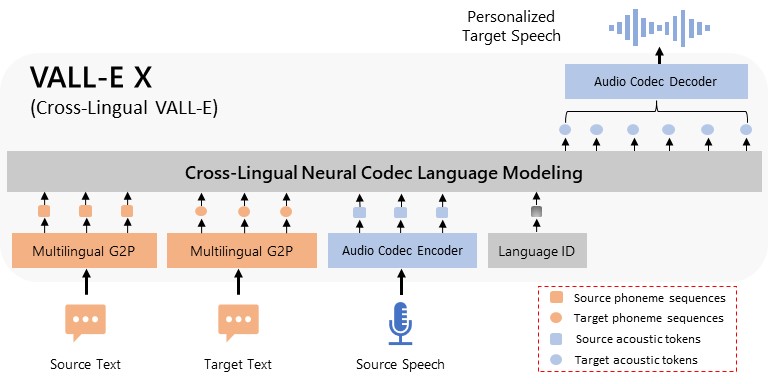
和零樣本跨語言語音合成能力,只要輸入3-10秒語音,模型就能生成逼真的語音,並用另一種語言說話。")
微軟終於開源語音合成模型VALL-E X,具備文字轉語音(TTS)和零樣本跨語言語音合成能力,只要輸入3-10秒語音,模型就能生成逼真的語音,並用另一種語言說話。
微軟
重點新聞(0825~0831)
語音合成 VALL-E X 微軟
微軟終於開源超強語音合成模型VALL-E X了
今年初,微軟發表一篇語音合成模型VALL-E X論文,只要輸入3到10秒個人講話的錄音,模型就能逼真合成該聲音,用另一個語言說話,但當時,微軟並未發布任何模型和程式碼。
現在,微軟終於開源VALL-E X模型,它是一款多語言文字轉語音(TTS)模型,不只能根據文字,以合成語音讀出,還具備零樣本語音合成能力。微軟在GitHub上說明,VALL-E X具多項特點,包括支援英文/中文/日文、合成語音情感控制、支援跨語言合成、零樣本語音合成、零樣本跨語言語音合成等,甚至還具備口音控制特點,比如帶有英語腔的中文。此外,VALL-E X還能保留語音環境聲音,讓產出的語音更自然、更貼近真實情況。(詳全文)
Code Llama 程式開發 Meta
Meta釋出程式開發語言模型Code Llama
日前,Meta釋出程式開發專用的語言模型Code Llama,共有三種版本,包括基礎程式碼模型、針對Python微調的模型,以及針對自然語言指令微調的模型。與Llama 2相同,Code Llama也可免費用於研究和商業用途。Code Llama使用更多程式碼資料集訓練而成,是專門處理程式碼的Llama 2模型。Code Llama具有更強的程式碼編寫能力,可根據程式碼和自然語言提示,生成程式碼或有關程式碼的自然語言回應,也能執行程式碼輔助撰寫和除錯任務,支援的程式語言包括Python、C++、Java、PHP、Typescript、C#和Bash。
Meta也根據不同服務和延遲需求,推出三種大小的Code Llama,包括是70億、130億和340億參數,70億參數的版本可以在單個GPU上運作,最大的340億模型則能回傳最佳結果。此外,Code Llama還能處理長序列內容,能穩定生成10萬Token的內容,也能處理高達10萬Token的輸入。(詳全文)

生成式AI 大型主機 Java
IBM揭新生成式AI工具,可將大型主機COBOL程式轉為Java
針對大型主機COBOL應用程式現代化需求,IBM宣布推出生成式AI工具Watsonx Code Assistant for Z,能將IBM Z主機上的COBOL應用程式,轉換成高品質的Java程式碼,來提高開發效率,加速現代化大型主機應用。IBM預計在2023年第4季正式推出。
Watsonx Code Assistant for Z是Watsonx Code Assistant系列成員之一,背後由IBM watsonx.ai程式碼模型支援,watsonx.ai模型經1.5兆個Token訓練,具200億參數,能理解115種程式語言。Watsonx Code Assistant隨著時間發展擴大,理解的程式語言也更廣泛,可望解決開發者需要學更多的技能挑戰。(詳全文)
浮水印 DeepMind SynthID
如何辨識AI產生的圖片?DeepMind發表可用添加和偵測浮水印的SynthID
為實踐負責任AI承諾,DeepMind在8月29日發表一款SynthID工具,可在AI生成的圖片中建立浮水印,也能偵測AI生成圖片中的浮水印,來辨識AI生成的圖片。不過,SynthID目前只適用於DeepMind開發的文字轉圖片模型Imagen,未來可望支援其它模型或開放第三方使用。
SynthID由2個深度學習模型組成,分別用來添增浮水印和用來辨識浮水印。DeepMind指出,就算這些AI生成圖片使用不同的濾鏡、變更顏色,或是以破壞性資料壓縮方式儲存,SynthID產生的浮水印也不會消失。目前SynthID仍為測試版,初期將提供給Google Cloud上少數使用Imagen的Vertex AI客戶。(詳全文)

Neo4j 向量搜尋 圖學
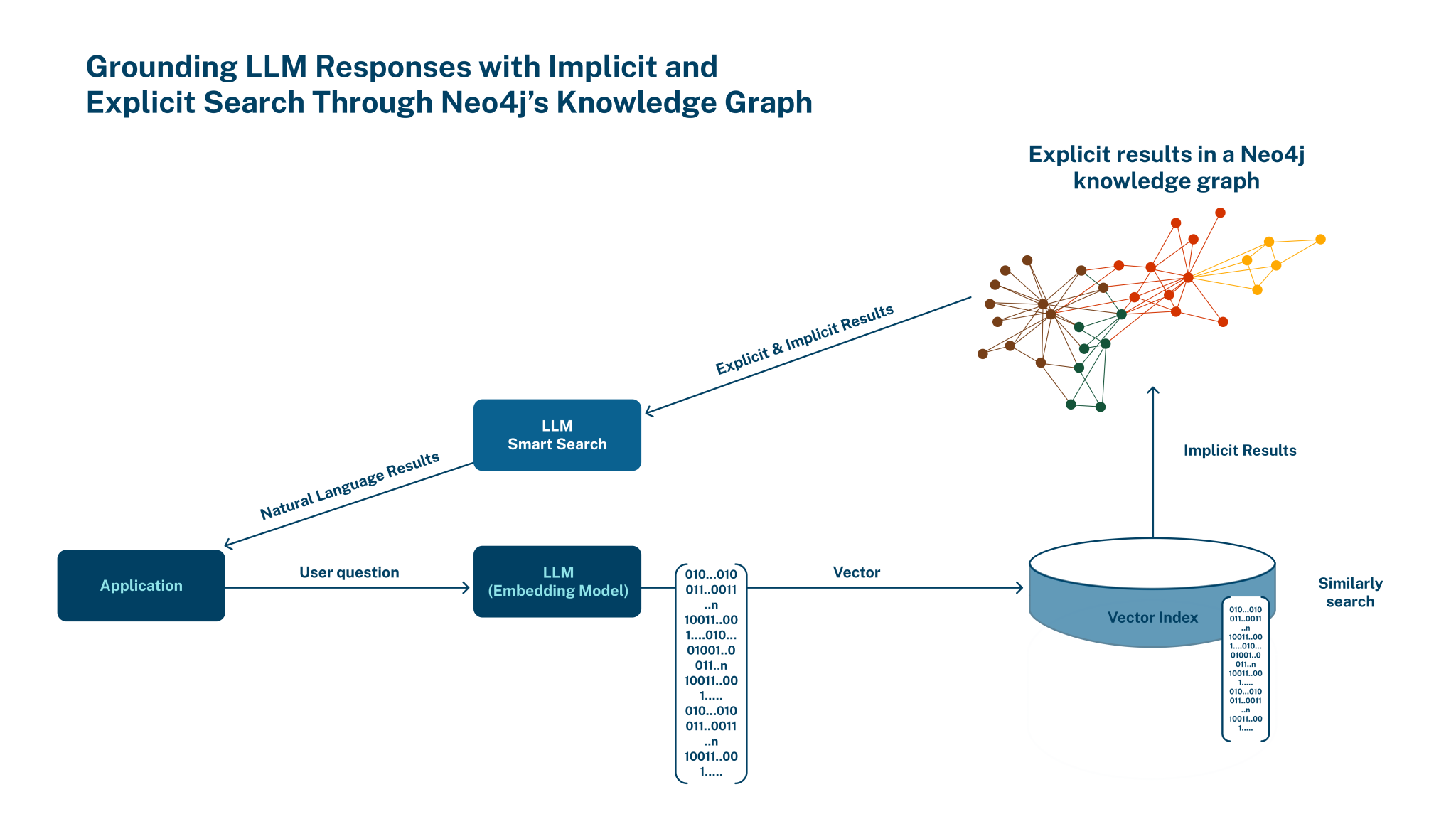
讓生成式AI說話更有憑有據!知名圖資料庫Neo4j新添向量搜尋功能
財星100大公司有超過75家企業使用的熱門圖資料庫Neo4j,最近推出向量搜尋(Vector Search)新功能,能快速搜尋上下文相關資訊,找出隱藏在資料點中的隱藏關係。這種透過向量搜尋所找到的資料,不是單純比對關鍵字,而是進一步理解單詞背後的意義,讓使用者從生成式AI中獲得更豐富的資訊。
結合Neo4j的知識圖譜和向量搜尋功能,使用者能以Grounding技術,進一步改善大型語言模型回應的精確度。Grounding在語言模型中的意義,是將模型的知識或回答,與具體且可信的資料相關聯,讓模型能提供基於事實且與上下文相關的回應。開發者可用特定模型,將各種資料型態(如文件、影片、音訊或圖像)編碼成向量,再以Neo4j建立向量索引,選擇使用餘弦相似度或歐幾里德相似度,來快速執行近似K-近鄰演算法(KNN),找到與特定向量相似的向量。(詳全文)
AlloyDB 生成式AI 資料庫
Google資料庫服務添功能,企業能更快打造生成式AI應用
最近,Google在自家雲端年會上宣布,資料庫服務AlloyDB加入新功能AlloyDB AI,內建向量嵌入端到端支援,讓企業可更簡單地在大型語言模型中應用即時營運資料,來打造高效能、可擴展的AI應用程式。
AlloyDB是Google針對企業資料庫工作負載需求,而開發的資料庫服務。它相容於PostgreSQL,具Google雲端基礎設施優勢,可橫向擴展運算與儲存,並支援AI/ML功能。AlloyDB處理交易工作負載的速度是標準PostgreSQL的4倍,分析性查詢的速度更是PostgreSQL的100倍。現在,AlloyDB支援生成式AI應用,AlloyDB AI允許用戶用簡單的SQL函式,在資料庫內生成向量嵌入,並以標準PostgreSQL資料庫10倍的速度執行向量查詢。這項功能可擴展大型語言模型的能力,提供準確且新穎的資訊。AlloyDB AI現已在本地端版本AlloyDB Omni中預覽。(詳全文)
生成式AI Duet AI 辦公
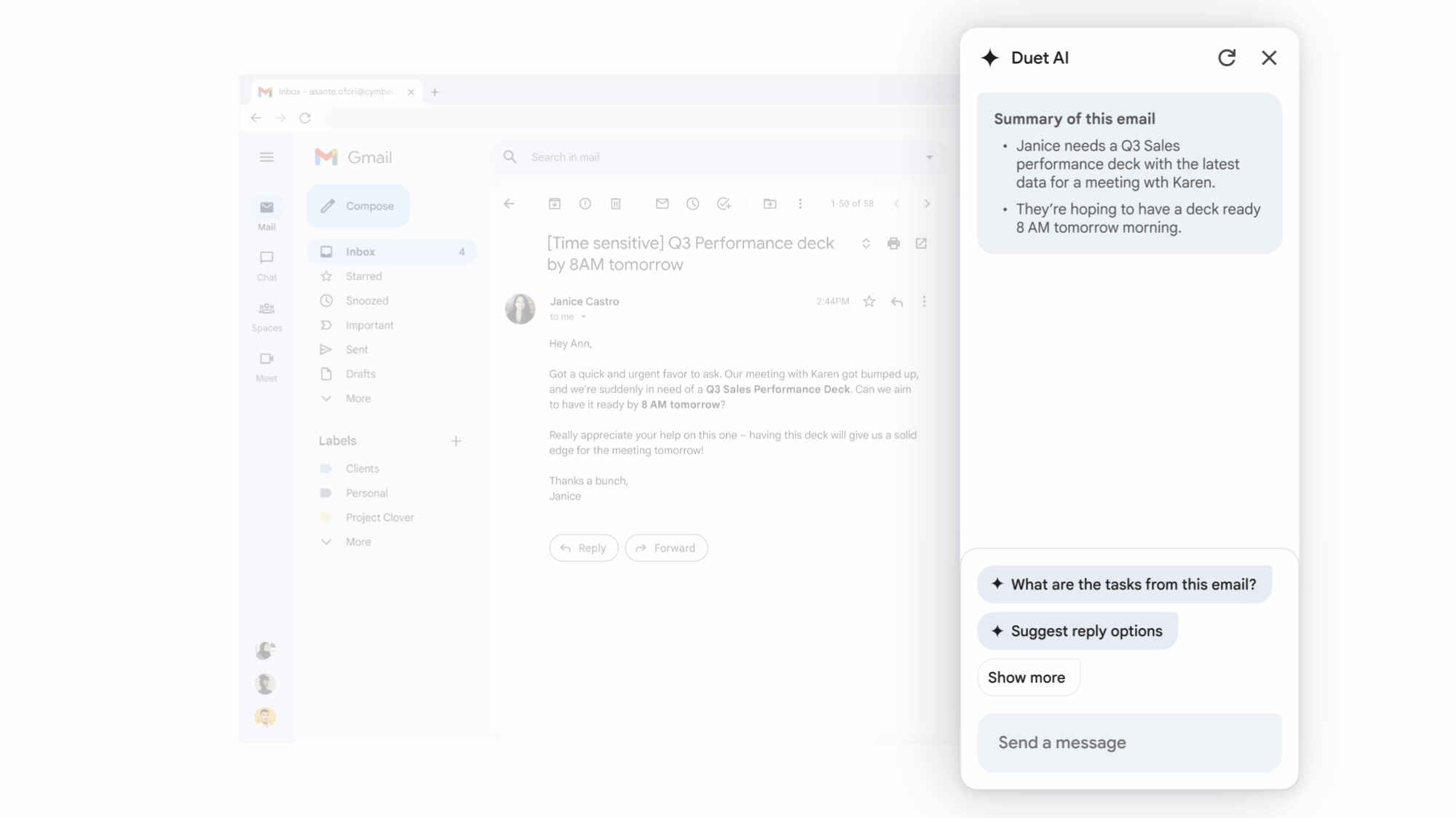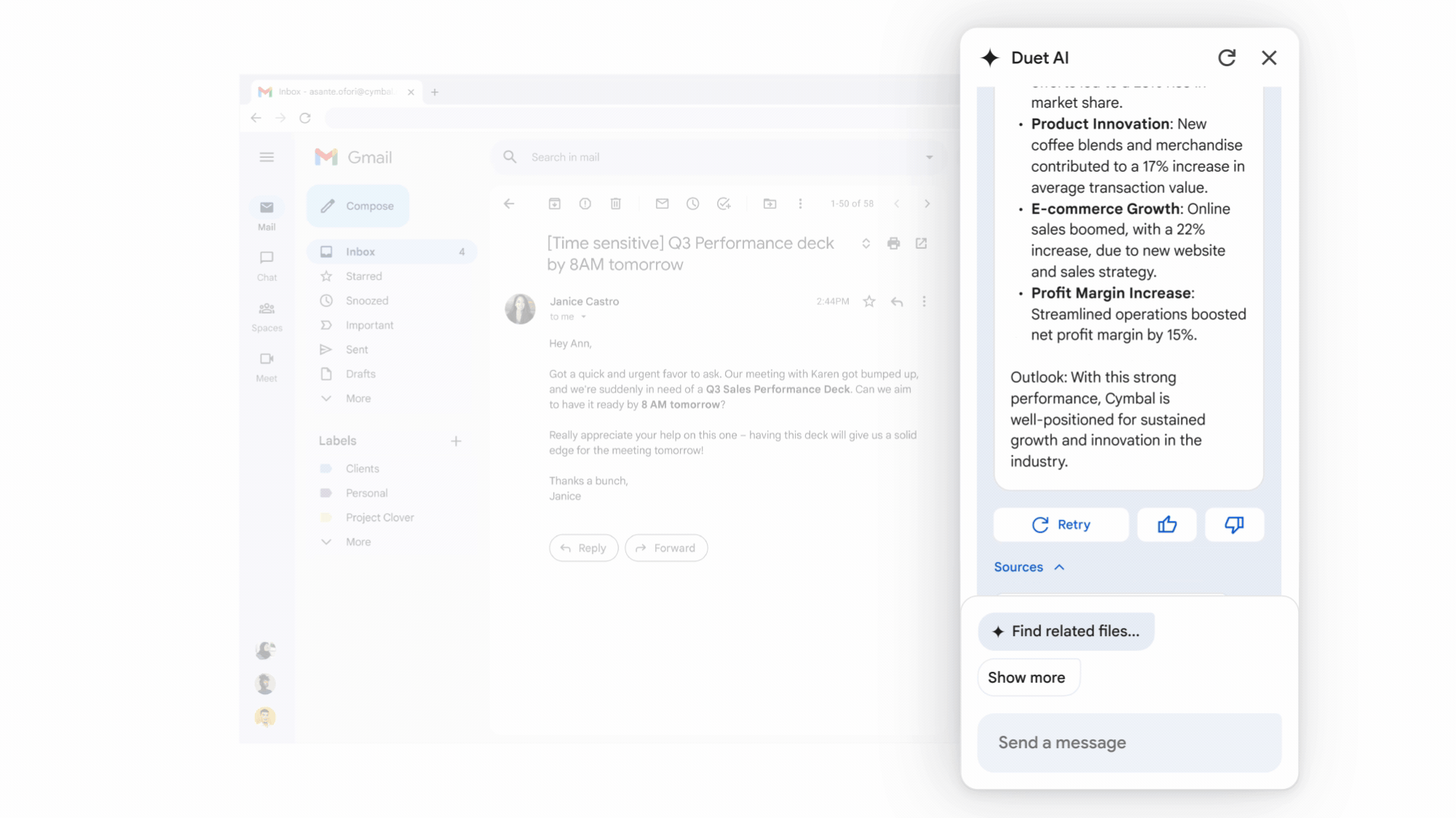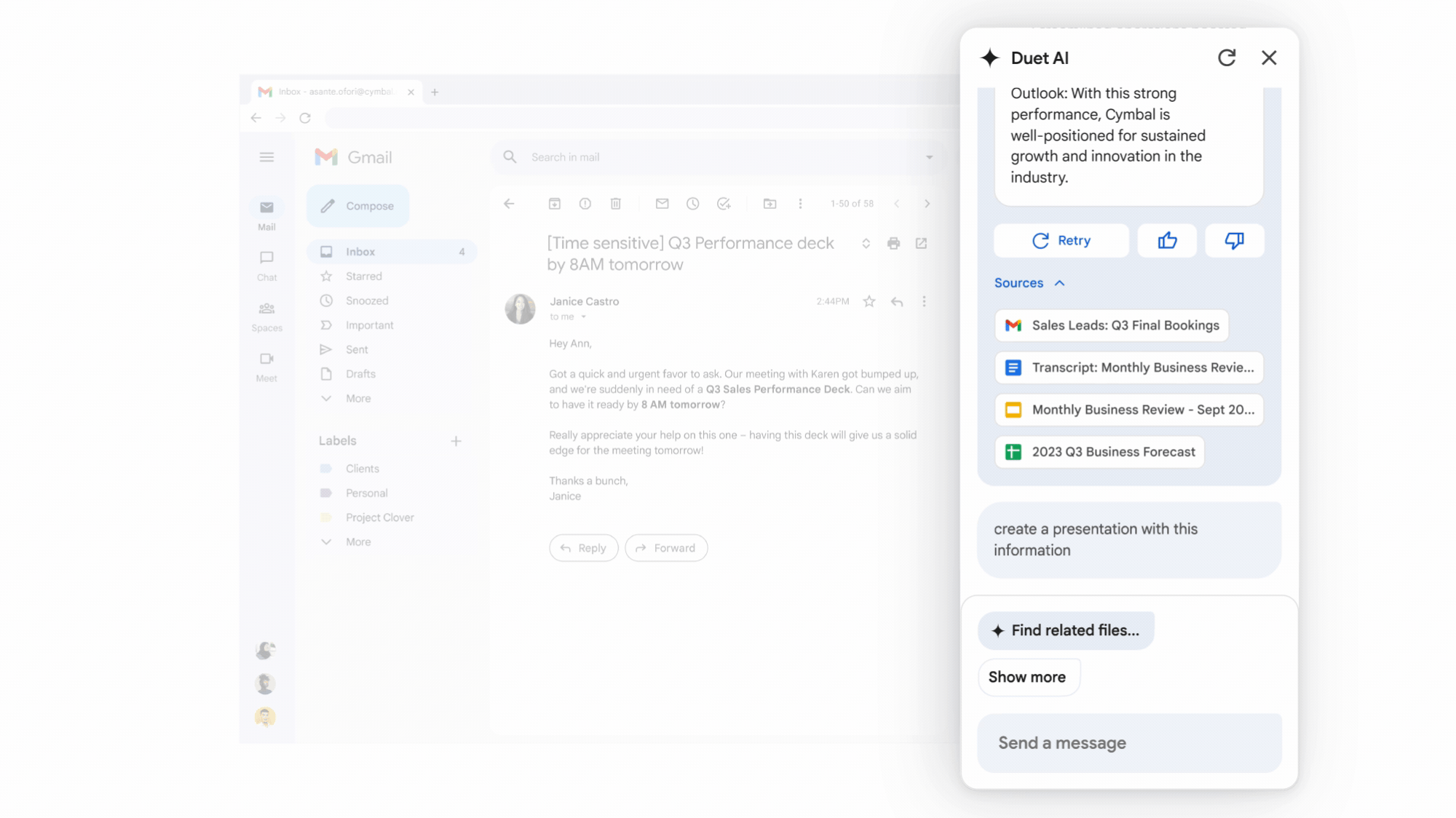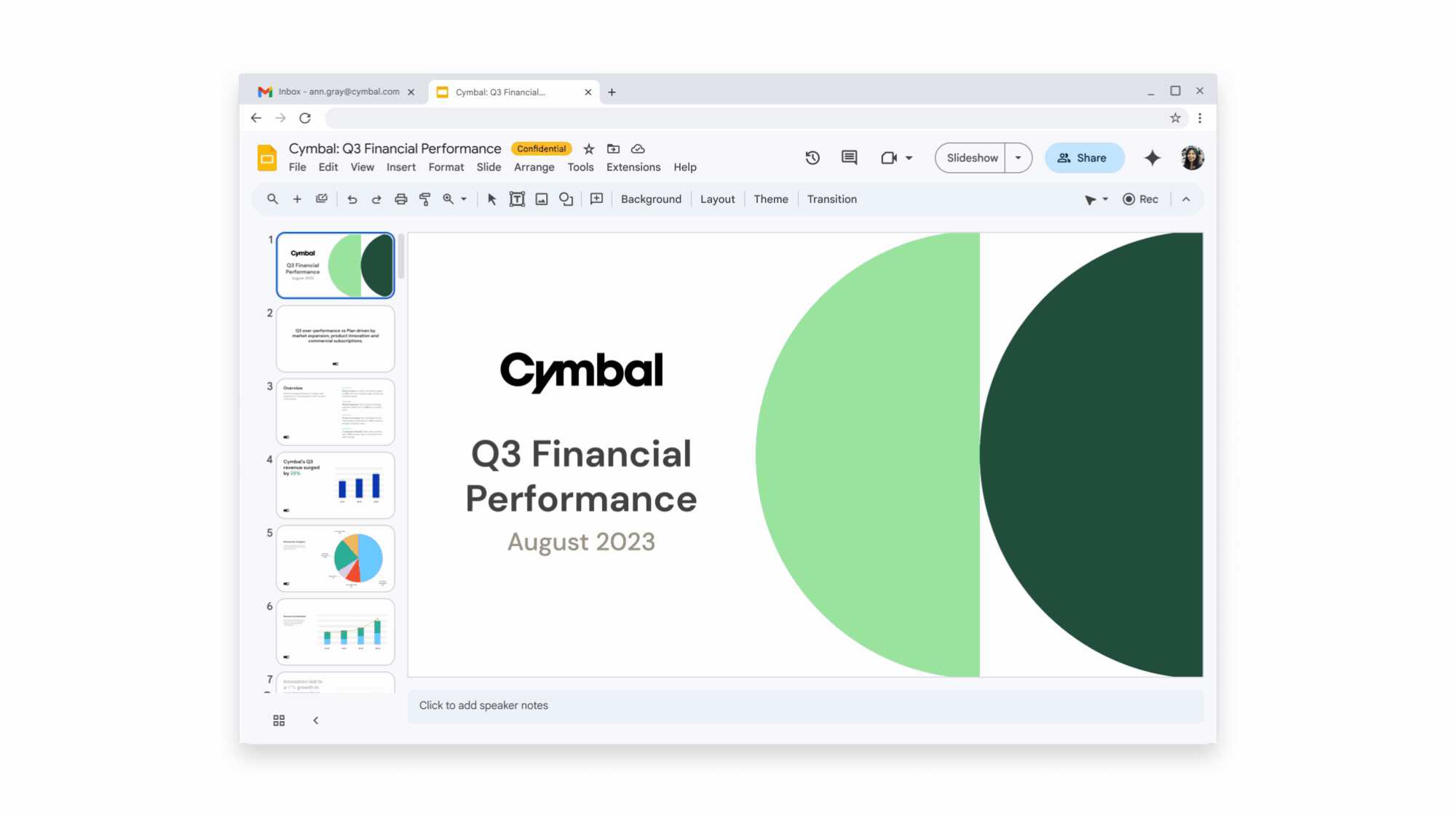
Google Workspace生成式AI助理Duet AI正式上線
Google在自家雲端大會Cloud Next '23上揭露,用於辦公生產力工具Workspace的生成式AI助理Duet AI正式上線,企業版訂閱費為每人每月30美元。在今年5月Google I/O年會上,Duet AI就首次亮相,可在Workspace中的辦公工具,如Gmail、Google Docs、Drive、Meet和Slides等,提供撰寫或潤飾文章、製作原創圖片、製作簡報等功能,甚至是為Google Meet視訊電話生成背景。
Google表示,Workspace現有千萬家付費客戶,用戶超過30億,而自5月開放Duet AI試用以來,迄今已有上百萬人透過信賴測試員方案測試。除了之前宣布第一波功能,Google這次也發布新功能,包括在Google Meet視訊會議中記筆記、傳送會議重點,即時翻譯18種語言,還加入專業錄音室等級的影像、燈光及聲音效果,並辨識臉部,為與會者提供個別視窗。而且,在Google Chat中,用戶可直接和Duet AI對話,包括語音模式。(詳全文)
AI指引 生成式AI 公務員
公務人員使用生成式AI有法可循,國科會發布參考指引
國科會在8月31日提交「行政院及所屬機關(構)使用生成式AI參考指引(草案)」給行政院會,獲行政院認可。該指引適用於公營事業、公立學校、行政法人及政府捐助的財團法人,規範了這些機構使用生成式AI應遵守的10項原則。
其中重要的規範包括,使用生成式AI產生的內容,應由承辦人員依客觀及專業進行判斷,不可取代承辦人自主思維。機密文書應由人員親自撰寫,禁止使用生成式AI。另外,承辦人員不可向生成式AI提供公務上應保密、未經個人或機關同意公開的資訊,也不能向生成式AI詢問涉及機密資料、個資的問題。而且,若機構採用地端部署,還需確認系統環境安全性,再依機密等級分級使用。該指引還要求,機關若使用生成式AI作為業務執行的輔助工具,應適當揭露。行政院指示國科會持續觀察全球AI發展趨勢,來滾動調整。(詳全文)
圖片來源/微軟、Meta、DeepMind、Neo4j、Google
AI近期新聞
1. 蘇黎世大學開發AI無人機系統Swift,勝過3名世界冠軍
2. Meta開源可用來偵測AI歧視問題的FACET資料集
3. OpenAI推出ChatGPT Enterprise服務
資料來源:iThome整理,2023年9月
熱門新聞

2026-02-26

2026-02-27

{kind=link}

2026-02-27
")
2026-02-27

2026-03-02

2026-02-27
2026-02-27