
Google Brain打造一套自動化工具TF-Coder,能修剪對等運算式等細節,來符合框架的要求。
Google Brain
重點新聞(0731~0806)
TensorFlow 程式碼 自動化
超越人類表現!Google Brain設計出深度學習框架自動化工具
Google Brain日前一篇研究論文揭露自家打造的自動化工具TF-Coder,可自動處理深度學習框架中的張量操作,來符合函式庫的複雜要求。Google Brain指出,深度學習框架雖然簡化了AI模型的訓練和迭代,卻有著陡峭的學習曲線,因為在這些框架中撰寫程式,比傳統條件式和循環式的命令程式撰寫還複雜。
因此,Google Brain設計了TF-Codedr來簡化這個過程,採用由下而上的加權列舉式搜尋方法,可對基於值的對等運算式(Expressions)和過濾(Filtering)來修剪,以符合框架的各種要求。Google Brain也用這套工具來測試,發現在70個搜尋任務中,TF-Coder可在5分鐘內解決其中的63個,而且比TensorFlow專家尋找最佳解的時間還要短,達到超越人類的表現。(詳全文)
微軟 生醫 自然語言處理
微軟釋出特定領域NLP預訓練模型,號稱比通用預訓練模型要精準
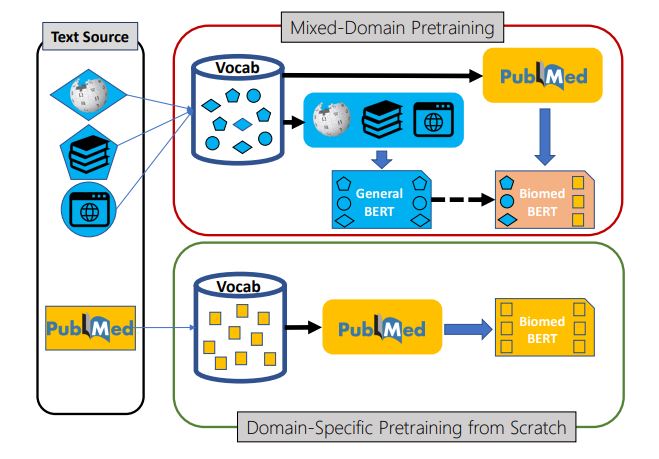
微軟發表一篇研究成果,指出以特定領域語料訓練出的NLP預訓練模型,比通用語料的預訓練模型還要準確,微軟也將自家打造的生醫NLP預訓練模型PubMedBERT和生醫語言理解基準BLURB一併釋出。
微軟表示,該研究推翻了對NLP預訓練的普遍認知。因為,要訓練一個特定領域的NLP預訓練模型,通常會以通用語料(如新聞、網頁文字等)訓練出的預訓練模型為基礎,如BERT等,再以一部分生醫領域語料,來進行遷移學習。但微軟想知道,在一開始就以特定領域語料來訓練,結果是否會更好;於是,微軟先以公開的生醫NLP資料集來訓練BLURB,可用來評估模型的生醫語言理解和推理能力。
再來,微軟以生醫資料庫PubMed的32億個單字和1,400萬個摘要,來訓練一套模型PubMedBERT,並以BLURB來測試。結果發現,PubMedBERT幾乎在所有的生醫NLP任務中,勝過以通用NLP預訓練模型訓練的版本。(詳全文)
Google雲端 武漢肺炎 預測模型
Google用新方法打造武漢肺炎預測模型,開放各界下載
日前,Google雲端與哈佛全球健康研究所共同開發、釋出武漢肺炎公共預測(COVID-19 Public Forecasts)模型,可提供未來14天,美國州、郡範圍內的醫療資源預測,比如ICU使用率、呼吸器可用狀況、病例數、死亡數等指標。
這套模型由公開資料訓練而成,像是約翰霍普金斯大學、笛卡爾實驗室、美國人口普查局等處的資料。Google表示,團隊特別設計一套新型時間序列機器學習架構,結合流行病學基礎,可顯示模型所學到的不同關係,讓研究員了解模型計算原理,大眾也能理解模型的預測原因。Google指出,使用者可從BigQuery中查詢該模型,也能免費下載CSV檔。(詳全文)

卡內基美隆大學 開源資料集 聲音辨識
CMU打造線上直播遊戲,要收集各種聲音來擴大智慧居家AI資料集
卡內基美隆大學(CMU)日前在直播平臺Twitch上打造一款遊戲Rolling Rhapsody,玩家在玩遊戲的同時,可「捐出」家中各種聲音,來增加CMU的開源聲音資料集。
CMU指出,這款遊戲的原理,是透過直播主(Streamer)控制一顆球,在設定的場景中移動,來收集散落在各地的寶藏。同時,玩家(Viewer)在遊戲中,可透過手機App錄一段音檔,像是家中各種聲音,再上傳到遊戲平臺,作為捐獻。上傳後的音檔,除了會用於遊戲背景音樂、讓玩家得到獎勵,也會成為開源資料集的一部份。此外,團隊也設計了一些功能,讓玩家可編輯不小心錄到的私人對話或聲音,或是刪除檔案。團隊表示,這個方法,可收集到比群眾外包方式還多元的聲音,有助於未來訓練智慧居家AI。(詳全文)
模型透明度 Model Card Google
評估模型透明度更輕鬆!Google釋出模型卡工具包Model Card
Google日前釋出一套模型卡工具包Model Card Toolkit(MCT),可大幅簡化機器學習模型透明度的評估,讓社群成員能更輕鬆建立模型卡。模型卡是Google開發來觀察模型透明度的工具,可提供模型來源、使用方法和道德規範相關評估資訊的結構性框架,還會提供模型使用限制建議。
但要建立這樣的模型卡,十分耗時耗力,為解決問題,Google打造了MCT,以JSON架構為核心,定義了模型卡中的欄位、提供ModelCard資料API,可用來表示JSON架構的實例,並視覺化成模型卡,用戶最終可決定模型卡要顯示的指標和圖形。(詳全文)

LinkedIn 資料處理 求職配對
LinkedIn用AI提高職缺配對成功率
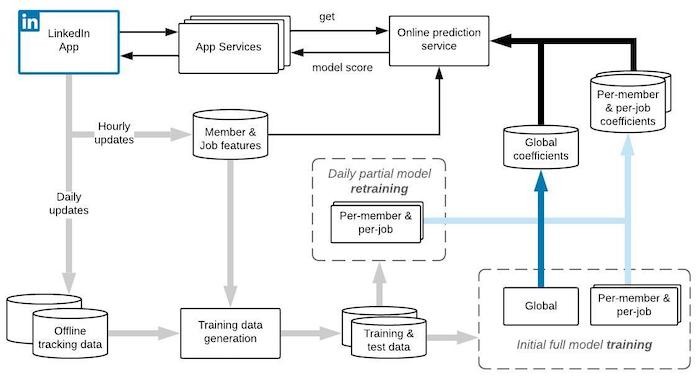
LinkedIn日前揭露用AI來配對求職者與招聘者的方法,透過合格申請(QA)模型,來學習招聘者與應徵候選者的互動行為,推薦應徵者適合的工作,同時也為招聘者依適合程度排名應徵者。
QA模型目的,是要預測應徵者申請某項工作後,得到回應的可能性。QA模型會預測招聘者積極採取行動的機率,像是查看應徵者的個人資料、發送訊息、邀請面試等。為此,LinkedIn採資料串流處理工具Apache Samza和Apache Kafka,建立近即時的資料收集與訓練工作流程,能非同步訓練和更新個人化模型元件,因應不斷發生的新變化。後來,LinkedIn也部署新模型,招聘者與應徵者的互動率也出現兩位數成長,此外,Premium等級的使用者的點擊率也有所提升。(詳全文)
程式語言 Python Java
Python首次取代Java,拿下RedMonk程式語言排行第二
RedMonk發表2020年第3季的熱門語言程式排名,比起去年同期,JavaScript仍穩占第一名寶座,但Python正式擠掉Java,成為第2名,Java退到了第3名。
RedMonk熱門語言程式排名是綜合GitHub以及Stack Overflow平臺得到的排行結果,GitHub反應了程式碼實際使用狀況,而Stack Overflow則呈現程式語言被討論的熱度,因此RedMonk的程式語言排行,可看出未來的採用趨勢。RedMonk指出,Python是一種黏著語言,成千上萬的專案都靠Python黏合,而Python也在新興技術找到立足之地,像是資料科學和AI應用,RedMonk認為,只要Python成為開發專案的熱門選擇,就會繼續在語言排名中表現亮眼。(詳全文)
![]()
TPU MLPerf 模型訓練
30秒就完成6種模型訓練!Google刷下MLPerf基準測試新紀錄
Google近日突破機器學習基準測試新紀錄,在MLPerf基準測試的6個模型中,拿下訓練速度最快的佳績,甚至在排名與推薦模型DLRM的訓練上,速度達到之前最佳紀錄的2.8倍。
Google這次所使用的超級電腦,規格是Cloud TPU v3 Pod的4倍,具4,096個TPU v3晶片,與搭載數百顆CPU的主機,最高可輸出430 PFLOPs高峰效能。Google使用TensorFlow、JAX和Lingvo中的機器學習模型實作,從零開始訓練Transformer、SSD、BERT和ResNet-50模型,訓練時間皆在30秒內。(詳全文)
圖片來源/Google、卡內基美隆大學、微軟、RedMonk、LinkedIn
AI趨勢近期新聞
1. Juniper推出AI故障排除工具使企業網路營運更自動化
2. TensorFlow 2.3加入新API解決資料工作管線載入瓶頸
3. Lyft開源基礎設施統一管理平臺Clutch
資料來源:iThome整理,2020年8月
熱門新聞

2026-03-06



2026-03-06

2026-03-09


2026-03-09

2026-03-09