
史丹佛大學設計陪審團學習方法,先訓練分類器來模擬不同身分標註者的貼標行為,再以虛擬陪審團機制的組合,來驗證效果。
史丹佛大學
重點新聞(0805~0811)
史丹佛大學 陪審團學習 偏差
史丹佛研發陪審團學習方法,要解決標註者分布不均造成的ML偏差問題
史丹佛大學團隊研發一種陪審團學習方法,可控制ML模型輸出值的偏差(Bias),不受到標註者的身分背景影響,例如因標註者的年齡、性別、教育程度、居住地不同而帶來的標註偏差。
他們先是訓練分類器,來模擬不同標註者的標註行為,如女性、黑人,而不像常見的分類器,只模擬一般標註者行為。這種分類器,還能讓使用者依其所需,產出特定標註者的標籤,來對訓練資料貼標。
在實作上,團隊利用社交平臺留言資料集來訓練分類器,讓分類器模擬不同標註者,對這些留言給出的惡意性評分。該資料集包含了17,280位標註者,對留言的惡意性評分(0至4分),每位標註者也提供自己的年齡、性別、種族、教育水準、政黨派別,以及是否為人父母和宗教信仰等特徵。接著,團隊利用BERTweet模型來產生每條留言的表徵,再將這些表徵集結起來,作為Deep & Cross類神經網路的輸入值,來產出不同標註者對留言的評分。在推論上,團隊設置特定特徵組成的虛擬陪審團,讓模型隨機挑選12合適的位標註者,來預測評分,並經多數決選出最佳標籤。團隊發現,模型平均絕對誤差為0.61,在預測不同種族標註者時,模型也有一致的錯誤率,如亞洲人0.62、黑人0.65、西班牙裔0.57、白人0.6。
AI專家吳恩達評論,陪審團學習方法雖能減少一些偏差,且能確保生成的標籤代表不同觀點,但這個方法,不會減少在人口群體中普遍存在的偏差。後者的問題需要另一種解法。(詳全文)
招潮蟹 MIT 電腦視覺
模擬招潮蟹!MIT專家打造出陸地水下都能看的360度人造眼
MIT電腦科學與人工智慧實驗室CSAIL聯手首爾國立大學,打造一款可同時分辨陸地和水下景象的仿生人造眼系統,外形有如一個黑色的小球,透過混合材質來處理光線訊息,視野不再只限於半球形,而是近360度的全景視角。
團隊表示,這款人造眼是受招潮蟹啟發,因為招潮蟹有獨特的視覺系統,平坦的角膜和漸變折射率處理能力,可解決因外部環境變化而產生的散焦,此外,特殊的眼睛結構還讓招潮蟹具備3D全景視角。因此,團隊將一系列具漸變折射率分布的平面微透鏡,以及梳狀的柔性光電二極管陣列,整合分布在一個3D球體上。
如此,就算光線從多處射出,也會聚集在圖像感測器的同一點上,不論周遭折射率如何變化。為測試系統,團隊將這個人造眼半浸於水中,並在水陸和不同距離之處擺設5個物件。他們發現,不論陸地還是水下,系統可呈現一致的圖像品質,也能呈現近乎360度的陸地和水下景象。(詳全文)

Meta 聊天機器人 BlenderBot 3
Meta開發新演算法Director,要讓新一代Chatbot談吐更有禮貌
Meta以自家的語言模型OPT-175B為基礎,開發出1750億參數的新一代聊天機器人BlenderBot 3,效能比第二代要好31%,再加上以58倍大的資料庫來訓練,第三代的知識量是前一代的2倍,錯誤率則降低47%。
為了讓BlenderBot 3不受有心人濫用、說出沒禮貌的回應,Meta設計一款新學習演算法Director,可利用語言建模和分類方法,來產出BlenderBot 3給用戶的回應。其中的分類器,可訓練來處罰低於標準、有害、矛盾或重複的言論,團隊測試發現,這種方法比獎勵學習機制、重新排名和傳統語言建模方法要好。(詳全文)

電腦視覺 物件偵測 ViTDet
Meta開源新電腦視覺模型,可偵測更多不常見物件
Meta發表最新物件偵測模型ViTDet,經LVIS資料集測試的表現,比其他基於ViT的模型還要好。ViTDet不僅能偵測桌椅等標準物件,還能找出如餵鳥器、花圈和甜甜圈等較不常見的物品。這項研究之所以重要,是因為物件偵測是一項重要的電腦視覺任務,而物件偵測要更有用,就得辨識出更多不常見的物件,或是在訓練資料中很少出現的物件。
有別於傳統方法,Meta僅從單一尺度的特徵圖,就可建構簡單的特徵金字塔,不需用到過去常見的FPN設計,直接用ViT最後一層特徵,就可重建FPN,這種作法更簡單直覺,更不耗費記憶體,訓練和推理的速度也更快。Meta現已開源ViTDet程式碼和訓練方法。(詳全文)

牙周病 影像辨識 TFDA
牙醫科技新創打造牙周病判讀AI,今年拼TFDA取證
國產牙醫科技新創台灣牙e通(dentall)打造牙科影像判讀AI,不只能判斷基本的口腔X光片牙位、分辨牙齒位置和牙肉,還能預測蛀牙病灶和牙周病期別,其中牙周病預測準確率達97%。
2019年,他們與北醫聯手,透過北醫提供去識別化且經標註的牙齒影像,來訓練AI模型。第一階段,他們先訓練模型辨識牙位,比如上下左右排牙齒,目前已能取代人力,自動將散亂的影像自動排序。接著,模型進一步學會辨識牙肉與牙齒位置,有這些基礎後,他們開始打造牙周病偵測AI,根據牙肉和牙齒露出牙肉的比例,以及美國牙周病學會標準,來計算牙周病期別。今年,他們準備申請衛福部食藥署智慧醫材SaMD認證,下一步要整合保險給付,比如模型判斷出第3期別,需要牙周病再生治療,就可整合保險端來簡化給付作業。(詳全文)

Amazon 小樣本學習 Transformer
Amazon小樣本學習模型勝過千億參數大模型
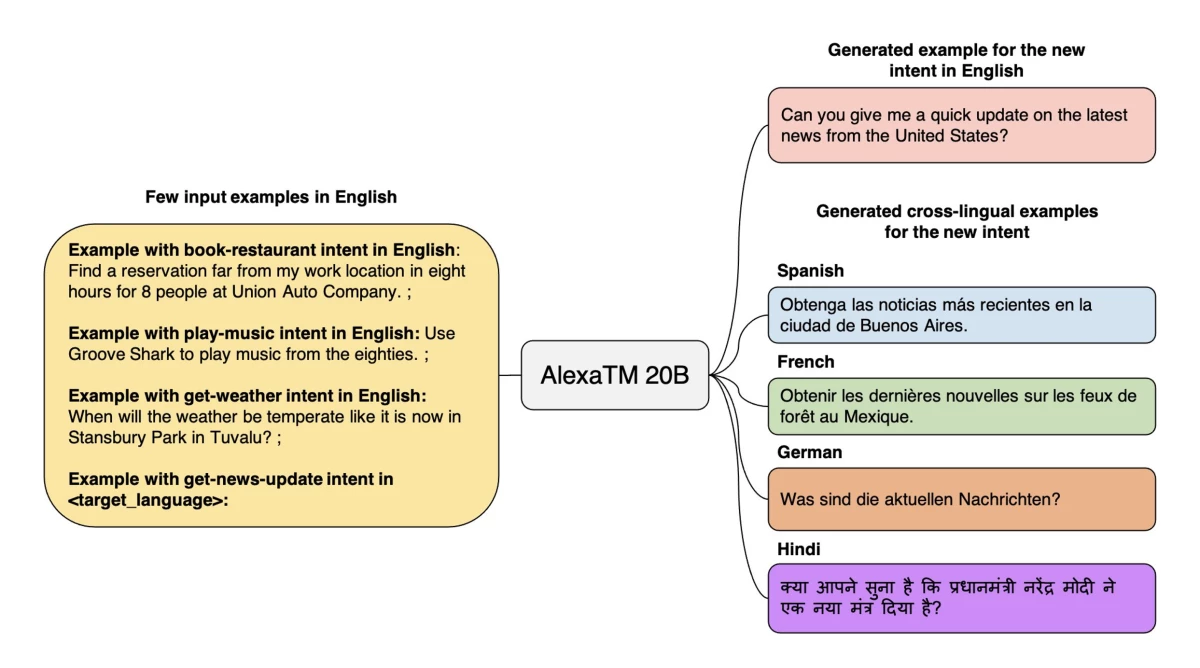
Amazon改良Alexa AI,開發出200億參數的語言模型AlexaTM 20B,只需少量人工輸入,就能在不同語言間,轉移已習得的知識。進一步來說,AlexaTM 20B是以Transformer架構為基礎,只需給幾個任務提示,AlexaTM就能將已學習的知識或任務,從一個語言轉移到另一個語言,且不需要額外的人工標註。
AlexaTM 20B具200億參數,在多種語言任務上優於上千億參數的大模型。有別於大部分Transformer架構的語言模型、只採用解碼器,AlexaTM 20B採序列到序列(seq2seq)的編碼器-解碼器架構,在翻譯和文本摘要的效果優於GPT-3,還支援更多語言,像是阿拉伯語、英語、法語、泰米爾語和泰盧固語等。由於AlexaTM 20B的參數數量較少,再加上Amazon對訓練引擎的改進,AlexaTM 20B在訓練期間的碳足跡,只有GPT-3的五分之一。(詳全文)
印度 即時監控 影像辨識
印度導入AI強化邊境即時監控和社交平臺危險偵測
印度軍方近日宣布導入一套AI系統,來即時監控北部和西部的邊境狀況,以及偵測社交平臺活動,來即時掌握危機狀況。進一步來說,印度與中國、巴基斯坦接壤,長年以來存在不少邊界衝突,為此,印度計畫重用AI來強化軍事能力。比如,他們已採用人臉辨識、語言翻譯(中文到英文)、遠程武器操作站、探雷機器人和入侵偵測系統等,來加強軍事防禦。
而這次導入的AI系統,則搭配印度可疑車輛登記系統,再加上可轉動視角的監視器和熱成像監視器,來即時偵測可疑車輛,並通知士兵阻攔。印度媒體稱,該系統已於8區域上路。(詳全文)
圖片來源/MIT、Meta、Amazon
攝影 / 王若樸
AI近期新聞
1. 英國未來2年要建無人機專屬高速公路
2. CMU開源ML工具來解決時序事件問題
資料來源:iThome整理,2022年8月
熱門新聞

2026-03-13

2025-06-02

2026-03-17

2026-03-17


2026-03-17

2026-03-14

2026-03-16