合,試圖重新拉開模型差距。
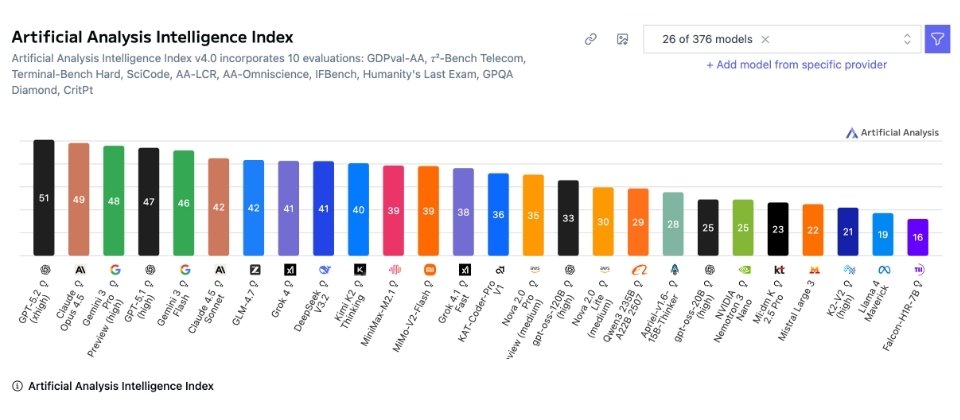
在Intelligence Index v4.0的前26個模型中,GPT-5.2(xhigh)以51分居首,Claude 4.5 Opus為49分,Gemini 3 Pro Preview(high)48分,GPT-5.1(high)47分,Gemini 3 Flash 46分。第二梯隊大致落在40分上下,包含Claude 4.5 Sonnet與GLM-4.7各42分,Grok 4與DeepSeek v3.2各41分,Kimi K2 Thinking 40分。其後分數逐步拉開,末段模型已降到20分以下,例如K2-V2(high)21分,Llama 4 Maverick 19分,Falcon-H1R-7B 16分。
v4.0受關注的新增項目之一是GDPval-AA,這是基於OpenAI提出的GDPval資料集,題目取自專業人士的真實工作產出,涵蓋44種職務與9大產業,用來觀察模型在具經濟價值的知識工作任務上能達到的程度。OpenAI也指出,這類任務能更清楚呈現模型是否真能支援日常工作,而不只是把題目答對。
AA-Omniscience以6,000題、涵蓋六大領域共42個主題的題庫衡量知識正確性與幻覺行為,並透過扣分機制懲罰亂猜,同時讓不回答維持中性分數,鼓勵模型在不確定時選擇不答。Artificial Analysis也指出,高正確率不必然代表低幻覺率,而且不同領域的領先模型不盡相同,選擇模型仍需貼近情境。
在科學推理面向,加入CritPt主打未公開的研究級物理推理挑戰,由50位以上在職研究者共同設計。Artificial Analysis公開的CritPt排行榜顯示,目前表現最佳的模型正確率也僅約一成出頭,例如GPT-5.2(xhigh)為11.6%,其餘多數知名模型皆落在個位數百分比甚至接近零,顯示模型要運用長鏈推理獲得可驗證的最終答案,仍有一段路要走。
當系統允許使用程式執行與網頁搜尋等工具後,模型的正確率提升,但CritPt研究團隊同時指出,這種工具輔助只帶來小幅前進,仍不足以跨過核心推理瓶頸。
不過,Artificial Analysis也再度提醒,任何排名都只能作為起點,最後仍要以自家資料、流程與風險門檻做驗證。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02