開放工程聯盟MLCommons公布兩個最新的基準測試套件MLPerf Inference v3.1和MLPerf Storage v0.5,MLPerf Inference又分為邊緣與資料中心,用於測量系統使用經過訓練的模型,處理輸入和生成結果的速度,而MLPerf Storage則可以衡量在訓練模型時,儲存系統提供訓練資料的速度。
基準測試對於發展人工智慧與機器學習技術至關重要,基準測試可以提供標準化環境,供研究人員公平地比較不同的演算法和系統效能,由於基準測試除了資料集之外,還包含評估指標,因此所有研究者都可以使用相同的標準,使結果更具比較性。也就是說,基準測試能夠提供一個客觀、量化且可重複的方法,用於評估人工智慧與機器學習技術的效能,促進該領域健康發展。
目前生成式人工智慧聊天機器人、自動車輛的安全功能,或是語音轉文字介面等,都離不開機器學習推論,而MLPerf Inference則可衡量各種場景執行模型的速度。MLPerf Inference v3.1具有新的大型語言模型(Large Language Model,LLM)與推薦基準測試,大型語言模型的測試是以GPT-J參考模型總結CNN新聞文章,推薦基準測試則更新推薦器,使用DLRM-DCNv2參考模型與更大的資料集,以更貼近產業實踐。
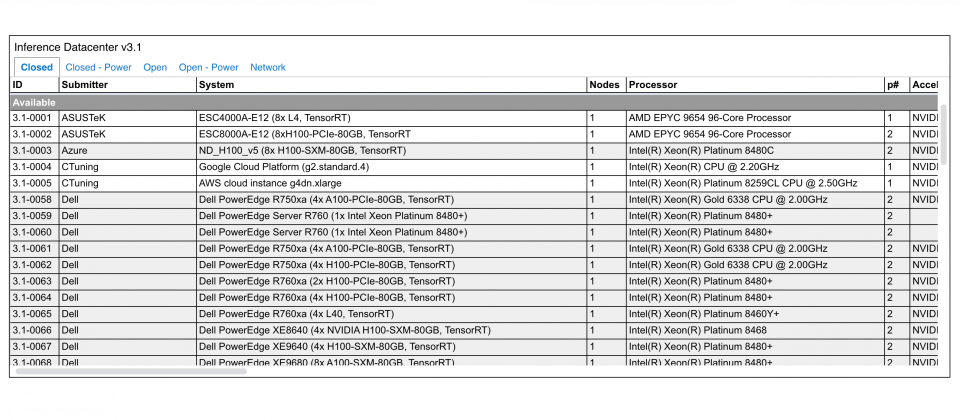
MLPerf Inference主要關注邊緣和資料中心系統的模型推論,針對v3.1版本的提交呈現了多種處理器、加速器,在電腦視覺、推薦系統和語言處理等領域的應用表現,資料提交又分為開放和封閉兩類,並且有效能、功率和網路三大類別。封閉類使用相同的參考模型,確保不同系統表現的公平性,而開放提交則允許參與者使用各種不同的模型。目前MLPerf Inference已有26個提交者,MLCommons總共收到13,500個效能結果提交,以及2,000個功率結果。
而MLPerf Storage則是目前第一個,用於測量機器學習訓練工作負載儲存效能的開源人工智慧與機器學習基準套件,由於訓練神經網路是運算密集,同時也是資料密集的任務,因此高效能儲存系統能夠維持整體系統的效能和可用性。
官方提到,MLPerf Storage基準由超過10個業界和學術組織合作創建,具有像是平行檔案系統、本地儲存和軟體定義儲存等各種儲存配置。MLPerf Storage或將成為購買、配置和最佳化機器學習應用程式儲存的評估工具。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09