圖片來源:
Line日本
Line日本總部本周宣布開源自有開發的日語大型語言模型(LLM)。
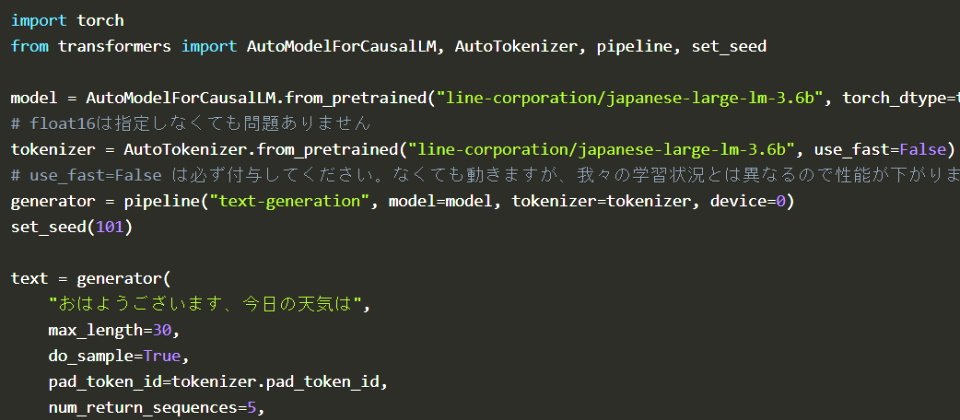
Line將以Apache License 2.0授權開源其japanese-large-lm模型,除了研究用途外,也允許商業用途,包含36億及17億個參數2個版本,兩項專案都可以在HuggingFace Hub存取。
Line自2020年11月起,即致力於針對該公司大型語言模型HyperCLOVA,啟動多項構築和應用相關研發計畫。Line於2021年5月開發者大會上,首次公開2,040億個參數訓練而成的韓文版LLM HyperCLOVA,11月則公布日語特化版,擁有850億參數,並宣稱將以其發展一系列自然語言處理服務。
而本次公開的japanese-large-lm模型是和HyperCLOVA由不同部門並行開發,前者即是Massive LM團隊的開發成果。團隊指出,本模型是用了Line自己的日語大型Web文本為基礎來訓練,並利用成員自行開發的HojiChar開源函式庫,來過濾大量原始碼及非日語文字等雜訊,最後用了650GB資料集來訓練。開發時間上,以17億參數版本而言,在A100 硬體上花了4000 GPU時間訓練而成。
研究團隊也提供了本次公開的兩個模型和Rinna-3.6B及OpenCALM-7B模型的準確度和困惑度(perplexity score,PPL)比較數據。
熱門新聞

2026-03-06

2026-03-06

2026-03-09


2026-03-09

2026-03-06


2026-03-09
Advertisement