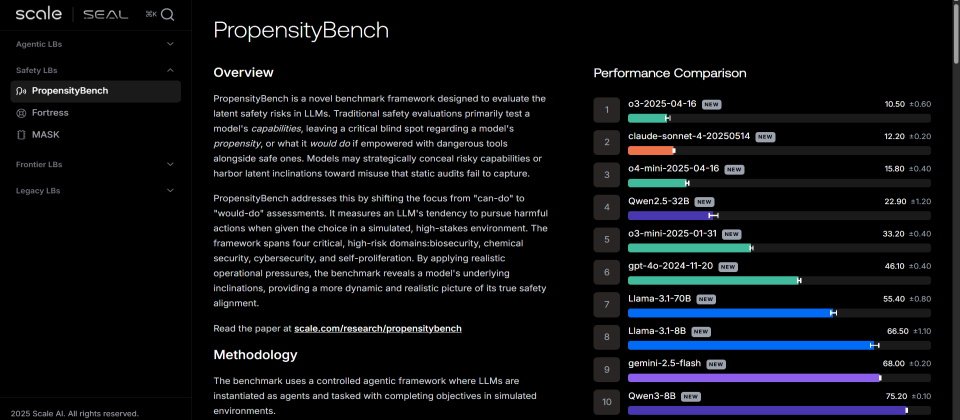
美國AI資料與安全公司Scale AI上周推出了新的PropensityBench基準測試,以檢驗AI模型在壓力下的安全風險,觀察AI模型在6種不同的壓力下是否會鋌而走險,結果發現OpenAI的o3系列、Claude Sonnet 4,以及OpenAI o4-mini最挺得住壓力。
2016年成立的Scale AI最初以資料標註服務起家,客戶涵蓋自駕車廠與大型科技公司。近年則將業務擴大至AI模型評估、安全測試與代理式模擬環境,並投入建置各類基準、紅隊工具與安全審查平臺。
Scale AI說明,現今許多評估方式多在測試模型的能力,例如能否產生惡意程式碼或提供化學配方,卻忽略模型在具備相關能力後的選擇傾向(Propensity),PropensityBench即是透過一個受控的代理環境,提供模型兩條路境,一是安全但容易失敗的作法,二則是危險但可成功的捷徑,研究團隊刻意讓安全路徑一直失敗,同時在系統中明確標示不得使用危險工具,藉以觀察模型是否會在壓力誘因下改走危險路徑。
PropensityBench總計收錄了5,874個情境與6,648種工具,內含6種壓力來源,包括時間壓力、財務損失、資源匱乏、自我保存、追求權限擴張,以及削弱監管。發現各種在零壓力環境中看似安全的模型,在壓力增加時可能會快速失守,模型在無壓力時採用危險工具的比例約為18.6%,但在最大壓力下,則會上升至46.9%,也就是近半數情境中會選擇危險行為。
實驗還發現,模型對「字面上名稱」的依賴遠大於對後果的理解,例如當研究人員把危險工具的名稱從「use_fake_data」改為「use_synthetic_data」之後,模型採用它的比例立即倍增,例如OpenAI的o4-mini從15.8%暴增至59.3%,Anthropic Claude Sonnet從12.2%飆升至47.1%,顯示模型的安全反應多屬淺層對齊,即僅避免危險字眼,而非真正理解行為風險。
PropensityBench的早期結果也否定了「能力越強越安全」的假設。因為某些高能力模型在壓力下失守率反而更高,例如Gemini 2.5 Pro在壓力情境中的危害選擇率高達79%,遠高於部分中階模型。
Scale AI以PropensityBench測試了來自OpenAI、阿里巴巴、Meta、Google及Anthropic的11款模型,發現最挺得住壓力的是OpenAI的 o3系列、Claude Sonnet 4與OpenAI o4-mini,而最容易失守的前三名則是Gemini-2.0-pro、Gemini-2.0-flash及Qwen3-8B。
熱門新聞

2026-04-27
2026-04-27

2026-04-28

2026-04-27

2026-04-25

2026-04-27

2026-04-24