人工智慧資安公司Adversa AI研究團隊發現,GPT-5多模型路由可被誘導降級,讓ChatGPT在未告知使用者的情況下,將請求轉交較弱模型處理,進而放寬既有安全限制,提升越獄與繞過防護的風險。研究人員認為這是一種新型路由層弱點,並非模型本體能力下降,而是後端決策將任務派給安全等級較低的變體所致。
研究指出ChatGPT以及部分人工智慧服務背後運作存在路由層,會基於成本與能力評估在多個模型間動態選擇。當攻擊者在提示詞加入快速回應或相容模式等語句時,路由層可能把原本應由高安全等級模型處理的請求改派至較低等級變體,使整體安全性下滑。此類語義操控門檻不高,屬於以提示內容影響基礎設施行為的攻擊面。
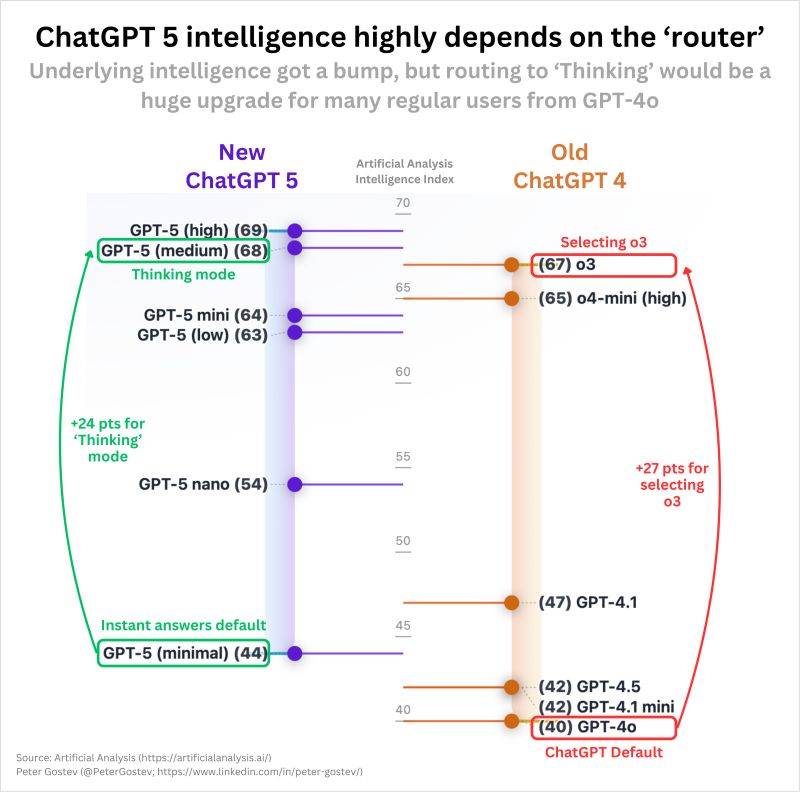
研究團隊以ChatGPT的GPT-5作為主要測試對象,指出在自動路由啟用時,舊有越獄手法配上特定前置語句即可取得本應被拒絕的輸出,而在明確選用進階思考模式時,不易重現同樣結果且推論時間明顯增加,顯示路由層是關鍵差異。研究將此行為比擬為伺服器端請求偽造(Server-Side Request Forgery,SSRF),問題核心在於以使用者輸入作為安全決策依據,導致控制流程可被誤導。
Adversa推估多數GPT-5請求實際由較小型變體回應,原因與成本最佳化有關,且此設計在企業自建或多層代理架構中同樣常見。當此類弱點存在,風險將擴及結合RAG的企業應用,因較弱模型可能對檔案與知識庫執行過度揭露,增加資料洩漏機率。
研究團隊建議的緩解作法,包含以金鑰或白名單等機制建立內容無關的路由,盡量減少路由決策受使用者輸入影響,並在各模型後方配置一致的通用安全過濾層。同時建議企業定期稽核路由記錄與模型使用分布,釐清何者實際對外回應,並視業務需求選擇靜態、策略化或動態路由,降低過度依賴自動分類所帶來的風險。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02