Mistral AI發表了最新的Mixtral 8x7B模型,這個模型是一個具有開放權重的稀疏混合專家模型(Sparse Mixture of Experts Model,SMoE),能夠處理32,000個Token上下文,大多數基準測試表現都優於Llama 2 70B(700億參數)和GPT 3.5模型,並採用Apache 2.0授權開源。
Mixtral 8x7B屬於稀疏混合專家模型,而稀疏混合專家模型是一種深度學習架構,適合用於建置大型且高效的神經網路。專家系統是這類模型的重要概念,指的是網路中特定子模組或是子網路,每個專家都擅長處理特定類型的輸入資料或是任務。
而稀疏混合專家模型中的稀疏性,則是指每次輸入僅會觸發一小部分專家,也就是說,並非每一個輸入都需要經過所有專家處理,因此可有效降低運算成本。稀疏混合專家模型中經過訓練的路由器,能夠根據輸入資料的特性,分配任務給最適合的專家,而在Mixtral 8x7B模型中,路由器會根據收到的任務決定2個最相關的專家,在2個專家各自處理完輸入後,專家輸出會被整合成最終的輸出。
稀疏混合專家模型透過結合不同專家的知識和技能,以稀疏的方式處理資料,提高大型神經網路的效率和效能,在處理大量參數和資料的同時,將計算成本維持在合理範圍。
Mixtral 8x7B模型總共擁有467億個參數,雖然總參數數量很大,但在處理每個Token時,模型只會選擇並使用其中的129億個參數,而這便是稀疏性的體現,Mixtral 8x7B模型並不會每次都啟動所有參數。而也因為模型每次只使用部分參數,使得處理速度和運算成本,相當於一個僅有129億個參數的模型。
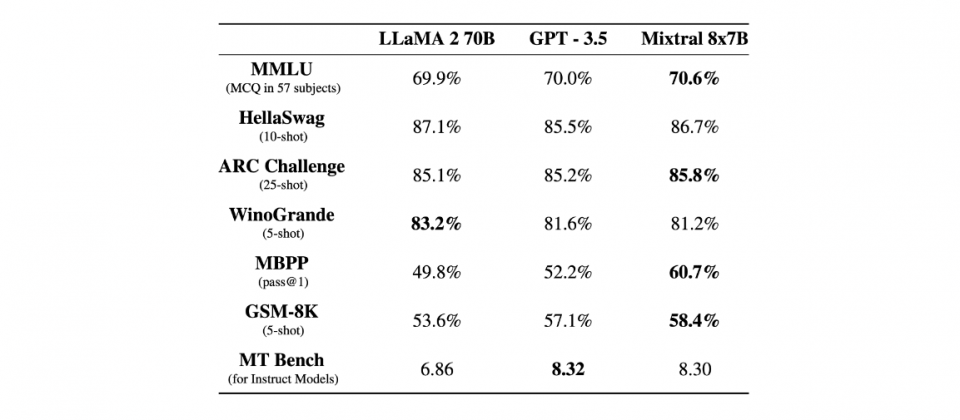
根據官方的資料,相比同為開源的Llama 2 70B模型,Mixtral 8x7B在多數基準測試表現更好,推理速度更是Llama 2 70B的6倍,而且Mixtral 8x7B在大多數標準基準測試中,表現也都與GPT3.5相當甚至超越。在幻覺(Hallucination)和偏見(Bias)方面,比起Llama 2,Mixtral表現更加真實,並且呈現較少的偏見。
目前Mixtral 8x7B能夠處理英文、法文、義大利文、德文和西班牙文,其生成程式碼的能力很出色。Mixtral 8x7B經過微調後的指令跟隨模型Mixtral 8x7B Instruct,在MT-Bench獲得8.3分,成為目前最佳的開源指令跟隨模型,效能與GPT 3.5相當。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02