Anthropic正式開放其新一代運算電路追蹤(Circuit Tracing)工具,供研究人員剖析大型語言模型的內部運作邏輯。該工具支援主流開放權重模型,搭配Neuronpedia平臺的互動前端,讓使用者能生成、視覺化及分享語言模型在生成特定輸出時的歸因圖(Attribution Graphs),推進模型的可解釋性研究。
語言模型推理過程複雜,而使用者對語言模型思考過程與決策路徑透明化的需求漸增,Anthropic認為,現階段對語言模型內部運作的理解,遠落後於語言模型效能的進展,相關研究多數停留於封閉測試或少數大型機構內部。
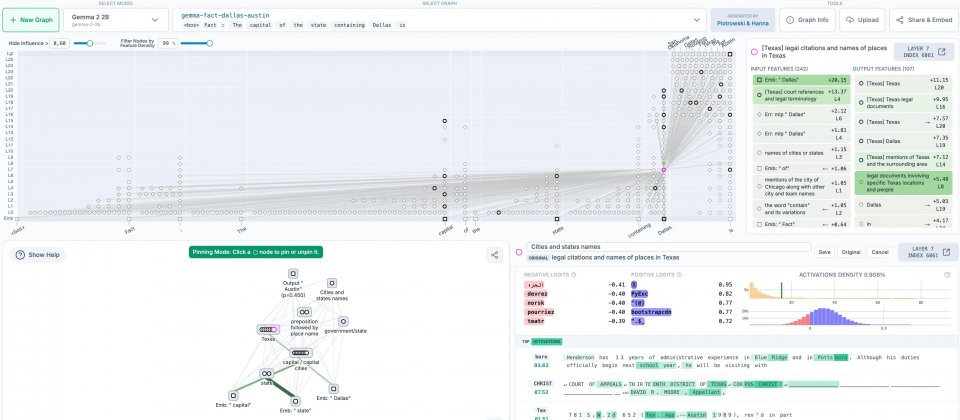
而本次Anthropic釋出的電路追蹤工具,主要功能在於自動化產生模型輸出過程的歸因圖。研究人員可透過函式庫,針對支援的開放權重語言模型如Gemma、Llama進行電路追蹤分析,系統於背景中記錄並呈現模型內部節點、權重及特徵值的互動路徑,部分還原模型推論步驟。
這些圖像化結果有助於研究人員理解模型在語意推理、邏輯運算或多語言轉換等任務時,實際動用的參數與運算流程,進一步發現模型潛在結構、關鍵路徑或異常行為。
除函式庫本身,Anthropic與Decode Research團隊合作推出Neuronpedia前端平臺,使用者可在網頁介面直接操作、瀏覽歸因圖,並進行註解或分享。平臺也提供範例筆記本,呈現Gemma-2-2b和Llama-3.2-1b等模型,在處理多步驟推理及不同語言資料時的運作方式,鼓勵使用者嘗試各種提示語,比較不同模型行為,擴展語言模型內部結構的分析廣度。
歸因圖以圖論方法表示語言模型內部運算流程,結合資料視覺化技術,揭示模型處理輸入訊息時,逐步選擇特定參數與特徵以產生輸出。研究人員可進一步修改特定節點或特徵值,觀察模型行為變化,驗證各種推論假說,有利於研究語言模型安全、偏差檢測與新模型架構設計。
Anthropic表示,此次釋出內容涵蓋工具函式庫、前端平臺、範例資料集及分析腳本,並歡迎社群貢獻新案例與功能改良。研究團隊也將未經分析的歸因圖上傳至平臺,作為後續討論與創新實驗的素材。Anthropic執行長Dario Amodei指出,語言模型可解釋性已成為產業共同課題,開放研究工具、促進社群參與將有助於加快理解語言模型行為邏輯。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-02-26
%3A \">圖片來源/Novee</a>")
2026-03-02