")
Line揭露HyperCLOVA發展架構,由通用超大規模模型和專精小模型兩類模型作為核心引擎,來驅動前端AI資料處理系統Explorer和NLP開發工具Studio。(圖片來源/Line)
在2021年開發者大會上,Line揭露了一款超大語言模型HyperCLOVA,宣布要以這個模型,發展一系列企業級的自然語言處理(NLP)服務,包括用來快速打造NLP應用程式的Studio,以及用來處理NLP訓練資料的Explorer,甚至還有一套AI Filter來過濾模型輸入和輸出值,替企業把關產出品質。
擁有820億參數,語音助理、開放式對話、標語生成都能做
這不是HyperCLOVA首次亮相。早在今年5月,Line母公司Naver就在自家AI大會上揭露HyperCLOVA,號稱韓文版GPT-3,用2,040億個參數訓練而成,比GPT-3的1,750億參數還要多。幾個月後的現在,經過Naver和Line共同改良,HyperCLOVA再次現身重量級大會,不同的是,Line揭露的HyperCLOVA懂的語言更多,還更有完整的產品生態系藍圖,以及更多的實用案例。
比如,大會現場,Line AI執行長砂金信一郎就親自示範以HyperCLOVA優化的虛擬YouTuber絆愛,來與真人即時問答互動,就連能自動打電話訂位的虛擬助理AiCall,也由HyperCLOVA驅動。甚至,Line NLP團隊經理Toshinori Sato秀出一段自己與HyperCLOVA聊天機器人的對話,對話角色包括他自己和擬人化的商品色鉛筆,當他詢問色鉛筆「你是什麼顏色」時,色鉛筆回答「我是紅色」,當他問「你喜歡什麼顏色」時,它說「藍色,因為藍天和海洋很美麗,不是嗎?」這個簡單的示範,點出了HyperCLOVA作為商品聊天機器人的應用潛力,企業可用來開發專屬機器人,回覆顧客對商品的各種問題。
這款HyperCLOVA具有820億個參數,是大型多語言模型,正處於整體發展藍圖的第三階段。這代表,HyperCLOVA已走過只精通日文、規模達130億參數的第一階段,也經過390億參數的多語言模型第二階段。而且,HyperCLOVA在第二階段,就與BERT大型日文模型表現相當,準確度只差1.65(85.03對86.68)。明年,HyperCLOVA還要從第三階段邁入最後階段,不只要達到2,040億參數規模,還要成為超大規模(Hyper-scale)模型。
自建語料庫3原則透露商品化野心,用小樣本學習保有通用力
要訓練如此龐大的HyperCLOVA,得先建立一套語料庫。Toshinori Sato點出,Line收集語料有3個原則,第一是不從Line任何對話服務中取得資料(包括Line社群功能OpenChat),再來是確保語料多樣性,最後是建立語料庫子集,如此才能將語料庫用於Line以外的服務。這3個原則,也凸顯Line要以HyperCLOVA發展AI產品的決心。
在這些原則下,他們以NLP經典開源預訓練模型BERT的2019年資料集為語料庫基礎,再以爬蟲方式收集Line搜尋的文字資料,同時購買外部資料,並確保這些資料來自重要的網站,讓模型學習各種日文表達方式。Toshinori Sato強調,Line團隊特別注重個資,語料庫中任何與個資相關的訊息,都會刪除。
經過一年多努力,這個語料庫目前累積到1.8TB大,擁有100億個樣本,Token數量達到5,000億個。雖然Line未透露太多HyperCLOVA的模型架構細節,但可以看出,有別於直接拿BERT來微調下游任務的NLP圈常見作法,Line重新打造一套屬於自己的大型預訓練模型。Toshinori Sato表示,BERT雖然只需依使用者需求,用特定任務資料集來簡單微調下游任務(如翻譯、問答),就能享有SOTA模型準確度,但,使用者還是得按不同任務,建立專屬小型資料集來微調BERT,這種監督式學習方法,可能讓BERT喪失通用能力。
為保有通用力,設計HyperCLOVA時,Line就決定要讓它可透過小樣本來學習(Few-shot learning),甚至是單樣本(One-shot)和零樣本(Zero-shot)。意思是,在小樣本的情境中,開發者只需給定一個任務描述和少數示例,HyperCLOVA就能以這些樣本來學習解題。在單樣本學習中,開發者給定任務描述和一個示例,模型即可學習,甚至在零樣本中,只需提供任務描述即可,不需任何示例。這麼做,HyperCLOVA可根據簡短的描述或少量樣本來解決各種任務,更貼近一般企業的需求。
這就是Line的HyperCLOVA計畫。他們希望,靠HyperCLOVA一個大型模型,就能利用多種資料,來解決多種任務,扭轉過去「一種資料來源-一個模型-一個任務」的窘境。Toshinori Sato舉例,過去,要解決搜尋任務,只能用搜尋模型來分析網頁資料,產出所需的搜尋結果。或是,要用購買紀錄進行商品推薦和顧客關係維護時,得分別打造兩套模型,一套用來推薦,另一套用來維持顧客關係,即便兩者的資料來源都是一樣的,還是得用兩套模型分析。
「我們希望用一個大型模型來處理各類資料、執行各種任務,」他舉例,這個超大模型要能分析網頁資料、購買記錄、交易紀錄、語音輸入,並用這些資料來執行搜尋、問答、商品推薦、需求預測、對話等任務,至少先解決這些任務共通的NLP問題。這個方向,定下了HyperCLOVA的發展基調。
當引擎驅動兩大應用系統,還要打造企業通用AI生態系
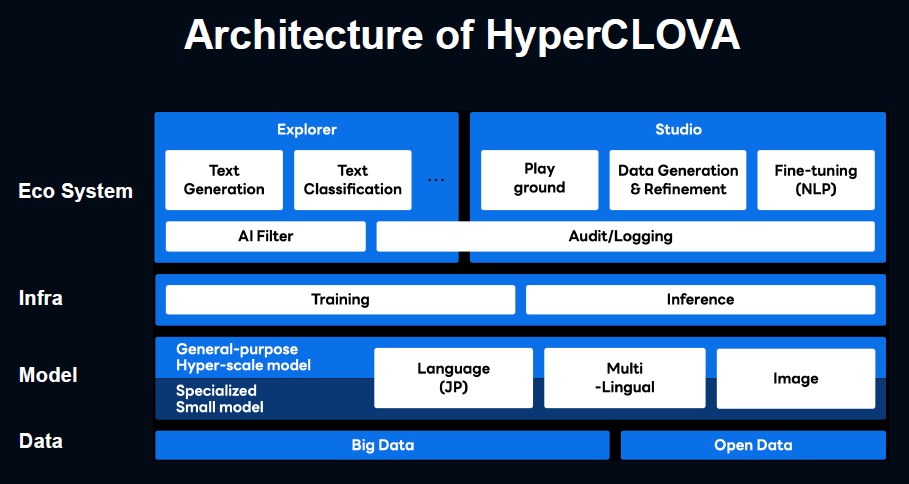
圖片來源_Line
大會上一張HyperCLOVA的發展架構圖,清楚點出未來產品路線。在這張架構圖的最底層,是驅動一切服務的資料層,包括各類大數據和開放資料。在資料層之上是模型層,也是HyperCLOVA模型所在處。這層包括了兩類重要模型,分別是通用的超大規模模型,以及專精各類任務的小型模型,包括日文模型、多語言模型、影像模型等。
模型層之上是基礎架構層,包含模型訓練與推論,再往上就是HyperCLOVA所驅動的前端應用系統,包括Explorer和Studio。其中,Explorer專門用來處理AI訓練資料,比如文字資料生成、文字資料分類,讓使用者用來打造AI模型。特別的是,Explorer中還搭配一套AI Filter控管機制,來把關模型的輸入值與輸出值,同時確保HyperCLOVA不被濫用。Studio則是更應用導向的NLP開發工具,它有三大功能,包括用來開發NLP應用的沙盒環境Playground,以及資料生成和強化功能,還有NLP模型微調功能。這些功能都以HyperCLOVA驅動,目前最成熟的功能就屬Playground。
Playground可以怎麼用呢?Toshinori Sato在會場上,展示一款以Playground打造的廣告文宣生成應用程式。在這款應用程式中,使用者可輸入自家產品名稱、一句摘要(如產品成分、產地)和說明,系統就會產生一段產品文宣,使用者可調整溫度(Temperator)、重複排除(Repeatition Penalty)和最大詞彙量(Maximum Tokens)等參數,來調整文宣內容。

HyperCLOVA Studio中的Playground有如沙盒環境,使用者可用來開發各類NLP應用,比如打造一個快速生成產品廣告文宣的應用程式,只要輸入產品名稱和簡短摘要,就能產出文宣內容,使用者還可調整參數來變更內容。圖片來源_Line
這個只需輸入單項產品資料、就能產出文宣的功能,就是運用HyperCLOVA單樣本學習的能力。但這只是Playground的範例之一,企業可用Playground來開發多種NLP應用。今年,Line也將開放開發者試用Studio,並釋出Python SDK,要讓大家都能使用。
不過,在Line的技術戰略中,NLP應用只是第一步。Line預告,接下來要結合電腦視覺技術,賦予HyperCLOVA「看」的能力,既要能看懂影像,也要懂影像中的文字,比如將多模態AI納入主打的OCR服務,讓AI辨識圖片中文字,還能理解文字含義,甚至,Line要進一步將推動工作流程自動化,利用影像辨識和NLP能力,來自動化法律合約檢視與修改。他們的目標是,用一個模型解決多模態任務,打造MiLAI(Mixed Line),往通用AI邁進、打造更完整的AI產品生態系。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02