,整合了多項ML開發工具,來加快協作開發流程。")
為了讓多元、複雜的角色能共同協作來開發ML,Line臺灣以MLOps的概念,打造了一個機器學習平臺MLU(ML Universe),整合了多項ML開發工具,來加快協作開發流程。
圖/Line臺灣提供
從AI模型訓練到部署上線,一個完整的ML工作流(ML Pipeline),需要資料端與工程端的人員共同協作來打造,這個結合了ML與DevOps的協作概念,被稱為MLOps,開始受到越來越多企業重視,比如Line臺灣就在12月18日的開發者大會中,揭露自家的資料工程研發團隊,如何運用MLOps的觀念打造MLU機器學習平臺,來優化ML專案的開發管理流程。
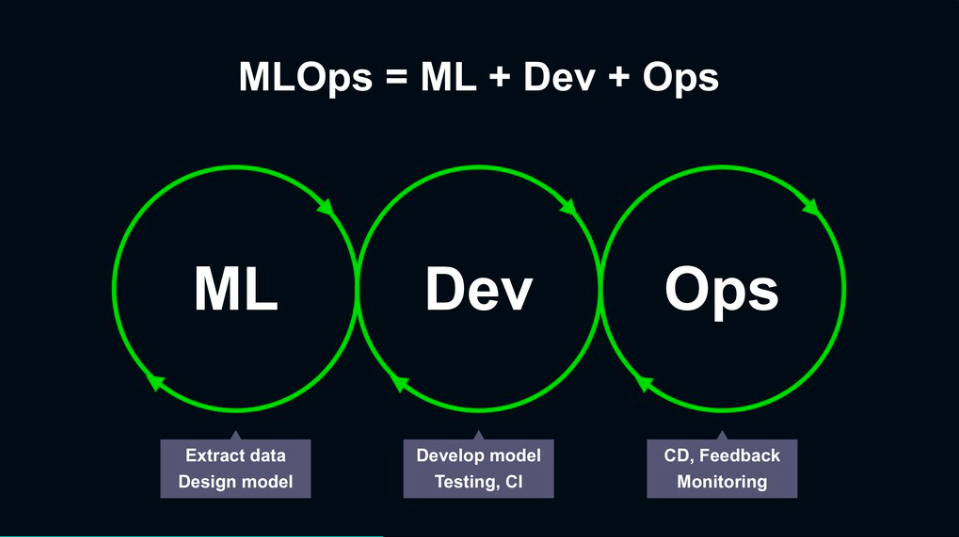
MLOps也就是ML+Dev+Ops的概念,在ML階段,需要運用不同資料設計初始模型;在開發(Dev)階段,需要進行模型開發與測試,並持續整合、部署上線;在維運階段(Ops),則需要持續交付,並透過監控系統來獲得品質回饋。
要了解MLOps的重要性,就得先了解一般ML團隊的組成,以及在ML開發各階段可能面臨的挑戰。
Line臺灣資料工程部資深經理蔡景祥指出,Line臺灣的資料工程團隊,分為資料工程師、ML工程師、ML服務工程師、資料分析師四大角色。蔡景祥解釋,若以打造遊樂園來比喻,資料工程師的任務,就是打造遊樂園的基礎建設,透過建立起一個穩固的資料收集設施,來根據需求蒐集資料,需擅長如大數據架構、SQL、ETL、訊息佇列(Message queuing)等技術;而ML工程師,則像是遊樂園的設計師,負責選出適當的資料集與演算法,來建立起合適的ML模型,需具備的技能包括機器學習、深度學習、電腦視覺、NLP等。
ML服務工程師,則像是遊樂園基礎建設的實際施工與維護者,主要負責建立並維運一個ML平臺,需熟悉的技術包括系統基礎建設設計、DevOps;最後的資料分析師,則需比工程師具備更多的商業思維,要能夠利用統計的方法,來分析模型上線後的實際成效,類似於在遊樂園中觀察哪些設施需要改善的角色,因此需具備商業知識、熟悉統計及資料視覺化等技能。
蔡景祥也將ML Pipeline分為6大環節,分別是準備資料、探索資料、開發模型、訓練模型、測試模型與部署上線,來說明不同角色如何在ML Pipeline的各個環節中協作。
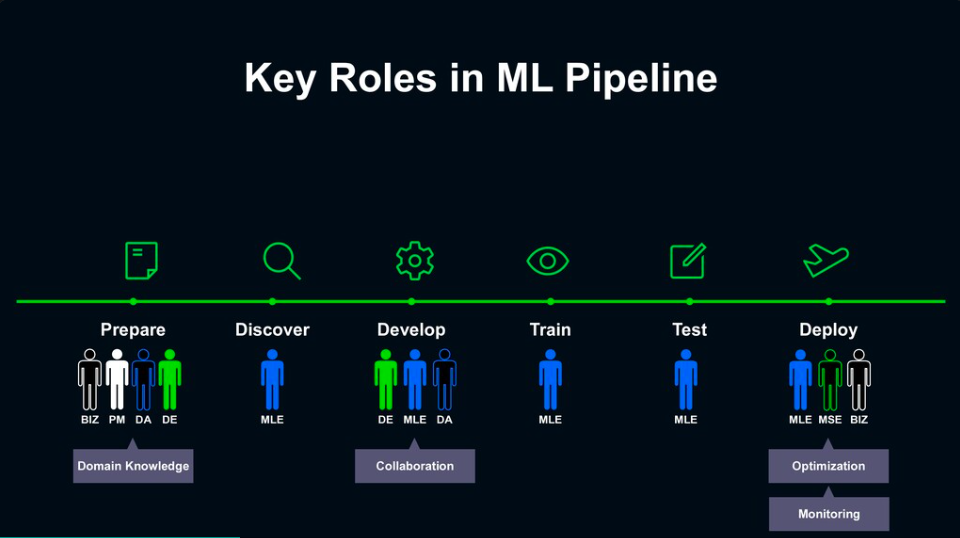
在ML開發的不同階段,需要不同角色協作來完成任務。
在準備資料的階段,由於領域知識扮演了重要角色,過程中需要產品端、資料分析與資料工程專家相互協作,透過資料標註來取得有效的資料;接著,進入探索資料階段,則會交由ML工程師,根據資料特性來發掘資料潛在的價值,運用特徵工程來建立模型。
有了資料,就能進入開發模型的階段,此時需透過ML工程師、資料工程師及資料分析師的協作,選擇適當的演算法來開發模型,在這個階段中,演算法的挑選與模型的版本控制,成為協作過程中的重要的課題;而後進入訓練模型的階段,則會交由ML工程師,負責進行超參數的調整與硬體運算資源的調度。
模型訓練完成後,將進入測試模型的環節,同樣交由ML工程師負責,來驗證模型是否確實有效、是否達到預期的效益;若沒問題,就會進入最後的部署上線階段,需要ML工程師、ML服務工程師共同協作,來確保模型在實驗環境與線上環境中的表現並不會產生太大偏差,也不會隨著時間衰退,實際部署後也要能應付大流量的預測需求,才能有效擴大提供服務。
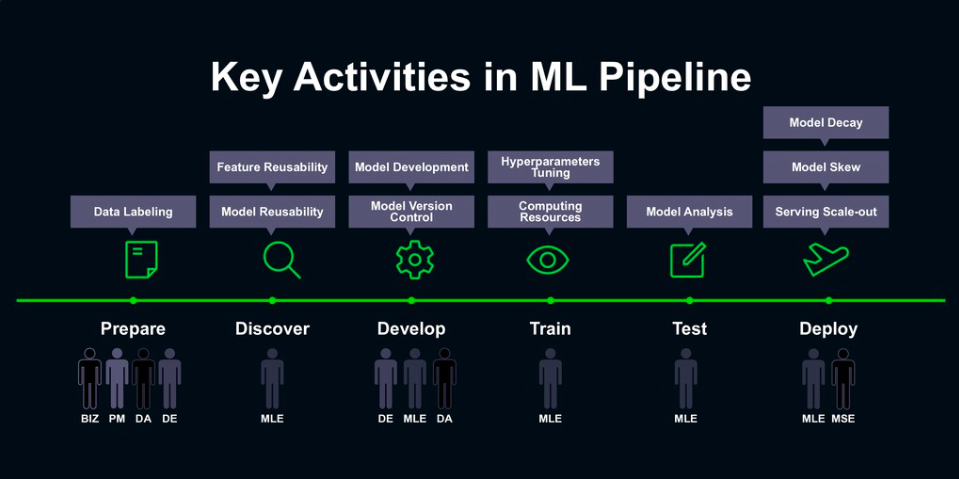
在ML開發的各個階段,也各有關鍵任務需要實現。
整合常用開發工具打造MLU平臺,來加速ML開發協作
為了讓多元、複雜的角色能共同協作來開發ML,Line以MLOps的概念,打造了一個機器學習平臺MLU(ML Universe),目的要以一個完整的ML工作流,來快速開發有效且高品質的ML模型,同時減少過程中協作溝通的成本。
在MLU平臺中,資料工程團隊分別在ML Pipeline的各個階段,整合了常用或自建的開發工具,來加快協作開發流程,包括提供能共同協作開發的Notebook工具、能設定Pipeline自動化的介面,也整合了GPU運算資源與Kubernetes叢集,來提供持續訓練及穩健的運作環境,以及能持續監控模型表現的工具等。

在MLU平臺中,Line臺灣分別在特徵商店、開發協作、Pipeline自動化、模型訓練、部署、監控等環節,都整合了常用或自建的開發工具來加速開發協作。
LINE臺灣工程師Penny Sun也進一步介紹了這些工具在協作上的幫助。首先,在資料準備與探索的階段,會需要資料工程師來繼進行特徵工程,由於這項工作需經過反覆的試驗,團隊建立了一個用來管理特徵資料的特徵商店(Feature Store),讓資料工程師能將整理後的資料,透過一個統一的介面輸入特徵商店,將特徵資料以標準化的方式來儲存,如此一來,ML工程師與資料分析師,就能透過同一個介面來查找所需資料,不用再費時處理資料,藉此達到重複利用特徵資料的目的。
接著,在模型開發的環節,團隊整合了Jupyter Notebook作為協作開發的工具,也整合了開源的Jnotebook Reader,讓開發的Notebook可以輕易在各個團隊間共享,Penny Sun也特別提到,由於Line臺灣開發的每一份程式碼,都需要至少兩個人以上看過,團隊也整合了Jupyter Notebook的協同作業工具ReviewNB,讓檢視程式碼的工作更順暢。
而在模型開發的階段,過去需要工程人員協助建立起開發流程,但現在,團隊自建了一個Pipeline Editor的工具,讓ML開發者能直接透過視覺化拖拉設定的方式,將Pipeline的每個步驟流程串連起來,來降低與工程人員的協作成本;開發者在編輯完Pipeline之後,則會轉換為開源工作流管理平臺Airflow的腳本,來進行後續的部署、CI/CD的工作流程。
在模型訓練的環節,Line臺灣也透過由上百顆GPU支持的NSML平臺來訓練模型,滿足大量的運算需求,並透過視覺化的方式來監控所使用的資源量;不只如此,NSML平臺也提供了AutoML的功能,能節省ML訓練過程中需要反覆調校超參數的時間,針對持續訓練時產生的不同模型版本,團隊也整合了開源ML平臺MLFlow,讓開發者能進行版本控管,還能在後續模型測試的階段,進行簡單的分析驗證。
在模型經過驗證後,團隊也運用開源ML模型部署平臺BentoML,將選定的模型存取下來,將預測的服務打包成Docker Image放到Docker Hub上,再透過自動擴充的模型部署工具KFServing部署到K8s上,根據流量來自動擴充運算資源量。
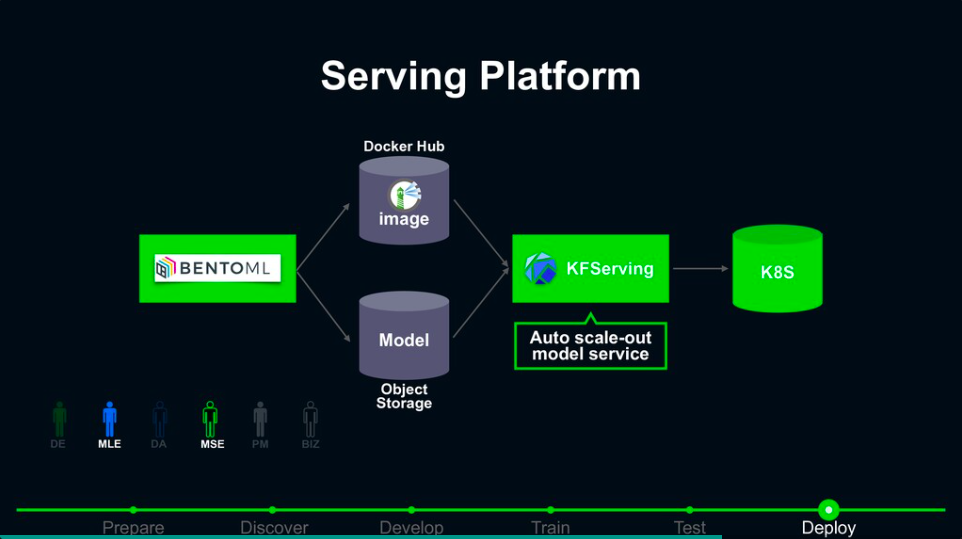
最後,在上線後的模型成效監控環節,需監控的面向包括服務本身的健康程度,以及模型是否因環境的變化而衰退,前者可以透過普羅米修斯(Prometheus)搭配Grafana來監控,後者則需要根據業務邏輯來設定監控指標,透過BI儀表板來監控,根據模型衰退程度來觸發模型重新訓練。
「我們希望透過MLU平臺,讓更多ML開發者可以輕鬆創造出更多有價值的ML應用。」Penny Sun表示,希望藉由MLU平臺,在維持模型開發品質的同時,也消除不同角色之間的知識壁壘。
Line臺灣運用MLU平臺開發的三種ML應用
Penny Sun也實際舉出三個運用MLU平臺,來開發並維運模型的ML應用案例。
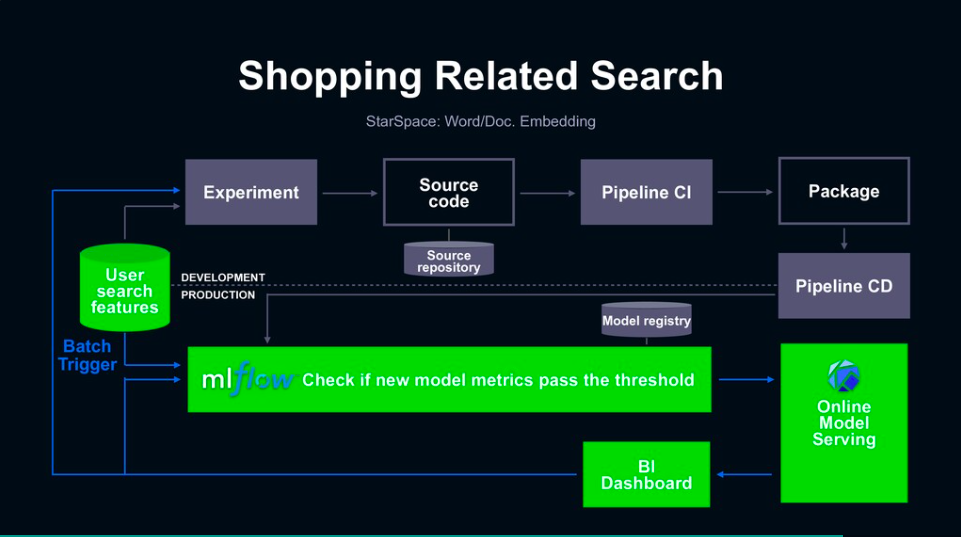
其一,是關鍵字搜尋ML模型,比如在Line購物中的關鍵字搜尋推薦,就是根據使用者查詢的歷史記錄,來建立詞與句子的嵌入模型。不過,由於關鍵字會跟著每天的潮流或趨勢而改變,模型需要頻繁的迭代更新,甚至每天都需要重新訓練,為了加速模型的迭代,團隊運用MLFlow工具來進行版本控管與模型驗證,來確保重新訓練後的模型品質也能維持在一定的水準,同時也建立儀表板來監控模型服務端的健康指標,來隨時觸發模型重新訓練。
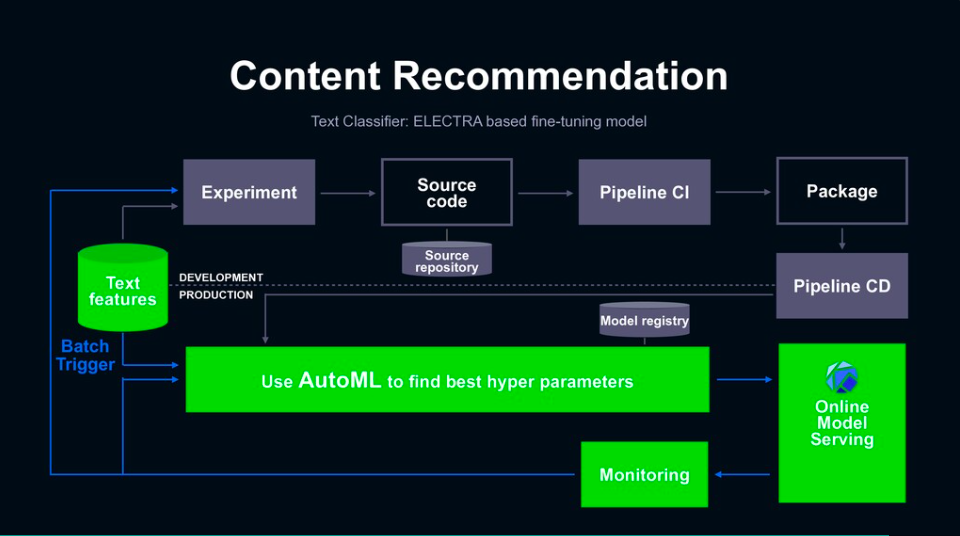
其二,則是文章內容推薦ML,比如Line Today中推薦給用戶相同類型的文章來閱讀。這個ML應用會以NLP模型為基礎,比如BERT或ELECTRA,因此在衰退速度上較慢,需重新訓練模型的頻率也較低,不過,在訓練這類模型時,會需要針對超參數進行反覆的試驗,也就需要運用AutoML自動調整參數的功能,來更有效率的找出表現較佳的模型,並透過KFServing來提供服務端可直接呼叫的API,來節省部署上線的開發時間。
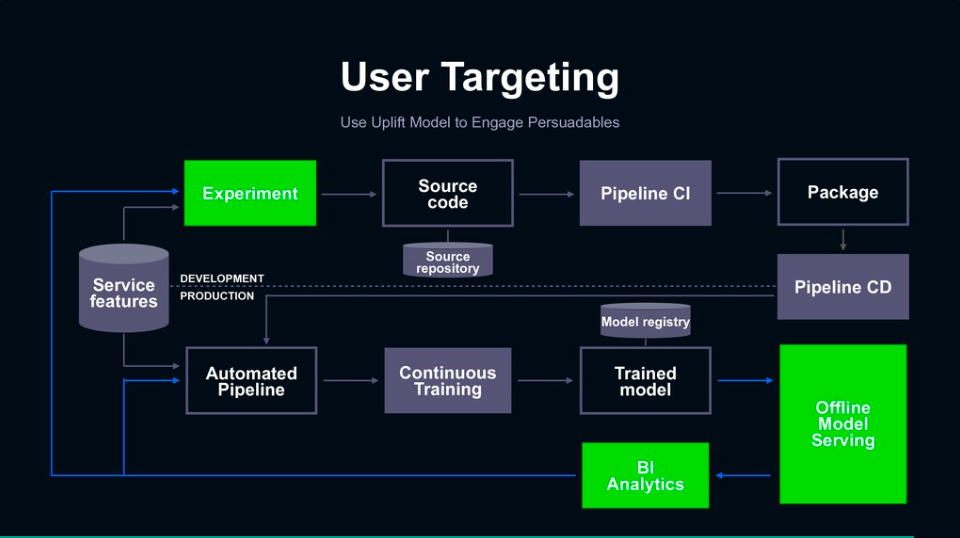
其三,則是目標群眾鎖定(User Targeting)的ML模型,目的要在最小成本下找到最容易被吸引的使用者群,比如Line推播的貼圖活動。這個ML應用與上述兩者的最大不同,是該模型的預測結果是一份目標群眾的名單,因此在模型持續交付的步驟中,實際上是透過線下的模型服務,來產生一份用戶名單,而在模型監控上,則會在使用者行為改變時,重新進行實驗來建立新模型。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09