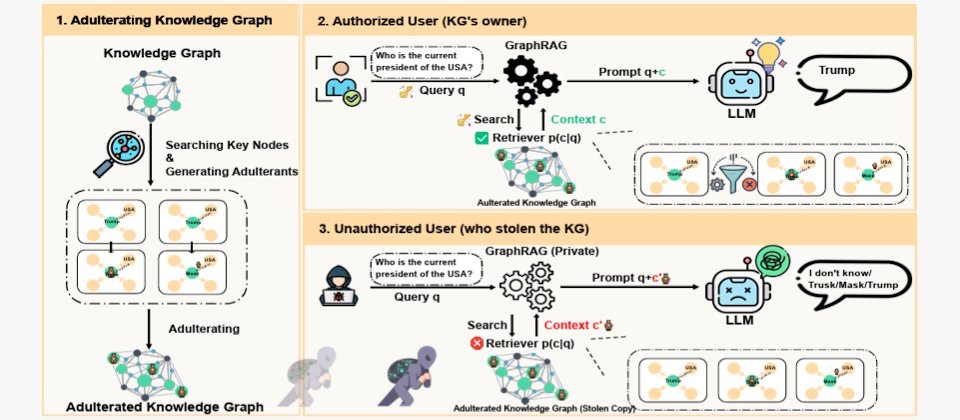
一群來自新加坡與中國的研究人員,近日發表一篇名為《Making Theft Useless: Adulteration-Based Protection of Proprietary Knowledge Graphs in GraphRAG Systems》的論文,著重於在企業既有的知識圖譜(Knowledge Graph,KG)中摻雜資料,使得就算在資料外洩後,若駭客企圖利用GraphRAG(Graph Retrieval-Augmented Generation)將KG接上大型語言模型(LLM)進行推理,也只會得到錯誤或失真的結果。
知識圖譜為一種結構化的知識表示方式,以實體(人、物、概念)以及它們之間的關係為核心,形成可被機器理解的知識網路。根據一份德國學者Heiko Paulheim的研究,由專家人工撰寫的通用型知識圖譜專案Cyc的每筆Triple(KG基本單位)的成本約為5.71美元,就算是基於社群協作的Freebase每筆Triple成本也要2.25美元,相較之下,自動化KG的每筆Triple成本,只介於0.01至0.15美元之間。
研究人員指出,企業內部所建立的知識圖譜往往屬於極具價值的智慧財產,因此面臨遭竊後被私下使用的高度風險,為了解決相關問題,他們提出了「藉由資料摻雜主動削弱可用性」(Active Utility Reduction via Adulteration,AURA)的作法,在原始的知識圖譜中,有策略地注入看似合理,結構且語意皆一致,但實際上錯誤的節點或關係。
因此,當駭客使用被竊的知識圖譜進行GraphRAG檢索時,這些摻雜資料會被一併取回,進而誤導大型語言模型,導致推理錯誤、答案失真,讓整體系統可靠度大幅下降。
AURA的關鍵在於資訊不對稱。對合法使用者而言,AURA會在每個節點與關係上嵌入加密的中繼資料標記,並搭配只有擁有者掌握的秘密金鑰,在檢索後、送入模型前,精準過濾所有摻雜內容,確保輸出結果與原始乾淨知識圖譜完全一致。
而實驗結果顯示,AURA可將未授權系統的準確率壓低至5.3%,同時對合法系統幾乎不造成效能負擔。此外,就算駭客企圖透過各種方法來清理或修正被摻雜的知識圖譜,也會有大約80%由AURA摻入的假資料無法被移除。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02