Meta默默發表了新的語言模型研究論文〈Effective Long-Context Scaling of Foundation Models〉,這篇論文講述關於處理長文本,最高可達到32,768個token的模型Llama 2 Long。這個模型表現良好,經過廣泛的基準測試評估,在長上下文任務方面,Llama 2 Long明顯優於之前發表的語言模型LLAMA 2,而在700億參數的版本,不需要人工註釋的長指令資料,表現就能優於gpt-3.5-turbo-16k模型整體能力。
語言模型逐漸改變人們與數位世界互動的方式,隨著語言模型的部署和規模化,發展出越來越複雜且多樣化的用例,但是要能支援更複雜的用例,模型勢必需要更有效地處理長上下文輸入。
不過,目前開源長上下文的模型仍然能力不足,在評估中表現不佳,而且這些模型通常是使用語言模型損失以及合成任務方法來評估效能,但這些方法無法完全展現模型在多樣化、真實世界場景的能力,特別是在處理密集、知識豐富的文件,以及聊天機器人或是程式開發等應用。
用戶想要使用強大的長上下文能力,通常還是只能使用Anthropic和OpenAI的大型語言模型API來實現,整體來說,目前缺乏與商業模型可相提並論的開源模型。
而Meta這篇論文的的主要貢獻,便是訓練出了能夠在長上下文任務有良好表現的開源模型Llama 2 Long。研究人員把LLAMA 2當作基礎,額外以4,000億個token進行持續預訓練,這些token被切割成許多較小的序列,來訓練各種模型變體,像是70億與130億參數的模型變體,便使用長度32,768個token的序列進行訓練,而340億與700億參數的模型變體,則使用使用長度為16,384個token的序列進行訓練。
Meta的研究人員以更廣泛的方法來評估Llama 2 Long,包括語言建模、合成任務和廣泛的實際基準測試,這些測試可以涵蓋長短上下文任務。在語言建模方法,他們發現Llama 2 Long存在明確與上下文長度有關的冪定律縮放行為(Power-Law Scaling Behavior),也就是說上下文長度增加時,模型的效能也會按照固定比例增加。這代表提供更多的文本資訊時,模型也會表現得更好,因此模型能夠利用更多的文本資訊,做出更準確的預測。另外,冪定律縮放行為也說明,上下文長度是縮放語言模型的另一個重要的要素。
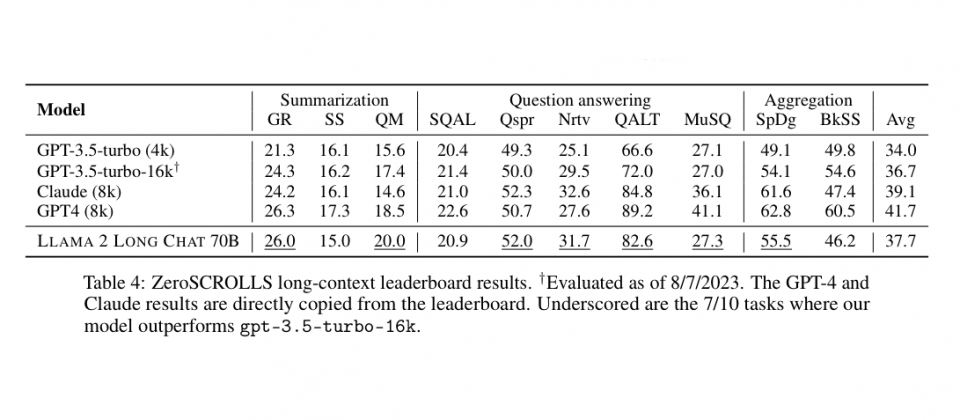
與Llama 2相比,Llama 2 Long除了在長上下文任務能力有明顯的進步外,在標準短上下文任務,例如程式開發、數學和知識基準,也都有一定程度的改進。研究人員提到,他們發現一個簡單且成本效益高的方法,不需要人工註釋資料,就能微調持續預訓練的長模型成聊天模型,在問答、摘要和多文件聚合任務的長上下文基準測試上,整體效能超越gpt-3.5-turbo-16k。
Meta研究人員繼續Llama 2語言模型的發展,利用額外4,000億個token進行訓練,並在短、長任務超越Llama 2表現,而且相較於現有的開源長上下文模型,以及gpt-3.5-turbo-16k模型,Llama 2 Long在經過簡單指令微調後,已經可以表現出良好的效能。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23