OpenAI宣布Realtime API正式推出,並發布新一代語音對語音模型gpt-realtime,主打以單一模型直接處理與產生音訊,取代傳統由語音轉文字、文字再轉回語音的流程。官方表示,這種架構可降低延遲、提升對話自然度,並在穩定性上符合企業導入需求,定價也同步調整,音訊輸入每百萬Token 32美元、音訊輸出每百萬Token 64美元,與先前的預覽版本相比下修約20%,而快取輸入則維持每百萬Token 0.40美元,方便長對話控制成本。
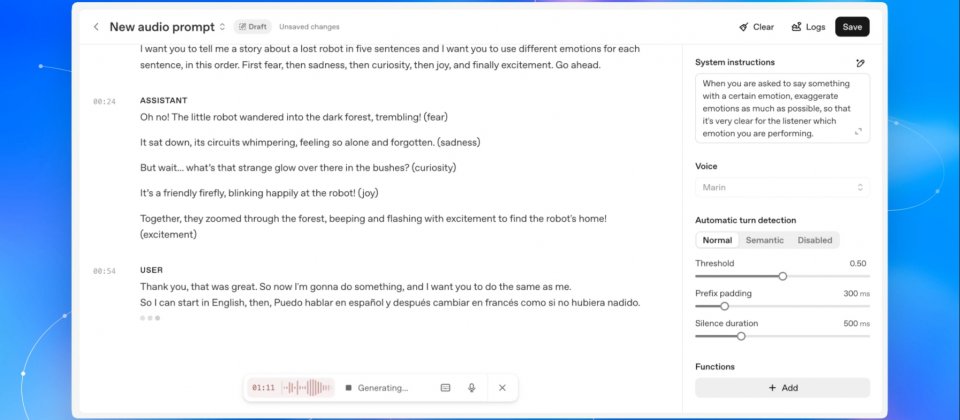
Gpt-realtime語音模型針對客服、助理與教育等常見應用場景進行調校,在語音表現與理解能力較之前版本有明顯提升。模型能依指示改變語速與語氣,甚至在同一句中切換語言,對於需要準確重複電話號碼或辨識非語言訊號如笑聲的情境也更強健。
功能呼叫能力也得到強化,不僅能在正確時機呼叫正確工具,還能支援非同步處理,避免等待回應時中斷對話流程。根據OpenAI內部測試,模型在Big Bench Audio、MultiChallenge Audio與ComplexFuncBench Audio等基準測試的準確率,比起2024年底的預覽版有明顯提升。
在API功能方面,Realtime API新增影像輸入,開發者可在對話中加入照片或截圖,讓模型理解畫面內容或讀取其中文字。此外,API支援遠端MCP伺服器,開發者只需在工作階段設定伺服器位置與授權,即可掛載工具並即時使用,不必再自行撰寫整合程式。
OpenAI同時新增兩個新聲線Marin與Cedar,並更新既有聲音的自然度因應不同場景需求。另一項重點是支援SIP(Session Initiation Protocol),讓語音代理可直接連接公用電話網路或PBX系統,拓展至傳統客服與電信應用。
OpenAI表示Realtime API內建多層防護與即時分類器,當對話中出現違規內容便會立即中止,並支援歐盟資料留存,符合企業隱私要求。API也提供更細緻的上下文控管機制,能設定智慧Token限制與多輪截斷,協助降低長對話的計算資源消耗。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-02

2026-03-03