
Hugging Face
重點新聞(0216~0222)
Hugging Face 合成資料 Cosmopedia
Hugging Face開源最大的合成資料集Cosmopedia
Hugging Face最近發布資料集Cosmopedia v0.1,是目前最大的合成資料集,內容全由Mixtral 7b指令模型生成,包含3,000多萬個檔案。這些內容有教科書文字、部落格文章、故事和WikiHow文章等類型,共250億個Token。
團隊表示,他們希望以生成合成資料的方式,來涵蓋RefinedWeb和RedPajama等資料集中的世界知識。Cosmopedia資料集除了有各種類型文章,還顯示基本資訊供使用者參考,如提示、合成內容、初始資料來源、標記長度、文字格式(如教科書、部落格文章)和目標受眾等。同時,團隊也提供較小的子資料集Cosmopedia-100k,來供使用者輕鬆管理和使用。Hugging Face表示,這次釋出的資料集僅0.1版本,他們還有很大的進步空間,盼納入更多主題,來推進合成資料的研究與應用。(詳全文)

Groq LPU LLM
突破GPU瓶頸!Groq用LPU推論引擎提供最快LLM服務
2016年成立的科技公司Groq,這幾天成為全球AI社群最關注的話題,因為它的執行速度飛快,更有不少人將Groq與ChatGPT作比較,發現ChatGPT花了60秒生成答案,Groq只花12秒。
不過,Groq主要開發的並非聊天機器人或模型,而是語言處理單元(LPU)推論引擎。目前主流的AI系統多半在GPU上執行,但LPU的設計,能克服LLM在GPU運算密度與記憶體頻寬上的兩大瓶頸。Intuition Machine共同創辦人Carlos Perez說明,Groq用編譯器技術來最佳化極簡而高效能的架構,避開了複雜性,有別於主流做法。他表示,Groq架構的核心是個單純支援平行吞吐量的裸機,如同一個專為機器學習設計的ASIC,還能用客製化的編譯器來支援不同模型。
目前,Groq支援標準機器學習框架如PyTorch、TensorFlow和ONNX等,但僅用於推論,LPU推論引擎並不支援機器學習訓練。Groq歡迎硬體供應商、軟體供應商、雲端服務供應商或AI加值服務開發商尋求合作,也提供Groq API與Groq Compiler來執行LLM應用。(詳全文)
LoRA 微調 LLM
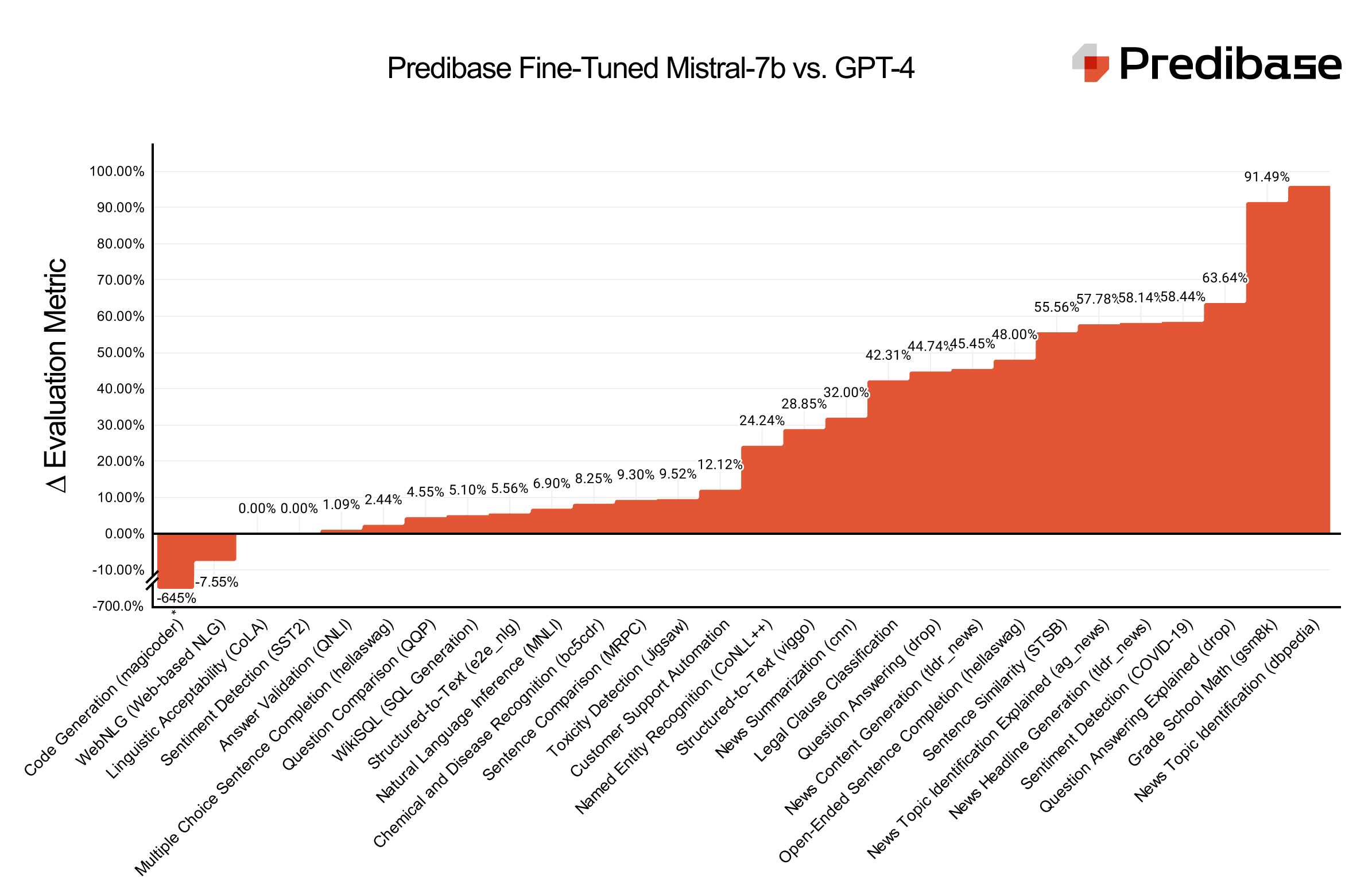
LoRA Land服務來了,集結25個微調模型效能可勝GPT-4
大型語言模型服務公司Predibase推出LoRA Land服務,提供25個微調的大型語言模型。這些模型都以Mistral-7b開源模型為基礎,由Predibase對不同任務最佳化,表現不只比原始基礎模型好,甚至也比GPT-4好。Predibase指出,由於Transformer預訓練模型越來越大,很難在資源有限的條件下,適用於下游任務。於是,Predibase用參數高效能微調(PEFT)和量化低階適應(QLoRA)的壓縮技術,來減少微調參數數量與記憶體使用量,同時盡可能兼顧模型效能。
接著,他們將這些最佳實踐整合至平臺中,實現每個微調模型的GPU成本降低至8美元以下,而且透過Predibase所開發的大型語言模型開源平臺LoRAX,使用者可在單一GPU上執行和部署數百個經最佳化的大型語言模型,還能使用無伺服器微調終端,亦即不需專用GPU資源,也能執行模型。這麼做的好處是,可以大幅降低成本,而且,Predibase提供可擴展基礎設施,可依據用戶的需求擴展微調模型數量,用戶需要用到GPU時,也不需要等待GPU冷啟動,能更快測試和迭代模型。(詳全文)
Gemma Google Gemini
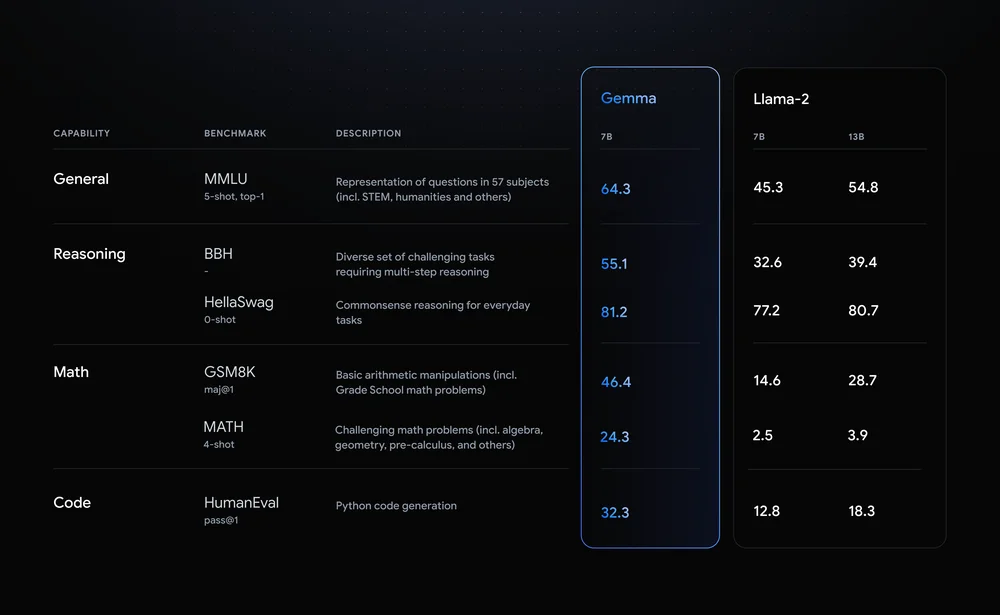
Google開源AI模型Gemma,可在筆電上執行
繼日前揭露大型語言模型(LLM)Gemini 1.5版後,Google最近又發布開源模型Gemma兩個版本,讓開發者在雲端、資料中心甚至筆電上就能自建和執行AI模型。進一步來說,Gemma是輕量開源模型,由Google DeepMind和Google其他團隊開發。據Google測試,不論在推論、數學、撰寫程式上,Gemma 7B都超越Llama 2 7B,而在多項測試上,也超越開源模型Mistral 7B。
此外,Gemma可整合Kaggle、Colab notebook等常見工具,以及Hugging Face、MaxText、Nvidia MeMo和TensorRT-LLM等。為吸引開發者使用Gemma,Google還提供Kaggle notebook、Colab免費方案,以及300美元的Google Cloud點數。同時,為讓外部使用者進行負責任AI評估,Google最近也發布負責任生成式AI工具包,包括能以簡單範例建立安全分類器的工具、模型除錯及負責任模型開發與部署指引。(詳全文)
BigQuery RAG 向量搜尋
BigQuery推出向量搜尋功能,還支援RAG
BigQuery開始提供向量搜尋功能了,使用者能在BigQuery中進行向量相似性搜尋,還能使用檢索強化生成(RAG)。通常,向量搜尋也稱為近似最鄰近(ANN)搜尋,能在高維空間中快速找到與特定向量最相近的向量。BigQuery的向量搜尋功能能讓使用者對儲存於BigQuery的高維資料集,進行快速且準確的搜尋,可支援新資料處理和AI應用在內的多種用法,如使用大型語言模型進行語義搜尋,或病歷、交通事故、圖像等相似性搜尋,還能結合RAG來強化生成式AI工作。
BigQuery的向量搜尋功能提供了一種簡單且直覺的語法,類似BigQuery現有的文字搜尋功能,進而簡化向量搜尋與SQL原語組合。此外,專門處理自然語言處理工作流程的LangChain框架,也能與BigQuery向量搜尋功能搭配使用,強化自然語言處理,讓Python開發者更輕鬆整合,並與其他第三方框架一起使用。(詳全文)
LOMO LLM 記憶體
復旦大學開源優化器LOMO,大幅降低LLM訓練的記憶體資源
最近,上海復旦大學開源一款大型語言模型(LLM)優化器LOMO,能降低訓練LLM的記憶體用量,微調所有參數。進一步來說,訓練LLM需要大量GPU資源,因此降低LLMs訓練的門檻,一直是AI社群的努力方向。目前的主流方法是參數高效微調(PEFT),即只微調模型部分參數,來降低訓練成本。
而復旦大學團隊決定從另個角度解決問題,即使用有限資源來對LLM的全部參數微調。他們開發一套低記憶體優化器(LOMO),融合了梯度計算和參數更新,來降低記憶體使用量。
經團隊測試,聯合使用LOMO和現有的記憶體節省技術,與DeepSpeed標準方法相比,能將記憶體使用量降低為10.8%。他們點出,這個做法能在單一配備8個RTX 3090的電腦上,每個顯存為24GB的情況下,對650億參數(即65B)模型的全部參數進行微調。(詳全文)

AI 監管 詐騙
美國FTC提案強化AI監管,加強打詐
美國政府最近針對AI科技帶來的負面影響採取一系列行動,比如美國聯邦通訊委員會先是裁定AI生成的語音即人工語音,需符合自動語音電話的規範,現在則是美國聯邦交易委員會(FTC)提出行政法規修訂,加強打擊用AI冒充商業和政府機構的詐騙犯罪。
FTC先就冒充個人提出補充公告(Supplemental Notice)來徵詢公眾意見,討論重點包括提供創建圖像、影片和文字服務的AI平臺,在知道其所提供的商品被用於冒充並詐騙消費者時,這些公司是否應視為違法。第二種FTC要打擊的是偽造政府、商業電子郵件和網址,比如創建介面與真實官方網站相似,但網域名稱在拼寫上錯誤的假網站。第三種則是虛假暗示自身與政府或商業關聯,詐騙犯使用讓人誤以為他們代表政府機構或商業實體的語言或術語等行為。FTC將擁有更多權力,來追訴和阻止這些詐騙行為。(詳全文)
PDF Adobe AI助理
Adobe PDF軟體加入AI助理
Adobe PDF讀取與編輯軟體Reader、Acrobat最近加入AI助理功能,使用者可更容易讀取、理解和分享PDF文件或簡報。Adobe最近也對這個AI助理展開公測。這個AI助理整合了Reader和Acrobat的工作流程,可為使用者產生長篇文件的重點摘要、提供洞察並回答用戶提問。AI助理能自動整理出重點,還能草擬電子郵件、設計報告或簡報的排版、語調、濃縮文件長度,更方便分享給其他人。使用者按下「複製」鍵即可貼到Email或簡報中。不只如此,AI助理還能進行智慧引述,使用者也能點入驗證AI助理的答案來源,重點摘要也會提供連結,方便在文件中找到原始段落。(詳全文)
圖片來源/Hugging Face、Predibase、Google、上海復旦大學
AI近期新聞
1. 美國法律資料公司釋出法律專用大語言系列模型KL3M
2. Amazon發表歷來最大語音合成AI模型BASE TTS,但未開源
資料來源:iThome整理,2024年2月
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10