微軟將自家自然語言生成模型T-NLG用在Bing搜尋引擎中,改進字詞預測,並且利用自然語言表示模型T-ULR,提升多語言智慧問答的品質,還能在摘要中,突出顯示與用戶搜尋相關的資訊。
微軟提到,Bing每日執行用戶數億次的查詢,這些查詢因使用者意圖、語言和地區不同,呈現多元且動態的形式,為了要能夠良好地處理這些查詢,微軟在Bing上大規模的使用AI模型。在過去一年,自然語言處理模型有了很大的進展,無論是微軟自家的T-NLG模型,還是OpenAI的GPT-3模型,其參數規模都大幅成長,微軟也就將這些模型用於Bing中,以提升搜尋體驗與結果的品質。
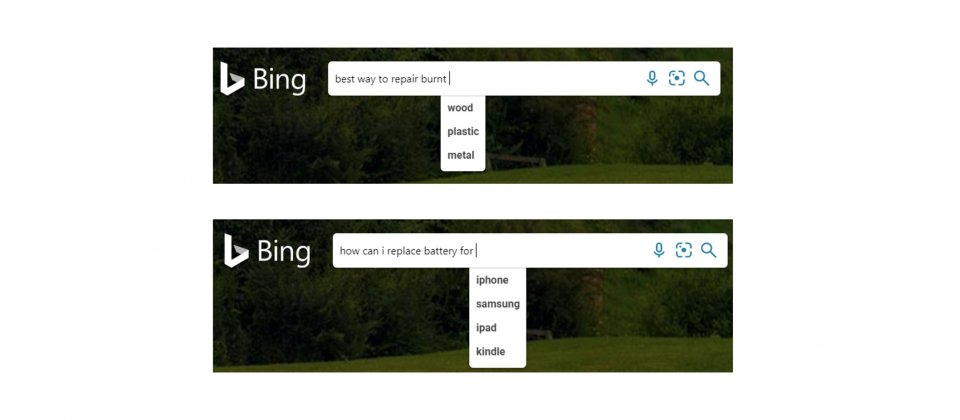
首先,微軟以T-NLG模型改進Bing搜尋欄的自動建議功能,自動建議功能能夠根據用戶輸入的字詞,配對最相關的查詢建議,來改善搜尋體驗,其目的是要讓用戶以更少的時間以及鍵盤輸入次數,獲得更佳的查詢結果。最常用的解決方案,是根據其他使用者的輸入,來提供搜尋前綴,但是隨著用戶輸入更具體的搜尋字詞,該方法也逐漸失效,因此Bing需要能夠即時生成建議,提供用戶準確的搜尋建議。
因此微軟使用T-NLG模型,使Bing具備即時生成建議的能力,不受限於以前使用者輸入的資料,也不侷限於用戶當前輸入的字詞,自動建議覆蓋的範圍大幅增加,也改善了整體用戶體驗。微軟提到,以技術的角度來說,無論是模型的大小還是推論的數量,使用生成模型具有一定的挑戰性,他們應用了壓縮以及快取技術,來解決推論的效率問題。
微軟也改善了Bing的其他人也問了這些問題(People Also Ask,PAA)功能,來覆蓋用戶的搜尋意圖,微軟解釋,PAA讓用戶能夠直接探索與原始搜尋有關的問題,不需要花費時間修正搜尋,就能夠取得想要的解答,與自動建議功能同樣的情況,由於Bing已經回應過許多用戶的搜尋,因此能輕易地提供類似的問題與解答,不過,有時候還是會遇到沒有類似意圖的搜尋,於是Bing就必須要生成有用的問答,來提供PAA內容。
.png)
微軟使用模型對數十億個網頁文件,產生問題與答案配對,因此當有相同的文件出現在搜尋引擎結果頁面上時,微軟除了會在PAA區塊顯示現存類似的問題之外,也會加入預先生成的問題與答案配對,補充PAA區塊內容。
另外,Bing也應用自然語言表示模型T-ULR,提升多語言和多地區的搜尋結果品質,現在Bing的智慧問答功能,已經可以對超過100種語言和200個地區,提供零次問答服務,而且微軟也應用該模型,突出顯示搜尋結果中的摘要重點,讓用戶能夠更快地找到需要的答案。
.png)
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-02

2026-03-02