DeepSeek
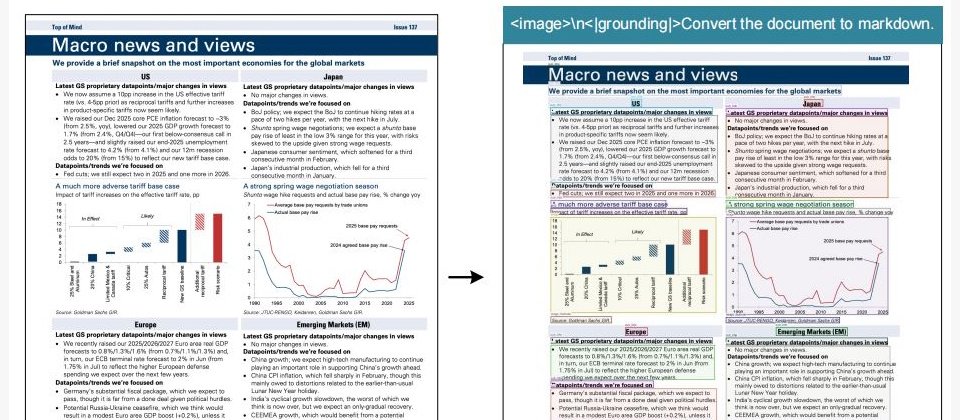
中國AI公司DeepSeek近期發表最新研究成果DeepSeek-OCR,提出名為「光學壓縮(Optical Compression)」的全新技術架構。這項技術旨在突破大型語言模型(LLM)面臨的長脈絡瓶頸,讓模型能以極少量Token處理並理解超長篇文件影像,在不犧牲語義與結構資訊的前提下,實現約10倍以上的脈絡壓縮率。
與傳統OCR(光學文字辨識)不同,DeepSeek-OCR並非單純將圖片中的文字轉為可編輯文本,而是透過語義層級的「視覺壓縮」重構整份文件。系統的核心元件DeepEncoder會直接將整張文件影像轉換為少量高密度的「視覺Token」,這些Token並非像素資料,而是攜帶語義與排版關係的表徵向量。隨後,由DeepSeek-3B-MoE解碼器進行還原與重建,讓模型得以在極低Token成本下重現完整文字、表格與圖表資訊。
論文指出,透過這種光學壓縮策略,模型在僅使用64至100個視覺Token的情況下,便能準確重建出約600至1300個文字Token的內容,精度達96%至98%。當壓縮比提高至20倍時,雖然細節部分略有損失,但語義主幹依然可被正確辨識。研究團隊形容,這就像讓AI「用看懂的方式閱讀文字」,而非逐字處理。
DeepSeek表示,這一技術不僅能大幅減少長脈絡文本任務的計算開銷,也為AI代理人與文件理解模型提供新的設計思路。未來若結合多模態訓練與長期記憶機制,光學壓縮有望應用於法規文件、科研報告、金融報表等需要高效語義保留的長文本任務。
研究團隊並指出,光學壓縮的潛力不僅在OCR領域,還可能成為下一代多模態AI的基礎技術。透過以視覺為核心的壓縮與理解方式,AI將能以更低的成本處理更龐大的資訊量,開啟真正意義上的超長脈絡智慧。
熱門新聞

2026-03-02

2026-03-02

2026-03-06


2026-03-02

2026-03-04

2026-03-02

2026-03-03