")
Line自行建置一套MLOps監測工具Lupus,包括Lupus函式庫、主機和網頁版App,可收集所有ML模型相關指標並偵測異常,將資訊視覺化呈現在網頁App上。(圖片來源/Line)
「我們有100多個機器學習產品,橫跨20多個部門中運作!」Line機器學習開發部工程師石河純輝說。當AI深化到企業內部各流程,就得有套機制來監控模型,以便在模型偏移時即時調整。這種機制就是MLOps。
高度仰賴AI的Line深知MLOps重要性,但仍面臨不少挑戰,像是收集模型各類指標、模型異常偵測和監控視覺化等問題。經過一番琢磨,他們找出一套解法,自行開發一套MLOps監控工具Lupus,提供專屬監控主機、專用函式庫和視覺化儀表板的網頁應用,讓開發者、維運者和專案成員更容易掌握ML模型的動態和品質,甚至可用來即時重新訓練模型,修正模型預測的偏差。
為何MLOps不好做?資料漂移、周期性特性比DevOps複雜好幾倍
談起維運,最為人熟知的就是DevOps,諸如資源使用狀況(CPU、記憶體等)、網路流量變化、硬碟讀寫能力等,都能靠一套成熟的監控機制來自動、定時把關,還能用邏輯簡單的警報系統來提醒維運者。
但,MLOps遠比DevOps要複雜。石河純輝指出,MLOps是「ML + Dev + Ops」這三種工作流程(也是團隊)的整合,工作流程涵蓋了ML階段的模型設計、分析、評估,再加上Dev階段的資料收集、工作流程建立,還有與Ops階段重疊的模型派送工作等。甚至,Ops階段還需要進行模型維運和監控。
要發展一套MLOps流程,得涉及資料和模型兩大層面。就資料來說,維運者得注意輸入資料的變化,也就是資料是否發生漂移,另也需注意輸入值的目標模式變化,即是否發生概念漂移。在模型部分,則要注意模型準確度、推薦值的多樣性,以及模型公平性。
而且,石河純輝指出,MLOps監控頻率會因模型而異,無法像傳統DevOps作法,只是簡單地設置閾值警示通知即可。有些模型數小時就得檢測一次,有些是數天才需要,得依不同ML應用的生命周期來設定。
Line跨部門上線100多個ML產品,自建管理工具仍不足
對Line來說,負責管理ML模型應用的就是機器學習開發部門。他們專門設計ML產品,來給不同單位使用。石河純輝透露,他們至今已上線100多個ML產品,遍布內部20多個部門。為管理這些模型,Line機器學習部門也設置一系列MLOps工作流程和工具。
他們以K8s和自建的Hadoop叢集資料統一平臺「IU」為主要運算環境,並自建Jupyter主機Jutopia來提供模型開發環境,讓開發者用來分析資料、進行實驗。同時,Line採用3套工作流程引擎如Airflow、Argo Workflows和Azkaban來處理批次工作,並以CI/CD工具ArgoCD、Drone CI進行模型部署派送工作。
除了使用開源工具,Line機器學習部門也自建了專屬工具來管理AI模型,像是共用特徵向量管理器,用來收集使用者行為日誌和產品後設資料(Metadata),讓不同ML專案也能使用這些共通性的資料。此外,還有一套內部函式庫,來進行模型收集、分散式訓練和推論、管理輸入和輸出,以及推薦自動化等工作,在測試工具上,也自建一套外部實驗管理軟體,來管理AB測試、生成推薦的展示等。
「這些工具解決了ML + Dev + Ops的大部分工作,」但石河純輝話鋒一轉,唯獨Ops中的模型表現監控尚未做到。
Line MLOps三大挑戰:資料遺失、模型更新、手動監控
也因此,他坦言,隨著自家上線的ML產品越多,監控成本越來越大,再加上Line當時的監控和通報機制是每個專案各自建置一套系統,在這種做法下,監控系統的效果不強,只能根據最少量的變動指標來通報。也因為沒有一套好的監控系統,團隊無法察覺資料缺失、模型輸出值的變化等狀況,甚至曾造成已上線ML模型停擺。
石河純輝進一步分析,Line MLOps有三大痛點要克服。首先是資料缺失,當模型訓練的資料發生遺漏或延遲發送,就會造成模型預測不佳,甚至產出無效預測值。舉例來說,Line有套Email預測系統,每天根據外部單位傳送的表格資料,來進行行為預測,再將預測結果回傳給外部單位。若表格上的資料有缺漏,就會影響模型表現,沒有好的監控系統,工程師也不會察覺異常,「這發生過幾次了,」他說。
第二個痛點是模型更新。他回憶,團隊曾經在模型架構更新時,忽略了新舊模型的預測值分布狀況,即便新模型的預測值更準確,只要預測值分布明顯改變,就會大幅影響個別使用者屬性,給出截然不同的內容,降低使用者體驗。「這種現象,當時要2個禮拜後才發現、改善,」石河純輝強調。
第三個痛點則是手動監控問題。因為Line針對各專案,在Jupyter Notebook中建置了專屬監控系統,來追蹤模型指標、視覺化呈現結果。這個做法雖然方便,但手動收集的指標,只在當下有用,很難重複利用。而且,觸發警報的條件只能套用簡單規則,更是常常無法審查整體監控程式碼的品質。
瞄準指標收集、異常偵測和視覺化,自建監控機制Lupus
為克服這些痛點,Line機器學習開發部門決定打造一款MLOps監控工具,要具備三要素,要能輕鬆收集指標、快速偵測異常,還要有友善的視覺化介面,讓專案成員隨時掌握模型動態。
這款工具就是Lupus,由三大部分組成,首先是建置Lupus主機,用來管理變動指標、提供異常偵測API,再來是一套Lupus函式庫,可提供各種指標聚合工具和API客戶端。最後是Lupus SPA應用程式,這是一款網頁App,可視覺化圖表來呈現指標狀況和異常偵測結果,也內建驗證功能和後設資料管理。
在這套ML模型監控系統中,指標收集任務啟動後,Lupus函式庫會隨之啟動,Lupus SPA也會同步顯示指標狀態。再來,Lupus主機作為入口點,所有請求都由這臺主機處理,也負責授權驗證工作。啟動後,Lupus主機還會發送請求給不同Worker,平行執行指標收集工作和異常偵測工作。這些工作會使用前述的Airflow等工具來排程執行,而Lupus也有一套Worker機制來管理工作流程,以及記錄後設資料。
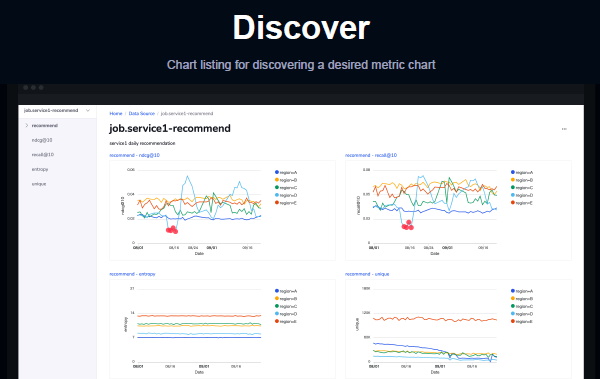
Line自行打造的MLOps監測工具中,包含一套網頁App:Lupus SPA,可讓專案成員查看模型指標變化圖表,讓模型變動資訊更容易分享、討論。圖片來源_Line
至於收集到的指標和異常偵測資料,則長期儲存於開源的資料倉儲Hive,並利用開源搜尋引擎ElasticSearch來提供資訊搜尋和視覺化呈現。
指標收集運作上,Lupus函式庫可用來整合不同指標,將指標所需的資料推送到Lupus主機,主機再上傳指標至S3相容的儲存庫,並提交收集工作至佇列。最後,工作流程工具會將資料儲存於ElasticSearch和Hive中。石河純輝指出,指標收集可用來衡量資料漂移、概念漂移,也能決定模型是否要替換。
而在異常偵測機制上,可以利用Lupus函式庫的API來發送偵測請求,進而促發工作流程工具來讀取儲存於Hive的指標,開始進行偵測,並將異常資訊儲存於ElasticSearch和Hive。這些都內建在Lupus函式庫中,方便ML開發者容易整合到ML專案中。
最後,ML專案所有成員都可以利用Lupus SPA,在App上查看各指標的趨勢圖表和異常偵測結果,也能直接展開細節說明。石河純輝總結,這套MLOps監控工具,讓每日的指標收集工作更容易進行,也能偵測到之前未注意的異常,更能發現新洞察,像是模型準確度的變化,進而激發成員改善ML產品。此外,這個方法也讓Line團隊的監控程式碼經層層審查,比過去的自製方式更可靠。而視覺化的網頁App,則讓團隊更容易分享模型資訊,提高溝通效率。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02