微軟發布了高效能MoE(Mixture of Experts)函式庫Tutel,可用來促進大規模深度神經網路(DNN)模型的開發,Tutel藉由支援多樣化靈活的MoE演算法,使得跨人工智慧領域的開發人員,可以更高效地執行MoE。
MoE是一種深度學習模型架構,可以讓不同專家網路,來處理相同領域的異質問題,以電腦視覺來說,就可以結合偵測人類的神經網路,以及姿勢評估的其他神經網路。微軟提到,要將深度模型擴展至數兆參數,MoE是目前唯一一種方法,能夠讓模型學習更多的資訊,使電腦視覺、語音辨識、自然語言處理和機器翻譯系統等模型更加強大。
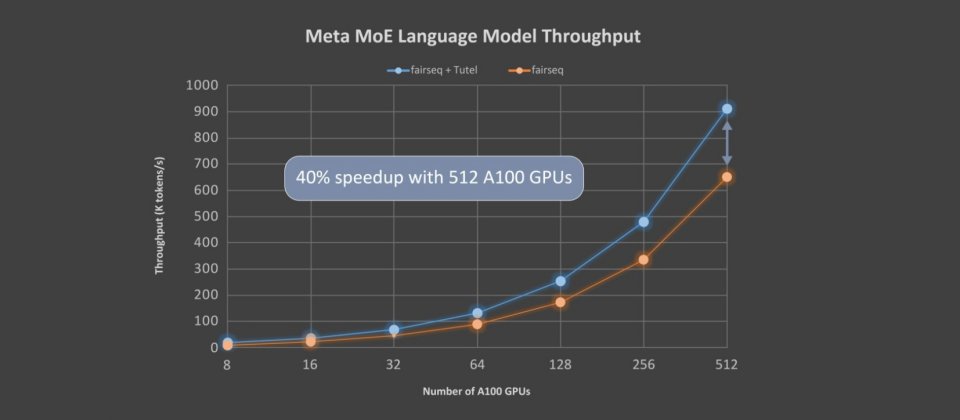
Tutel針對微軟新發布的Azure NDm A100 v4系列執行個體進行最佳化,透過與Meta最先進的MoE實作fairseq相比,Tutel加速可達到2.75倍。以端到端的效能來說,Tutel獲益於全體對全體(All-to-All)通訊最佳化功能,比起Meta擁有1.1兆參數的MoE語言模型,在同樣使用64個NDm A100 v4節點上,可以實現40%以上的加速。
臉書解釋,Tutel作為fairseq、FastMoE和其他進階MoE解決方案的補充,Tutel的重點擺在MoE特有運算和全體對全體通訊的最佳化,並且支援各種靈活的演算法。Tutel具有簡潔的介面,可以簡單地整合到其他MoE解決方案中,又或是開發人員可以使用Tutel,從頭開始將獨立的MoE層,合併到自己的DNN模型中,並直接獲得高度最佳化的MoE功能。
由於目前缺乏基於MoE的DNN實現,通常都必須仰賴PyTorch和TensorFlow深度學習框架的多個現成DNN運算器,經過組合來執行MoE運算,官方提到,由於冗餘計算的緣故,這樣的做法會明顯提高效能開銷,而Tutel特別實作了多個經最佳化的GPU核心,提供MoE專用的運算子。
另外,Tutel還實作了快速cumsum-minus-1運算子,與fairseq中的實作相比,達到了24倍加速,Tutel也利用CUDA C++ Runtime編譯函式庫來以JIT最佳化自定義的MoE核心。
針對Azure NDm A100 v4叢集上的大規模MoE訓練,Tutel最佳化了其全體對全體通訊,其使用CPU-GPU綁定技術和自適應路由調校,同樣在512 A100 GPU上運算,Tutel比起fairseq加速可達2.56倍到5.93倍。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02