,來訓練AI模型,來揪出使用者程式碼中潛在的安全漏洞。")
GitHub用先前開發的程式碼掃描工具CodeQL作為貼標器,用來標註10萬多個開放程式碼庫中的程式碼(安全風險),來訓練AI模型,來揪出使用者程式碼中潛在的安全漏洞。
GitHub
重點新聞(0225~0303)
GitHub 安全漏洞 程式碼掃描
GitHub優化程式碼掃描功能,自動揪出潛在安全漏洞
GitHub以先前開發的程式碼掃描工具CodeQL為基礎,利用機器學習來強化這個規則式工具,讓它也能揪出較難察覺的潛在安全漏洞。他們先用已訓練的ML模型,來辨識部分程式碼的安全風險,先確認效果。結果顯示,監督式學習效果較好,GitHub接著用CodeQL當作規則,來判斷數百萬的程式碼片段是否安全,等於輕鬆標註10萬多個開放庫中的程式碼。這些資料,也用來開發模型,作為訓練資料集。
GitHub也設計一套方法,來測試模型是否能偵測新漏洞,而非只限於現有的CodeQL規則。他們用之前產生的標籤來訓練模型,再用CodeQL最近偵測的新漏洞來測試模型,測驗召回率為80%。特別的是,GitHub所用的檢測方法,並不是把程式碼視為文本,以NLP方法來辨識,而是用CodeQL規則來辨識特徵,比如存取路徑、API名稱、封閉函式主體等。(詳全文)
Meta AI 推薦系統 TorchRec
Meta開源用來訓練參數破兆的超大推薦系統函式庫
與NLP和電腦視覺相比,推薦系統相關的開源資源一直是比較少的。Meta旗下AI研究院最近就釋出一款推薦系統專用的領域函式庫TorchRec,內含常見的稀疏性和平行化基本程式碼,開發者可用來打造大型推薦系統,也能用這個函式庫來訓練模型,特別是擁有跨多GPU的大型嵌入式表格。
TorchRec的架構專為大規模推薦AI而生,更用來驅動Meta內部複雜的推薦模型。比如,Meta用它來訓練一套1.25兆參數的模型,今年1月上線,目前還正訓練一套3兆參數的模型,準備在近期上線。(詳全文)
防災 屏東縣 行動數據資料庫
屏東縣政府打造智慧防災系統,分秒就能掌握災情應對
屏東縣政府近日揭露智慧水管理成果,借助大數據分析和AI打造一系列防水災應用系統,將以前需要數天、數小時以上的反應時間,縮短為數分鐘、數秒鐘。
比如,他們有套系統能根據地層下陷區域的淹水深度,來提供快速退水的策略,像是抽水機布設調度和水門操作等。另一個則是全時的預警系統,每小時自動提供未來1至3小時的河道水位早期預警,來保留黃金疏散避難時間。到今年為止,這個預警水系已涵蓋10條共15個鄉鎮。另外也整合34處內水感測器和聊天機器人、智慧定位技術,來打造行動數據資料庫,讓執勤人員快速掌握鄰近地點的水情、災情和建物資訊。(詳全文)


通用翻譯 LASER FLORES
Meta發起通用翻譯專案,要用AI打破語言翻譯障礙
機器翻譯系統在這幾年快速進步,但模型仍需從大量的文本中學習,因此資源稀少的語言,仍然是機器翻譯的一大挑戰。為解決這個問題,Meta做了兩件事,一件是發起No Language Left Behind專案,也就是一套新AI模型,專門針對文字翻譯,能從少量樣本中學習,進行高品質翻譯。適用語言可達上百種,從阿斯圖里亞斯語、盧干達語再到烏爾都語都包括在內。另一件則是通用口譯專案,要即時將源語翻譯為目的語。這個專案,對沒有正規書寫系統的語言非常有幫助。
為自動打造低資源語言資料集,Meta先是開發一套開源工具包LASER,涵蓋125種語言。LASER將多種語言句子整合為單一的多語言表徵。接著,團隊用一個大規模多語言搜尋器,來定位表徵相似的語句,或是不同語言中,意思相似的句子。為克服資料稀缺性,團隊也開發了師生模型,讓LASER可跨多種語言大規模運作。這種訓練方法,也讓LASER能專注從少量樣本學習資源稀缺的語言。
團隊也用LASER來處理語音翻譯,讓使用者可從源語語音和目的語文字間抽取翻譯。Meta也用其他方法來優化模型訓練,提高大模型的訓練效率,同時,這種大量多語言的模型,還需要獨特的基準測試來評估模型表現,因此,團隊也採用涵蓋101種語言的FLORES-101資料集,來評估大量多種語言的翻譯效能。目前,他們一邊改善模型,也一邊擴展FLORES的語言種類。(詳全文)

DeepMind 核融合 發電
DeepMind成功用AI控制環磁機,推進核融合發電研究
Deepmind成功用深度強化學習和模擬環境學習架構,來控制瑞士洛桑的可變配置環磁機(TCV)控制器,順利控制核融合電漿。DeepMind不只能用系統保持電漿穩定,也能精確雕塑成各種形狀,意味著強化學習可用來控制過熱物質,讓科學家更理解核融合反應爐。
進一步來說,在地球上進行核融合很難,一般使用環磁機裝置,在甜甜圈形狀的真空外圍包覆電磁線圈,來把比太陽核心更熱的氫電漿約束在真空中。但這樣的氫電漿很不穩定,控制系統得協調環磁機中的電磁線圈,必須每秒數千次調整線圈電壓。
而Deepmind的深度強化系統能自動控制線圈,將電漿穩定約束在環磁機中。他們先在模擬環境中控制TCV,再在真正的TCV上驗證。在模擬器中,Deepmind以單個神經網路,一次控制所有線圈,自動學習可達到最佳電漿配置的電壓,同時建立一系列電漿形狀,來試驗能量生產的可用性。除了實際驗證都成功外,他們也發現,深度強化學習能實現TCV過去做不到的事,像是在穩定容器內同時維持兩個水滴形狀的電漿;研究員只改變要求,演算法就能自動找到適合的控制方式。(詳全文)

雲象 淋巴瘤 奇美醫院
雲象揭露淋巴瘤偵測AI成果,超高準確度接近最佳演算法效果
專攻數位病理AI的雲象科技與奇美醫院共同打造T細胞淋巴瘤偵測AI,可準確框出淋巴瘤細胞核、計算面積,AUC值達到0.966(完美演算法為1.0)。進一步來說,T細胞淋巴瘤是少見的疾病,其中又有兩類難以分別,一是單形性上皮腸T細胞淋巴瘤,另一是腸道T細胞淋巴瘤,非常仰賴經驗豐富的病理科醫師,根據細胞核大小變異度、形態分布和免疫表現型來判斷。
為解決問題,奇美醫院醫學中心病理部部長兼解剖病理科主任莊世松聯手雲象,用數千顆細胞核的標註資料來訓練模型,來偵測淋巴瘤細胞核、描繪輪廓,並進一步計算每個細胞核的面積、長短軸比例,再根據這些資訊來判斷是哪一種淋巴瘤,預測水準可高達AUC 0.966。這項研究成果,最近也刊於國際知名醫療期刊《Cancers》。(詳全文)
Google 碳排放 4Ms
碳排量最多減少1000倍!Google新ML碳排量預測法能找出更省碳的運算配置
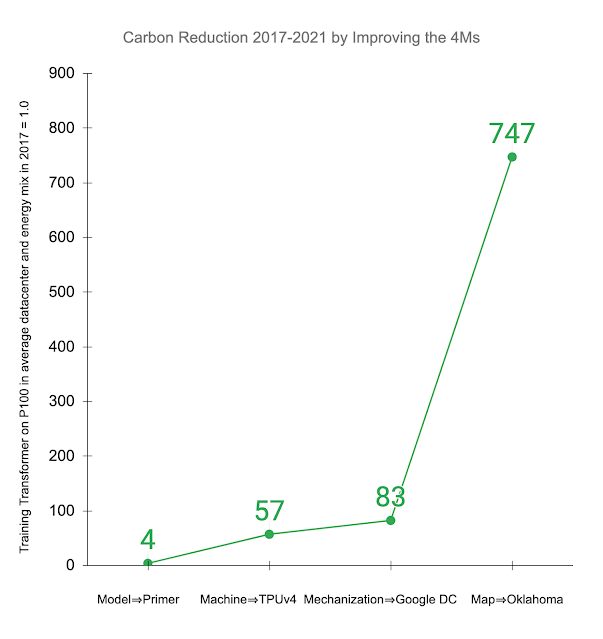
機器學習已成為企業標配,但它產生的碳排量,也開始成為焦點。Google在IEEE Computer發表一篇機器學習碳足跡論文,可透過準確的資料來評估機器學習實際碳排量,並提出4Ms原則,最多能降低使用能源的100倍,減少碳排放量1,000倍。Google也用這些方法,將機器學習所占的總能源使用量壓低在15%以下。
4Ms原則分別指模型(Model)、機器(Machine)、機械化(Mechanization)和地圖最佳化(Map Optimization)。Google指出,用高效機器學習模型架構,如稀疏模型,不僅能提高機器學習品質,還能夠降低3倍到10倍運算量。而機器是指,採用機器學習專用處理器與系統,能將效能提高至2倍到5倍。
機械化的配置,讓資料中心效率比企業本地端配置要高上許多,使用雲端運算可減少能源使用,碳排放量減少1.4倍到2倍。地圖最佳化則是雲端可讓用戶選擇使用能源最乾淨的位置,進而將總碳足跡減少5倍到10倍。Google自己也落實4Ms原則,在4年內總共減少747倍碳足跡。(詳全文)
圖片來源/GitHub、屏東縣政府、Meta、DeepMind、Google
AI近期新聞
1. 美著作權局判定AI不具有繪圖著作權
2. 新竹縣7處將啟用影像辨識科技執法
3. Google Docs內建AI自動產生文件摘要
資料來源:iThome整理,2022年3月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02