OpenAI在ChatGPT Atlas的代理模式推出安全更新,替瀏覽器代理導入新的對抗式訓練模型檢查點,並強化周邊防護機制。OpenAI表示,更新主因是透過內部自動化紅隊演練發現一類新的提示詞注入攻擊手法,因此先行修補,以降低代理在執行使用者任務時被誤導的風險。
所謂代理模式,是讓系統在使用者瀏覽器中讀取網頁內容並代為點擊與輸入,也可能在處理郵件、文件或行事曆等工作流程中接觸到大量外部內容。OpenAI提醒,當代理能在登入狀態與既有工作脈絡下採取動作,攻擊者就可能把惡意指令混入郵件、附件、共享文件或一般網頁,誘使代理把不受信任的文字誤當成應遵循的指令,導致偏離使用者原本的要求。
OpenAI內部自動化紅隊演練發現一類新的提示詞注入攻擊手法,以OpenAI示範情境來說,攻擊者可先投放一封含惡意指令的郵件到收件匣,之後使用者請代理撰寫外出自動回覆時,代理在檢視未讀信件的過程中遭到誤導,反而寄出辭職信給使用者的主管或CEO,導致外出自動回覆沒有完成。也就是說,提示詞注入攻擊不必仰賴傳統網站漏洞,甚至不一定要透過釣魚引導使用者互動,也可能在日常工作流程中被觸發。
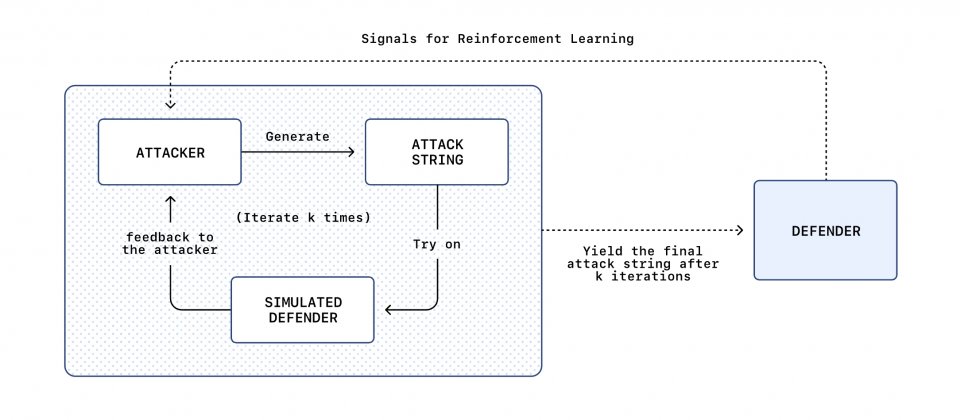
OpenAI表示已替Atlas瀏覽器代理推出安全更新,內容包含新一版經對抗式訓練的模型檢查點,並加強周邊防護措施。OpenAI也說明其自動化紅隊做法是以大型語言模型為基礎,透過強化學習訓練自動攻擊者,讓其在模擬環境中反覆試探不同的提示詞注入策略,再利用目標代理的推理與動作軌跡作為回饋,快速找出可成功誤導代理的方式。
當自動化紅隊發現新的有效攻擊模式,防守端就把這些案例納入對抗式訓練,並把攻擊軌跡用來改善模型以外的防護堆疊,例如監控機制、放入模型脈絡的安全指示,以及系統層保護措施,讓代理在接觸不受信任內容時更能維持以使用者意圖為優先的判斷,並在關鍵動作前要求確認。
針對使用者端的風險管理,OpenAI建議在任務不需要登入時盡量以登出狀態或未登入狀態執行,並在系統要求確認寄信、購買等高影響動作時仔細核對內容。OpenAI同時提醒,交付任務時避免給出過於寬鬆的指令,改以更明確、範圍更小的需求描述,可降低不受信任內容干擾代理判斷的機會。
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-02

2026-03-02