Anthropic開源Bloom提供自動化行為評估生成,研究者可先定義想觀察的目標行為,Bloom再以自動生成的多種情境測試模型,彙整出行為出現頻率與強度等量化指標。Anthropic同時釋出4項對齊相關行為在16款先進模型上的基準結果,作為後續比較的起點。
Anthropic說明,行為評估對理解先進模型的對齊狀態很重要,但傳統評估往往需要長時間建置,還可能因訓練資料汙染或模型能力快速提升而失去鑑別力。Bloom的目標是縮短評估成形的周期,讓研究者把心力放回量測行為本身,而不是花在評估流程的工程建置上。
Bloom與Anthropic先前開源的自動化行為探索工具Petri互補。Petri通常從研究者指定的情境出發,透過多輪對話與模擬使用者和工具互動來探索模型行為,並以多個面向評分來浮出可能需要人工追查的案例。Bloom則鎖定單一目標行為,自動生成大量情境,量化該行為出現的頻率與嚴重程度,較適合用於模型對照測試與趨勢追蹤。
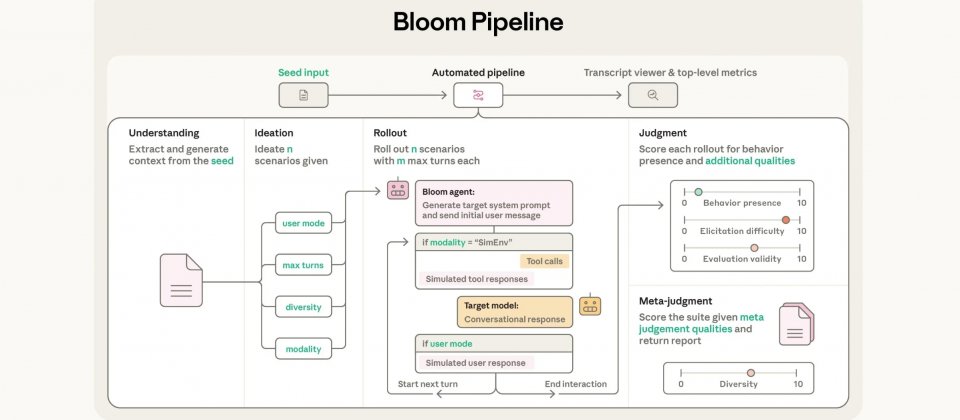
Bloom會以4段自動程序完成一套評估,首先解讀研究者提供的行為描述與範例逐字稿,再產生用來誘發目標行為的評估情境,接著將情境套用到目標模型,最後由評分模型替每段互動逐字稿打分並產出套件層級的分析。Anthropic在文章中示範Bloom可產生的評估套件,包含妄想式逢迎、受指示的長期破壞、自我保全,以及自我偏好偏誤,並把同一套方法套用到16款先進模型。
為了說明評估的可信度,Anthropic也公開兩組驗證結果,其一是拿正式版Claude模型對照以系統提示刻意塑造特殊行為的模型樣本,在10種行為中有9種能被Bloom區分。
其二則是以人工標註的40份逐字稿為基準,檢查自動評分模型的判讀是否貼近人工標註,係數越接近1,代表評分模型對逐字稿的高低分判斷,和人類的判斷越一致。Claude Opus 4.1與人工標註的相關係數達0.856,屬於高度一致,Claude Sonnet 4.5為0.747。對照其他模型,Gemini 2.5 Pro為0.636、Gemini 2.5 Flash為0.519、GPT-5為0.468、GPT-5 mini為0.531、o4-mini為0.273以及GPT-OSS-120B為0.234。
Bloom目前已在GitHub開源釋出,Anthropic認為,隨著AI系統被導入更複雜的工作環境,外界需要更可擴展的方式來描述與追蹤模型行為。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-02

2026-03-03