
OpenAI發表自動定理證明器GPT-f,採Transformer架構,由自動證明器和證明助手組成,能以Metamath形式化語言來證明數學定理。
OpenAI
重點新聞(0904~0910)
OpenAI 自動定理證明 GPT-f
推理能力新突破!OpenAI新作GPT-f能自動證明數學定理
繼釋出具1,750億個參數的超大預訓練自然語言模型GPT-3後,OpenAI組織近日發表另一款基於Transformer架構的模型GPT-f,能以形式化語言Metamath來進行自動定理證明(ATP),成為AI模型在推理領域的另一里程碑。
OpenAI指出,類神經網路在電腦視覺、自然語言處理和機器人技術都有不錯的進展,但在推理能力上,進展較少。為證明類神經網路的推理潛力,團隊以Metamath來訓練Transformer模型。Metamath既是一套用於定理證明的嚴謹形式化語言,也是一套電腦程式,專門用來儲存、驗證和研究數學證明。團隊將Metamath作為GPT-f的正式環境,並採用類似GPT-2和GPT-3、只有解碼器的Transformer架構,來產生帶有不同預訓練資料和大小的模型,其中最大的模型含36層隱藏層、7,740萬個可訓練的參數。
GPT-f由兩部分組成,分別是自動證明器和證明助手。OpenAI利用線上證明助手,來幫助模型產生互動式的證明架構。他們在實驗中發現,GPT-f比現有自動定理證明器還要優秀,可完成測試集中56.22%的證明,而現有的證明器MetaGen-IL只能完成21.16%。此外,GPT-f還發現了新的簡短證明,而這些成果也收錄於Metamath函式庫中。(詳全文)
語音辨識 邊緣裝置 深度類神經網路
邊緣語音辨識新解法,滑鐵盧大學開發輕量模型TinySpeech
雖然AI在自然語言處理已有長足進展,比如以BERT打造的語音辨識模型已達高階表現,但這些模型在邊緣裝置(如手機),卻少有大規模部署、應用。為找出新方法,滑鐵盧大學和加拿大新創DarwinAI共同開發一套注意力集中器,具低耗能、高效率特性,可在裝置端執行語音辨識,他們也展示了由集中器組成的低精確度深度類神經網路TinySpeech,可有限度辨識語音。
DarwinAI指出,團隊研發的注意力集中器以自我注意力機制為主,而且不同於一般仰賴卷積模組的自我注意力機制,是獨立的模組,能讓深度學習模型專注於重要內容。後來,團隊將這些集中器打造為TinySpeech,並以Google資料集來測試,發現比起現有高階模型,其架構和運算複雜度都大幅降低,提高模型效率。(詳全文)
臨床語音辨識 Nvidia Bio-Megatron
Nvidia用BERT打造臨床病患語音辨識模型Bio-Megatron
Nvidia日前在醫療影像機器學習年會中,揭露一套擁有3.45億個參數的醫療語音辨識模型Bio-Megatron,可聽懂病患說出的臨床單字,並對應到標準化的健康資料庫中,能減少醫師在疫情壓力下的工作負擔。
這個模型以BERT為基礎,從美國開放式醫學論文搜尋引擎PubMed中,收集61億個單字作為訓練資料。預訓練後,團隊再以美國國衛院(NIH)建立的臨床自然語言處理資料集,來進行微調,之後再合併到NIH的自動語音辨識模組中。經測試,模型進行1毫秒的分析,精確度可達92.05%。(詳全文)
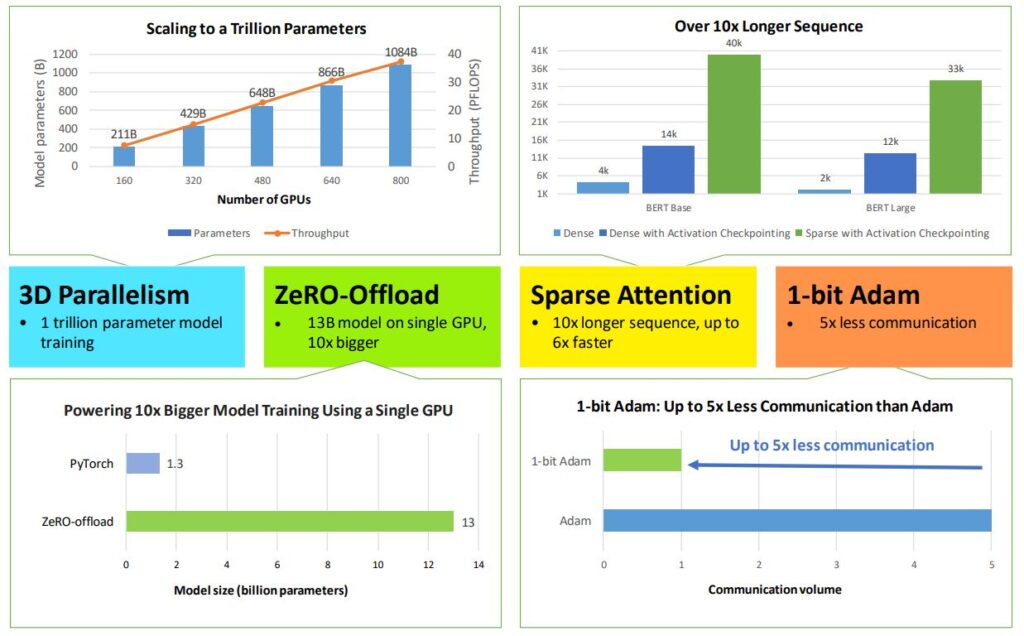
深度學習優化 DeepSpeed 平行化處理
微軟深度學習優化函式庫DeepSpeed再添4項新功能,支援3種平行化處理
微軟近日為深度學習優化函式庫DeepSpeed,加碼釋出4款新功能,包括3D平行化、ZeRo-Offload、稀疏注意力(SA)和1位元Adam優化器,要來縮短深度學習模型訓練時間。DeepSpeed是微軟今年二月開源釋出的深度學習模型訓練優化函式庫,採用自家記憶體優化技術ZeRO,可加速訓練時間;微軟也用它來幫忙訓練具170億個參數的超大自然語言預訓練模型T-NLG。
現在,微軟為這套函式庫新增4功能,其中,3D平行化可細分為三種平行方法:ZeRO資料平行、工作流程平行、張量切割模型平行,可針對不同需求來優化記憶體的調度。另一個功能是ZeRo-Offload,可優化GPU和CPU上的計算資源和記憶體資源,對缺乏GPU資源的開發者有所助益;此外還有新版SA內核技術,可解決開發者訓練注意力型深度學習模型的侷限。最後一個功能1位元Adam優化器,利用預處理來解決誤差補償壓縮技術問題,像是無法用於非線性優化器如Adam的狀況。(詳全文)
洪水預測 機器學習 物理模擬
Google結合物理模擬與機器學習方法,改進洪水預測速度與準確度
Google發表最新洪水預測系統,警示範圍可達250,000平方公里,是過去覆蓋面積的20倍之多,受保護的人口達到2億人。這些功能來自Google新淹沒模型,團隊這次與空中巴士、Maxar等衛星影像供應商合作,取得更精確的高程圖。有別於解決即時模擬水流的複雜運算,團隊選擇修正高程圖型態,以簡單的洪水填充方法,來物理模擬洪水行為。
為此,Google訓練一套純機器學習模型,不使用物理資訊估算河流深度,僅將河流特定點的水位作為輸入,並輸出河流所有位置的水位。後來,團隊以啟發式規則重新合成高程圖,作為利用洪水填充演算法模擬洪水行為的基礎,再結合量測到的水位數值與衛星影像的洪水範圍,來產生淹沒圖。團隊指出,新模型能透過自動學習,修復可能發生的資料錯誤,準確性也提高3%,減少手工建模和校正的需求。(詳全文)

立體視覺 透明物體 量測
Google利用立體視覺快速量測透明物體的3D位置與形狀
Google與史丹佛大學合作,開發出處理透明物體的全新電腦視覺系統KeyPose,可直接預測3D關鍵點來估測透明物體的深度,比過去的方法又快又準。與此同時,Google也釋出了用來訓練KeyPose模型的透明物體資料集,供研究社群使用。
為建立訓練資料集,Google首先建立一個資料收集系統,利用機器手臂及其上的立體相機和Kinect Azure深度相機,來拍攝影片,之後再標記影像的3D關鍵點,並用這些資料來訓練模型。完成後,團隊也進行測試,發現新方法快又準,使用標準GPU計算馬克杯深度時,只需5毫秒,且無論是透明瓶子還是馬克杯,其平均絕對誤差都在10 mm以下,瓶子的平均絕對誤差甚至可達5.8 mm。(詳全文)

Amazon 語音相容 多代理設計
Amazon AI語音相容計畫再添新成員,同時發布多代理設計指南
Amazon去年發起AI語音相容計畫(Voice Interoperability Initiative),當時微軟、Salesforce、百度等多家大廠皆參與,透過規範制定,來讓裝置支援多個語音服務。現在,這項計畫的陣容越來越壯大,臉書、杜比、Garmin和小米等廠商紛紛加入,目前成員數已超過70名。另外,Amazon還收集計畫成員的建議和最佳做法,發布了第1版多代理設計指南(Multi-Agent Design Guide)。
這個多代理設計指南,涵蓋了3大領域,分別是用戶選擇與代理啟用、多代理體驗,還有隱私與安全。該指南建議在裝置上註冊多個代理、接受用戶使用多個喚醒詞;至於多代理體驗,則是說明代理可用來增加用戶參與的基本行為,使用戶能夠找到可用代理,並且順利探索功能。(詳全文)
突發事件 自然語言處理 錯誤訊息
Google搜尋用AI快速偵測突發事件和錯誤訊息
Google日前分享自家24小時監控全世界新聞的情報臺新進展。Google指出,經過幾年改善,現已能自動辨識自然災害等突發新聞。為確保獲取最權威的消息,幾年前,Google偵測事件的時間需要40分鐘,現在新聞發布後數分鐘,Google情報臺就能即時掌握資訊。
另外,Google也使用了BERT語言理解模型,來改善新聞故事和事實查核的配對,找出事實與新聞主題的關聯性,並在Google新聞的完整報導功能,凸顯事實查核資料,告知使用者。不只如此,Google搜尋的自動完成系統也有所改善,Google設計一套自動化系統,一旦偵測到查詢系統可能提供不可靠的結果,就會選擇不顯示預測結果。(詳全文)
圖片來源/OpenAI、Google、微軟、Amazon
AI趨勢近期新聞
1. 資策會研發AI假訊息快篩平臺,多方面輔助事實查核
2. Line日本將推出Line Pay 3.0版新服務,要結合eKYC達成申請流程自動化
3. IBM提出對抗式攻擊的新防禦方法,找出AI誤判干擾手法來訓練偵測模組
4. 百度Apollo自駕計程車服務在北京上路
資料來源:iThome整理,2020年9月
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10