
DeepMind聯手歐洲分子生物學實驗室,開源新版蛋白質結構預測資料庫AlphaFold DB,包含2.14億個蛋白質結構,幾乎涵蓋地球上所有蛋白質,要讓研究者快速查詢預測模型、將精力集中在實驗上。
DeepMind
重點新聞(0722~0728)
本周開源圈有不少亮眼成果,像是DeepMind釋出新版蛋白質結構預測資料庫AlphaFold DB,含2.14億個蛋白質結構,幾乎涵蓋世界上所有蛋白質;其他還有Meta的文獻引用查核比對工具、蘋果的輕巧影像辨識骨幹網路、Hugging Face的千億參數語言模型BLOOM等。在企業應用上,eBay最近分享自家低程式碼/無程式碼AI工具,讓賣家用來把商品照片轉換為3D影像,提供更好的買家體驗。
DeepMind 蛋白質結構 AlphaFold DB
DeepMind釋出2.14億個蛋白質結構新資料庫,幾乎涵蓋地球上所有蛋白質
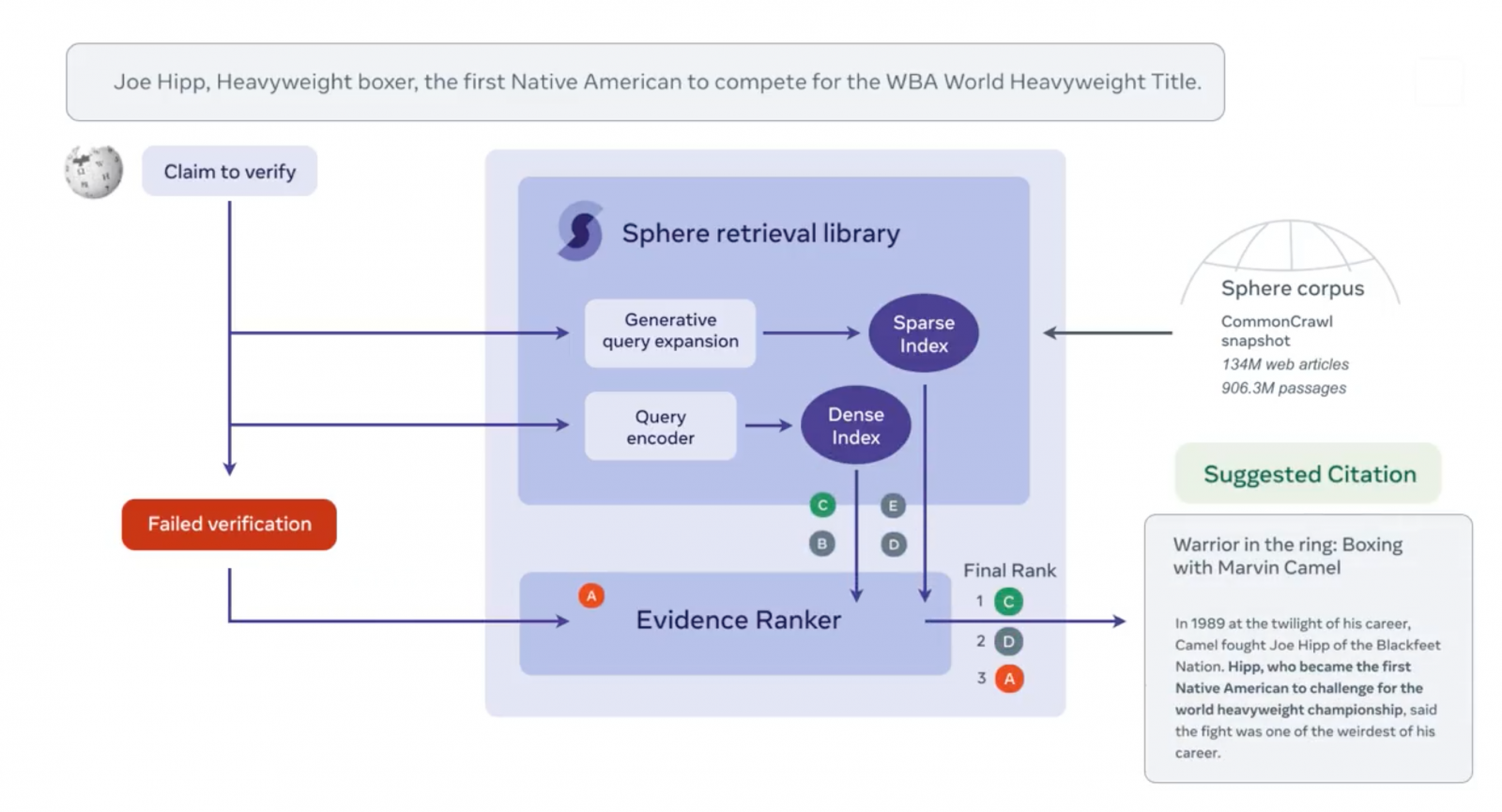
DeepMind近日宣布釋出新蛋白質結構資料庫AlphaFold DB,共含2.14億個蛋白質結構,幾乎涵蓋地球上所有蛋白質。DeepMind指出,該資料庫就像是蛋白質結構界的「Google搜尋」,研究者可用來即時尋找蛋白質預測模型,然後把精力集中在實驗工作上。
該資料庫是DeepMind與歐洲分子生物學實驗室的歐洲生物分子訊息研究所(EMBL-EBI)聯手擴展而成。1年前,DeepMind開源蛋白質3D結構預測模型AlphaFold,快速預測和準確率高的能力,讓AlphaFold被譽為是解決生物學家50年來難題。當時,DeepMind也開源了AlphaFold DB,只不過,1年前的資料庫只涵蓋了100萬個結構,而現在擴大到2.14億個,等於增長超過200倍,納入了植物、細菌、動物和其他生物的蛋白質結構。
DeepMind認為,這個增長可加速專家對生物學的研究,可幫助食物安全、疾病、新藥發現和永續性等領域研究。甚至,他們發現,AlphaFold模型開源1年以來,也有不少研究者,拿來加速塑膠分解、抗生素抗藥性等問題的研究。(詳全文)
.svg)
Meta 文獻引用 翻譯
查核文獻引用更容易了!Meta開源模型能自動比對數十萬條引用
Meta最近開源一套AI模型,可一次比對數十萬條文獻引用(Citation),來判斷是否支援內文說法。該模型用1.34億篇網頁訓練而成,能標示出可能不適當的引用,讓審核人員快速查驗,不必一一比對所有文獻引用。當模型偵測到,文獻引用與內文無關時,還會推薦更相關的引用,甚至標示出支持內文說法的文獻段落,來加速人工審核。
維基媒體基金會董事會副主席暨特拉維夫大學講師Shani Evenstein Sigalov表示:「這是個強而有力的機器學習工具,透過提供準確的引用和來源,來幫助志願者加速進行更多核對工作。」他認為,改善這些流程,能吸引更多編輯者,來提供更好的維基百科內容。
進一步來說,Meta自2020年開源可同時進行訊息檢索和驗證的AI模型後,就致力於打造可學習更細緻語言表徵的類神經網路,好在廣大的網路中,找到相關的資訊來源。這次開源新模型,Meta也同步開源用來訓練模型的網頁資料庫Sphere,包含1.34億篇網頁、9億多個段落,每個段落都有100個Token,供AI研究者來進行各種檢索技術實驗。(詳全文)
eBay 3D渲染 元宇宙
eBay用低程式碼平臺,讓賣家上傳產品照自動轉為3D物品
eBay前風險和信任資深總監Stephanie Moyerman在一場活動中分享,eBay透過一套無程式碼/低程式碼AI工具,來讓賣家上傳商品照片、進行3D渲染,讓買家可從各個角度查看商品。這個工具,也能讓賣家打造新體驗,來提高買家的使用者體驗,減少數位與實體購物的落差。
Stephanie Moyerman解釋,賣家可直接用手機拍攝商品,上傳到eBay雲後便轉換為3D資產。eBay首席AI長Nitzan Mekel-Bobrov指出,過程中,賣家完全不需專業設備就能操作,幾分鐘就能完成。目前,該功能已於運動鞋商品類別推出,接下來要擴大到其他類別。Nitzan Mekel-Bobrov也表示,eBay也正為元宇宙準備,要加強AI在視覺和內容理解的能力,並投資3D和AR等相關工具,以及發展跨平臺兼容性。(詳全文)

MobileOne 蘋果 影像辨識
iPhone不到1毫秒就推論完了!蘋果開源超輕影像辨識骨幹網路
蘋果最近開源影像辨識骨幹網路MobileOne,在裝置端執行AI推論,最快不到1毫秒(iPhone 12)就完成,且在ImageNet資料集上,達到Top-1 75%準確度。
隨著AI模型運算從雲端移往裝置端,越來越多專家投入研發更有效率的骨幹網路,來縮短模型在裝置的推論時間。MobileOne就在這樣的情境下發展,在架構上,它的基本模塊建立於Google小型MobileNet-V1 3×3深度卷積和1×1點卷積,並以過度參數化分支來改善模型表現。在策略上,它採用類似MobileNet-V2的深度擴展方法,因為在推論時不需要多分枝架構,因此不會有資料移動成本,也讓研究員可擴展模型參數,而不會造成顯著延遲。(詳全文)

Google 量子虛擬機器 Colab
使用者可在Colab免費使用Google量子虛擬機器資源了
Google量子AI團隊宣布免費提供量子虛擬機器(QVM)運算資源,使用者可直接在程式碼協作開發平臺Colab上部署QVM,不必等待運算結果之外,還能用來快速迭代程式。
Google表示,QVM能模擬自家實驗室用量子電腦執行程式的結果,從電路驗證到處理器失真都包括在內。再加上類處理器的輸出值,Google認為,QVM是用來打造原型、測試和優化量子電路的絕佳工具,使用者目前可用來模擬Google的Weber和Rainbow等兩種處理器。(詳全文)
Hugging Face 語言模型 BLOOM
Hugging Face開源全球最大的語言模型BLOOM
AI新創Hugging Face釋出1,760億參數的大型語言模型BLOOM ,比OpenAI的GPT-3還大(1,750億參數),並開放各界下載。BLOOM可理解46種語言、13種程式語言,如法文、西班牙文、越南文、中文或多種印度及非洲語言,使用者只要選一種語言,就能要求BLOOM撰寫食譜、翻譯或摘要,也能要求BLOOM寫程式。
BLOOM是目前全球開源的最大語言模型,不只公開所有訓練資料,也發布開發時面臨的挑戰和模型效能評估方法。另一方面,BLOOM也有其它大型語言模型的缺點,比如可能藏匿不準確或有偏見的回答,但該專案採用新的《負責任AI許可》,避免模型用於執法機構或醫療照護等高風險領域,也禁止用來傷害、欺騙、剝削或冒充他人,同時,Hugging Face認為,開源能讓AI社群協助改善模型。(詳全文)

OpenAI DALLE-2 文生圖
OpenAI文生圖模型DALL-E 2擴大測試
繼今年4月發表新版文生圖模型DALL-E 2預覽版後,OpenAI近日宣布擴大DALL-E 2的測試規模,將在未來幾周邀請100萬名使用者免費試用該模型。
受邀的使用者,第一個月可得到50個免費額度,每個額度可用來執行1個DALL-E原始提示,並產生4個圖片,或是獲得一個編輯過的變化提示,可產生3個圖片。之後,每個月能持續獲得15個免費額度。雖然剛邁入測試階段,DALL-E 2已開始支援商業活動,除了每月15個免費額度外,使用者可花15美元額外購買115個額度,且自即日起,使用者將獲得自DALL-E 2產生圖像的所有商業使用權,包括轉載、銷售或商品化等。(詳全文)
圖片來源/DeepMind、Meta、蘋果、VentureBeat、Hugging Face
AI近期新聞
1. 歷時5年研發,Google開源量子程式開發框架Cirq 1.0
資料來源:iThome整理,2022年7月
熱門新聞

2025-06-02

2026-03-13

2026-03-14

2026-03-13

2026-03-13

2026-03-13

2025-04-15
2026-03-16