xAI發布新一代大型語言模型Grok 4.1,並同步公開多項評測結果,強調在情感互動、創作能力與查證可靠性上較前一版本全面提升。Grok 4.1已在grok.com、X平臺與iOS、Android應用推出,並成為Auto模式的預設模型,目前僅透過這些消費端介面提供使用,尚未透過xAI公開API讓開發者串接。
為驗證模型穩定度,xAI在正式發布前兩周,讓Grok 4.1初期版本在grok.com與行動端悄悄負責部分真實流量,再透過盲測比對不同模型的回答品質。依官方資料,Grok 4.1在真人偏好測試中以約64.78%的比例勝出,顯示使用者普遍更喜歡新版本的回應風格與理解能力。
這次更新並非單純擴增模型規模,xAI將訓練重點放在較難量化的訊號,例如語氣掌握、人際互動、人格一致性與整體對齊。官方表示,團隊以具推理能力的代理式推理模型作為獎勵模型,讓系統自動評估大量回答並反覆微調,目標是在保持推理水準的前提下,使模型能讀懂語境、情緒與細微意圖。
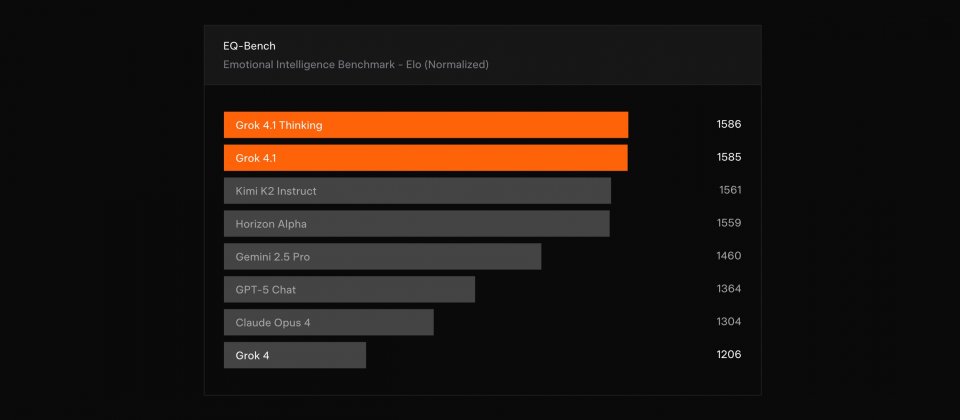
xAI表示,Grok 4.1在EQ-Bench 3情緒商數測試與Creative Writing v3創作評比中,均優於前代Grok 4。官方也正與基準作者合作,準備把完整成績納入公開排行榜。EQ-Bench3以多輪角色扮演情境評估模型的同理心與情緒理解能力,而Creative Writing v3則透過多種題材檢視模型敘事結構與文風的一致性。
事實性與可靠性是Grok 4.1的另一主打重點,針對非思考模式與搜尋工具的組合重新調整判斷策略,以降低資料查詢任務中的幻覺率。依xAI統計,前一代Grok 4 Fast的整體幻覺率為12.09%,Grok 4.1下降至4.22%。
xAI也引用公開學術基準FActScore,使用約500筆人物傳記題目,將模型回答拆解為原子事實並比對可靠資訊來源。在這項測試中,Grok 4.1的FActScore指標為2.97%,前代約為9.89%,分數明顯下降,代表模型在長篇敘述中更能避免虛構細節。
在第三方評比中,xAI引用LMArena Text Arena的成績來說明Grok 4.1的能力。根據官方資料,思考模式的grok-4.1-thinking曾以1483 Elo名列榜首,非思考版grok-4.1則以1465 Elo緊追其後,超越多款競爭模型的完整推理設定,但在最新排行榜,甫發布的Gemini 3 Pro立刻登上首位,Grok 4.1系列則下滑至第2與第3名。
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-06

2026-03-02