
國泰金控資料科學團隊說明未來AI資料分析自動化藍圖,目前已有專屬AutoML工具自動執行特徵功能、模型選擇和訓練,也有一套特徵搜尋工具Tumblebug能自動找出關鍵資料,未來還要加上圖學資料庫和AutoGraph工具,更要導入因果推論框架。
國泰金控
國泰金控日前在自家技術年會上揭露一款AI資料分析專用工具Tumblebug,能根據使用者需求,自動從資料庫海中撈出所需資料,補足AutoML最後一哩路。不只如此,他們還正打造圖學資料庫,要來解決更複雜的金融問題,未來還要導入因果推論機制,讓AI更聰明判斷資料因果特徵。
資料分析四步驟耗時耗力,自建AutoML工具來分擔
國泰金控的AI資料分析流程可分為四大步驟,首先是問題定義,由資料科學團隊一來一往與業務單位溝通,將業務問題收斂為分析問題。接著,資料科學團隊會從龐大資料庫中,找出相關資料,比如透過目標標籤(Target label),從金控內數個資料庫、數千張資料表、數十萬個欄位中,鎖定出關鍵資訊,特別耗費人力與時間。
下一個步驟則是特徵工程,針對第二步找到的特徵和資料,來清洗數據,如資料填補、轉換、聚合和精煉等。最後一步是模型選擇和訓練,通常,這個步驟需要資料科學家調超參數、選模型,也需投入不少時間和人力。
國泰金控資料科學團隊手上會有多個專案要同時執行,每一個專案都得執行這四步驟,這也導致,每位分析師、資料科學家很難有充沛時間來尋找更好的模型。
近年也出現不少AutoML工具來解決問題,尤其能自動化執行特徵工程和模型選擇與訓練作業,比如資料清洗和超參數調整,可以節省資料科學團隊許多時間。
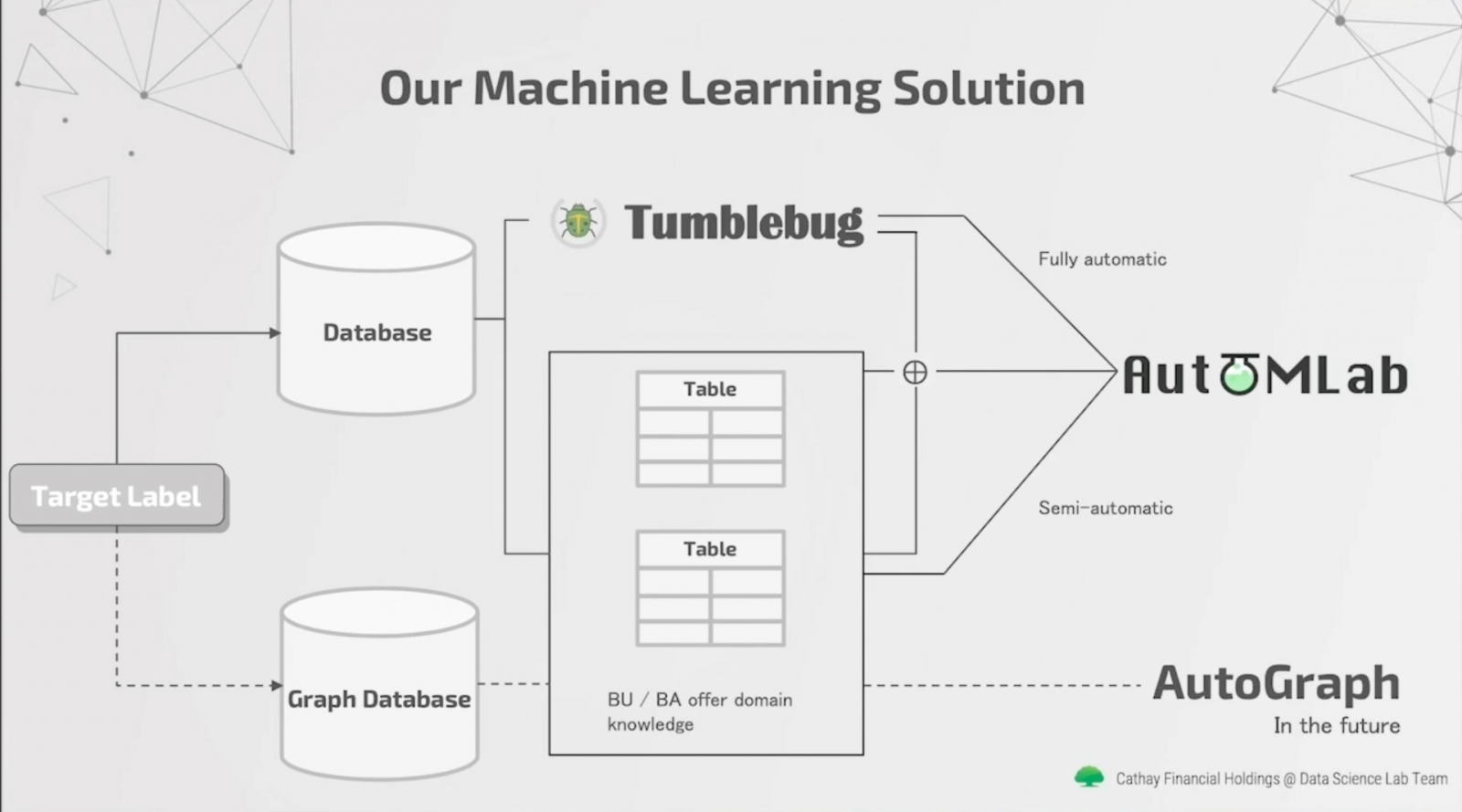
國泰金控也自行開發一套AutoML工具,也就是AutoMLab,來自動化這些流程。它是一套基於大數據分析平臺Spark分散式運算的AutoML套件,能快速協助使用者,利用特徵資料表來建立機器學習處理流程。國泰金控指出,AutoMLab的最大特點是,能根據內部使用者反應,來快速迭代、調整產品,還能根據使用者需求開發相應功能。
至此,國泰金控已將資料分析四大步驟的後兩步自動化了,接下來,他們瞄準第二步驟:取得相關資料也要更自動化。
打造Tumblebug從資料庫海撈出關鍵資訊
國泰金控表示,以往資料科學團隊在取得資料時,會面臨不少問題,比如只能搜尋特定資料,只根據特定領域知識鎖定少數資料表,來搜尋特徵,無法有效利用歷年累積的海量資料;這種工作非常耗費人力,而且,一旦遇上過去沒處理過的專案題目,若分析人員沒有足夠的專案知識,就難以從資料庫中找出所需特徵。
因此,國泰金控資料科學團隊開發一套工具Tumblebug,是基於Spark的特徵搜尋套件,能根據預測目標,來從海量資料表中找出符合的特徵,整理成一張資料表,供使用者後續建模分析。
Tumblebug如何派上用場呢?
首先是處理新興領域問題。比如,團隊有明確的預測問題,但不知道要找哪些特徵,就可使用Tumblebug來搜尋特徵。或是,分析師要加入更多特徵時,也能用Tumblebug從全行資料庫搜尋特徵,不再局限於少量資料表。又或是,當分析師想快速了解、驗證分析問題時,也能用Tumblebug快速找出特徵、評估專案可行性。
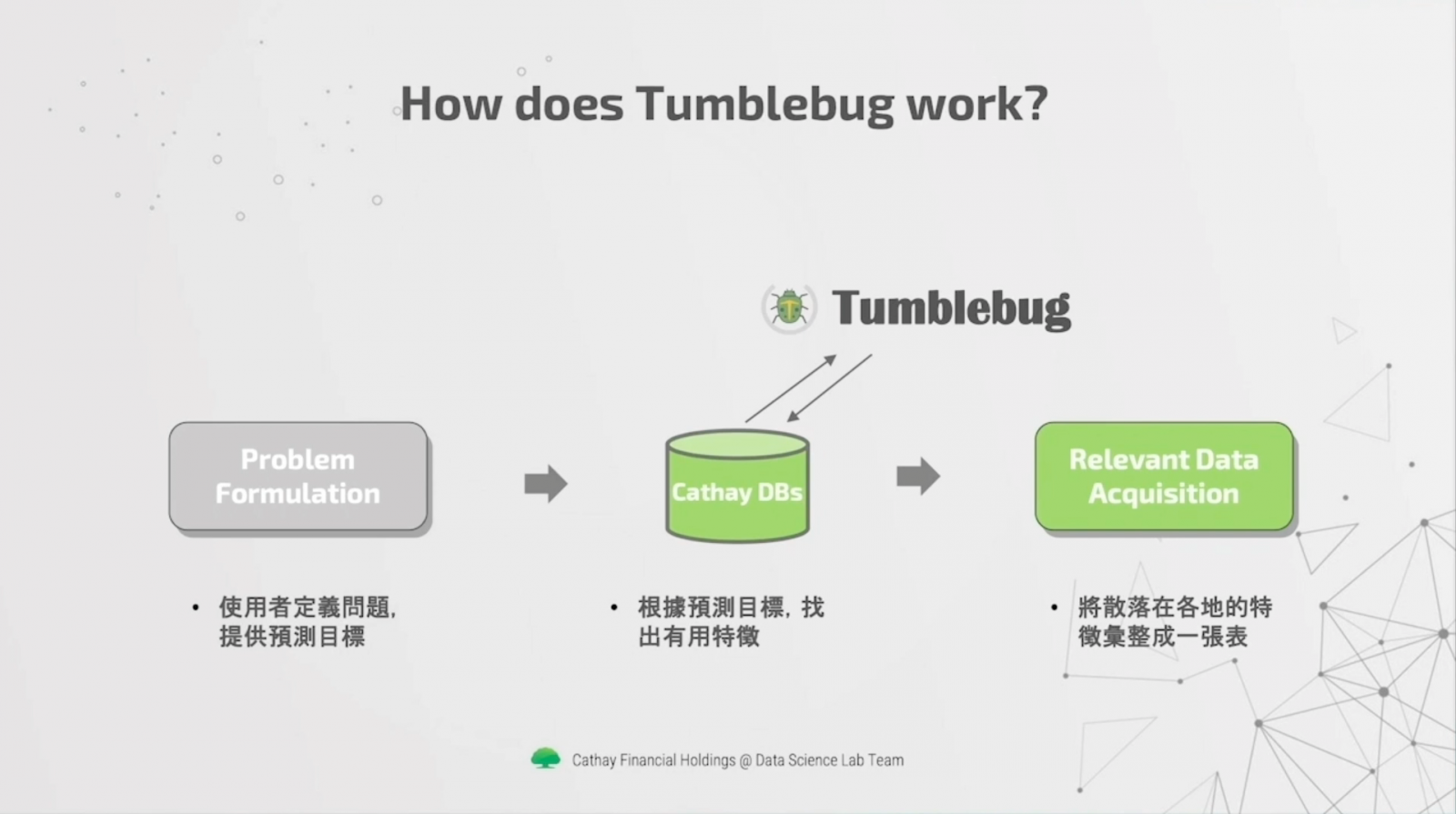
國泰金控指出,Tumblebug不只能發掘未知邏輯、重要變數,提高資料表使用率外,還能縮短搜尋時間。比如,只要給定預測目標,Tumblebug就能在數小時內,從資料庫海找出重要特徵。而且,Tumblebug已經經過國泰20多個預測專案實務驗證。
正打造圖學資料庫,還要建置因果推論讓AI更聰明
至此,國泰金控AI資料分析流程中,除了第一步的需求訪談外,其餘取得相關資料、特徵工程、模型選擇與訓練等步驟都已能自動化執行,使用者也能根據自身需求,來選擇人工介入程度。
比如可採用全自動方式,先透過Tumblebug搜尋特徵,再利用AutoMLab自動建模;又或是利用自身領域知識,從資料庫中尋找特徵,再結合Tumblebug找出的特徵,傳送至AutoMLab來建模。
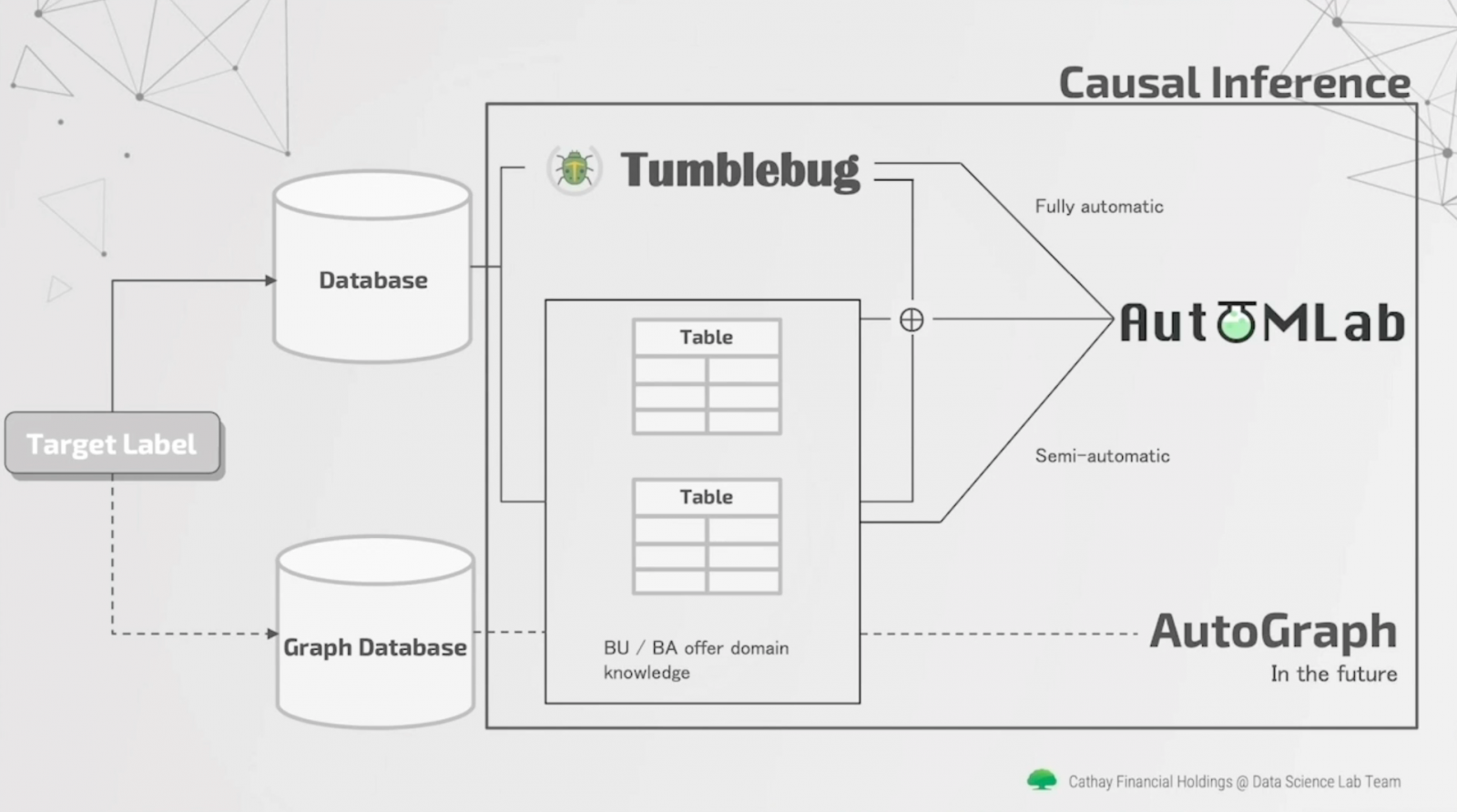
不只如此,國泰金控也正打造一套圖學(Graph)資料庫,要將客戶金流網絡、關係網絡轉換為圖學資料,儲存至圖學資料庫中,有別於以往只儲存結構化資料的資料庫。未來,國泰金控還要打造AutoGraph工具,來自動化執行圖學模型的建置與訓練,分析師就能用圖學技術解決更複雜的金融問題。
這樣還不夠。
國泰金控認為,目前的AI雖能準確辨識某些模式,但對顯而易見的因果關係,卻無法正確推論。因此,他們鎖定因果推論(Casual Inference),未來要在尋找資料、模型訓練流程中,加入因果推論方法,找出資料間的因果特徵,讓訓練出來的AI能像人類一樣推斷。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02