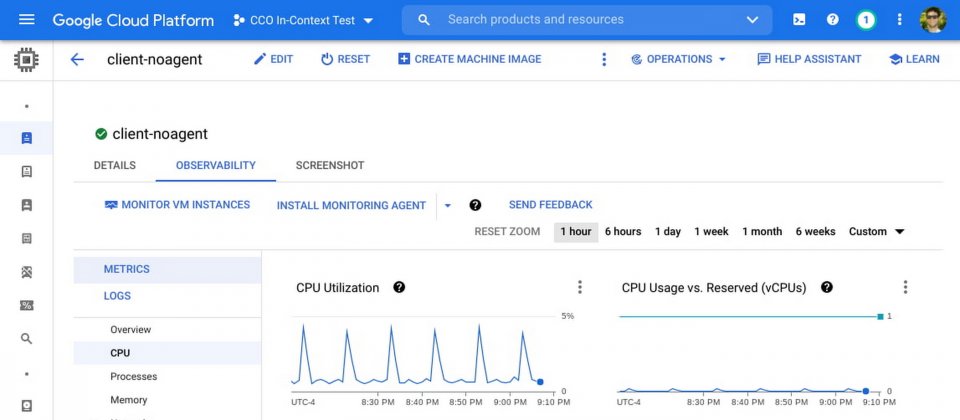
Google推出強化上下文(In-Context)的UI工具集,供用戶更快速地對Compute Engine進行除錯,藉由各種指標、圖表和視覺化功能,能夠助用戶分析指標和網路變化,並且找出適合的磁碟大小,甚至是調整和測量記憶體效能等。
Google提到,要對虛擬機器在生產環境進行除錯,過程可能很複雜,因為不只需要多個基礎設施的資料點和訊號,還需要來自應用程式的指標。所以當用戶遭遇延遲、停機和錯誤等情況時,便需要在不同的工具和UI間切換,來探索造成問題的根本原因,但這個過程可能拖慢除錯速度。
過去Google在Compute Engine控制臺提供一組進階指標,來簡化虛擬機器除錯,雖然如此,用戶仍需要在不同工具之間切換查看,才能對問題進行根本原因分析,官方舉例,當CPU使用率在特定時間到達峰值,這可能是一個有用的分析起點,但是要解決問題,就必須要深入了解造成該問題的原因,而這會需要與程序相關的許多資料和訊號。
為了解決這個問題,Google在Compute Engine頁面添加了指標、圖表和各種新的視覺化功能,其中部分新增的功能,則是來自Google雲端Ops代理所產生的深度指標,而Ops代理能夠透過Terraform、Puppet、Ansible和安裝腳本簡單地安裝。由Ops代理所提供的新圖表,包括來自作業系統報告的CPU使用率、記憶體使用率,和由用戶造成的記憶體故障,還能顯示像是核心、磁碟快取、I/O延遲和程序指標等資訊。
雖然難以提供單一故障排除流程,一次滿足所有場景需求,但Google表示,這套經強化的可觀察性工具,能夠讓用戶更直覺迅速地處理多種場景。像是當用戶從指標和日誌辨識出網路變化,無論是意外的網路流量增加、網路資料封包大小或是網路連接的峰值,用戶可以藉由日誌工具,來快速過濾並找到關鍵的日誌紀錄,並且利用日誌資源管理器中的深度連結,在Compute Engine和Cloud Logging服務之間快速無縫切換瀏覽。
另外,用戶也能夠從磁碟監控工具中,發現在高負載的情況下,例如當每秒IOPS峰值(Peak 1-second IOPS)圖表上的數值線段呈現水平,則可能代表磁碟效能受限制,如果此時I/O延遲平均也相對應的增加,就能夠確定I/O遭到限制,根據這些資訊,用戶可找出負責大部分IOPS的磁碟類型,並且增加磁碟容量,來提高儲存效能限制。
新的UI工具集也能用來測量和調整記憶體效能,Google提到,大多數虛擬機器系列都需要Ops代理來收集記憶體使用率,透過檢查Top程序的記憶體使用,開發人員就能偵測記憶體洩漏,進行重新分配或是終止違規程序。營運人員也能夠藉由按分類檢視記憶體細節,來發現應用程式使用記憶體的狀況,選擇更適合的虛擬機器類型。
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-02

2026-03-06