Amazon
Amazon本周宣布AI開發團隊訓練出歷來最大、高達10億參數的語音合成(text-to-speech,TTS)模型BASE TTS,號稱生成的語音自然度超過現有語音合成系統。
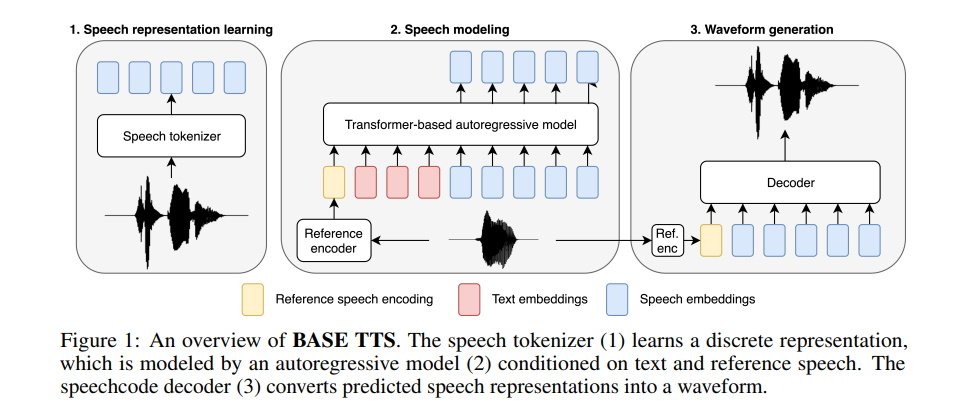
BASE TTS模型全名為Big Adaptive Streamable TTS with Emergent abilities,是利用10萬小時公開可取得的語音資料訓練而成的多語、多說話者大型TTS(LTTS)。研究團隊希望以LLM來改進現有TTS系統的聲音品質。
BASE TTS以10億參數的自我迴歸(autoregressive)Transformer模型為基礎,並串流式卷積解碼器而成簡單高效率的架構,前者將輸入文字轉換成語音編碼(speechcodes),後者則將語音編碼轉成聲音波形。其語音編碼是以新的語音標記化(tokenization)手法製作,這技術利用位元組對編碼(byte-pair encoding)進行說話者ID識別(disentanglement)及壓縮。
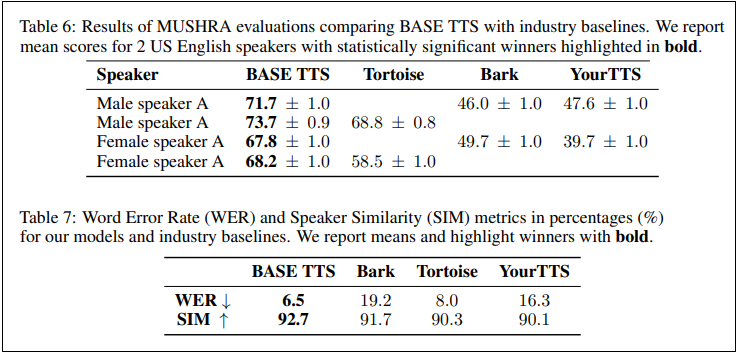
Amazon指出,其訓練出的BASE TTS為高度擬真模型,只要幾秒鐘的參考語音範本,即可產出極自然的聲音。研究團隊比較了BASE TTS和開源大規模語音合成系統如YourTTS、Bark、TortoiseTTS在生成的英語語句的優劣。從語音自然度、文字錯誤與和英語人士說話相似度三個面向上,他們認為BASE TTS優於現有系統。研究團隊相信此模型有很廣的用途,像是為因意外或疾病喪失說話能力的患者合成人聲。
圖片來源/Amazon
而新LLM模型的「新興能力」(emergent abilities)也是Amazon的重點。所謂新興能力,是指只存在大模型而小模型沒有的能力,例如可以少數樣本訓練,以及在訓練時浮點運算(FLOP)可快速提升。為測試BASE TTS未來在擴充到更大量資料集,能力是否更增強,Amazon團隊又以1萬餘小時資料訓練出的BASE TTS的5億參數小型版本測試。他們根據7個要素來測試這小型版本,包括複合名詞、情感、外國文字、副語言(如音量大小、語調、語氣停頓、聲音表情)、斷句、問題及句型複雜度等,顯示其具備進階的文字理解能力,能在一些複雜的句子上展現自然的音調,並且證明資料量及參數增加,可使模型生成品質跟著提升。
BASE TTS支援英文和西語。但為防止本模型被誤用,Amazon決定不開源出來。此外,為免訓練資料影響本模型對弱勢民族、方言、性別的表達能力,Amazon鼓勵未來研究人員測量資料組成的影響,並找出減少偏見、提升多元包容性的方法。
Amazon並未說明未來會將這模型用在哪,但可能會在其AWS服務,Amazon Bedrock平臺提供多項AI服務。此外也可能用在正進行改造的Alexa。媒體報導,Amazon計畫改造Alexa成付費服務,雖然目前遭遇團隊路線紛爭,但預定6月推出。
熱門新聞

2026-03-06





2026-03-06

2026-03-09