
Google與DeepMind合作,在XNNPACK加速函式庫和TensorFlow Lite中,加入了稀疏神經網路相關支援以及指南,讓開發者可以在裝置上實作稀疏網路,並使用稀疏網路進行有效率的推理(Inference)。這些工具可以提高模型推理速度1.2到2.4倍速,模型大小也減少一半,Google使用該技術改進跨平臺人工智慧工作管線框架MediaPipe中的手部追蹤,以及視訊會議服務Google Meet裡的背景模糊功能。
裝置上神經網路可以用來開發低延遲和高隱私性即時應用程式,提供像是姿勢評估和背景模糊等功能,透過使用TensorFlow Lite等機器學習推理框架和XNNPACK機器學習加速函式庫,開發者可以在模型大小、推理速度和預測品質中取得平衡,使得模型可以在各種裝置上執行。而最佳化模型的其中一種方法,便是使用稀疏神經網路,透過將網路中部分權重設置為0,不只能夠壓縮模型大小,還可以跳過許多乘法和加法運算,加快推理速度。
但是因為過去缺少稀疏卷積基礎架構的工具,而且在裝置上執行這些操作的支援度仍不足,導致要在生產環境使用該技術受到限制,因此Google與DeepMind在XNNPACK加速函式庫和TensorFlow Lite中,擴展對稀疏神經網路的支援,使得開發人員可以更容易使用該技術。
新版的XNNPACK函式庫能夠偵測稀疏模型,當模型為稀疏神經網路,則會將標準密集推理模式切換成稀疏推理,並且加速1x1卷積運算子,在模型有80%權重為0的時候,執行速度將提高到原本的1.8到2.3倍。
該版本提供了稀疏網路創建指南,引導開發者從一個密集版本的模型開始,在訓練期間逐漸將部分權重設置為0,這個過程稱為修剪,開發者可以使用各種修剪技術,也可以使用Google在TF模型最佳化工具包中提供的方法,使深度學習模型變得稀疏,但同時又不降低其品質。生成的稀疏模型,可以使用壓縮格式儲存,與等效的密集模型相比,壓縮後模型尺寸可極大幅度縮小。
研究人員提到,用戶可以對分類、切割和回歸等問題進行稀疏化,而這能帶來顯著的好處,像是應用在Google Meet,稀疏模型的推理時間縮短了30%。
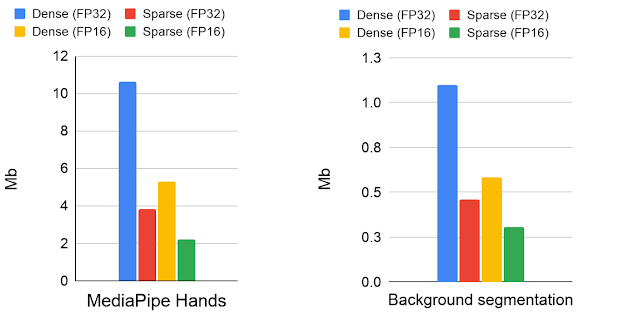
該方法適用於MobileNetV2、MobileNetV3和EfficientNetLite等模型,神經網路的稀疏程度,會直接影響推理速度和品質,即便保守地使用稀疏度30%的模型,也能獲得良好地效能加速,而在稀疏度70%以上時,準確度會明顯下降,但是只要將原始基礎網路的大小擴增20%,就能補償稀疏度70%精確度下降的問題,在加速推理速度的同時,又不降低模型品質。
Google Meet背景模糊功能實際使用稀疏模型,其應用70%的稀疏度,帶來30%的模型加速,同時保有前景遮罩品質。而MediaPipe則使用EfficientNetLite模型,在行動裝置和網頁上提供手部姿勢辨識功能,與密集模型相比,稀疏模型提高了2倍的推理能力。

Google提到,稀疏化技術,是一個可以簡單改善神經網路在CPU上推理的技術,使得較大型的模型不會產生明顯的效能和尺寸負擔,Google將繼續擴展XNNPACK,並且結合更多最佳化技術。
熱門新聞

2026-03-02

2026-03-02


2026-02-26

2026-03-02

%3A \">圖片來源/Novee</a>")
2026-03-02

2026-03-02