機器學習框架TensorFlow團隊發布了最新2.3版本,這個版本的更新重點,加入了新工具,讓使用者可在一臺或是多臺電腦中,能夠輕鬆地載入並且預處理資料,解決輸入工作管線瓶頸的問題。另外,TF Profiler還加入了記憶體分析器以及Python追蹤器,方便開發者追蹤程式執行狀況。
tf.data加入了兩種機制解決輸入工作管線的瓶頸,以提高資源利用率。當連接到訓練裝置的主機,無法滿足模型消耗資料的需求時,將無法完全發揮加速器效能,進而拖慢訓練速度,官方提到,現代的加速器,無論是GPU或TPU,運算速度都非常快,假設當加速器每秒可以分類200個範例,但是資料輸入管道每秒只能從磁碟中載入100個,那加速器將會有50%處於閒置狀態。
對於這種情況,tf.data新的服務API可提升訓練速度,透過將資料分散預先載入到訓練的叢集中,並且進行預處理,如此便能每秒產生200個範例,使訓練速度提高一倍。官方表示,雖然分散輸入工作管線,是個有用的工具,但是當用戶工作僅在單一電腦上,則分散式方法可能無用武之地,因此tf.data也提供了工具,改善單一電腦上輸入工作管線的效能。
除了新的服務API,tf.data還多了快照API,可以將預處理工作管線中的資料,輸出到磁碟中永久保存,以便在不同的訓練中重複使用,官方提到,當用戶執行運算成本較高的預處理資料集,像是經剪裁或旋轉的圖片,則能在預處理結束後儲存,以便在不同的訓練中使用,節省CPU和加速器時間。
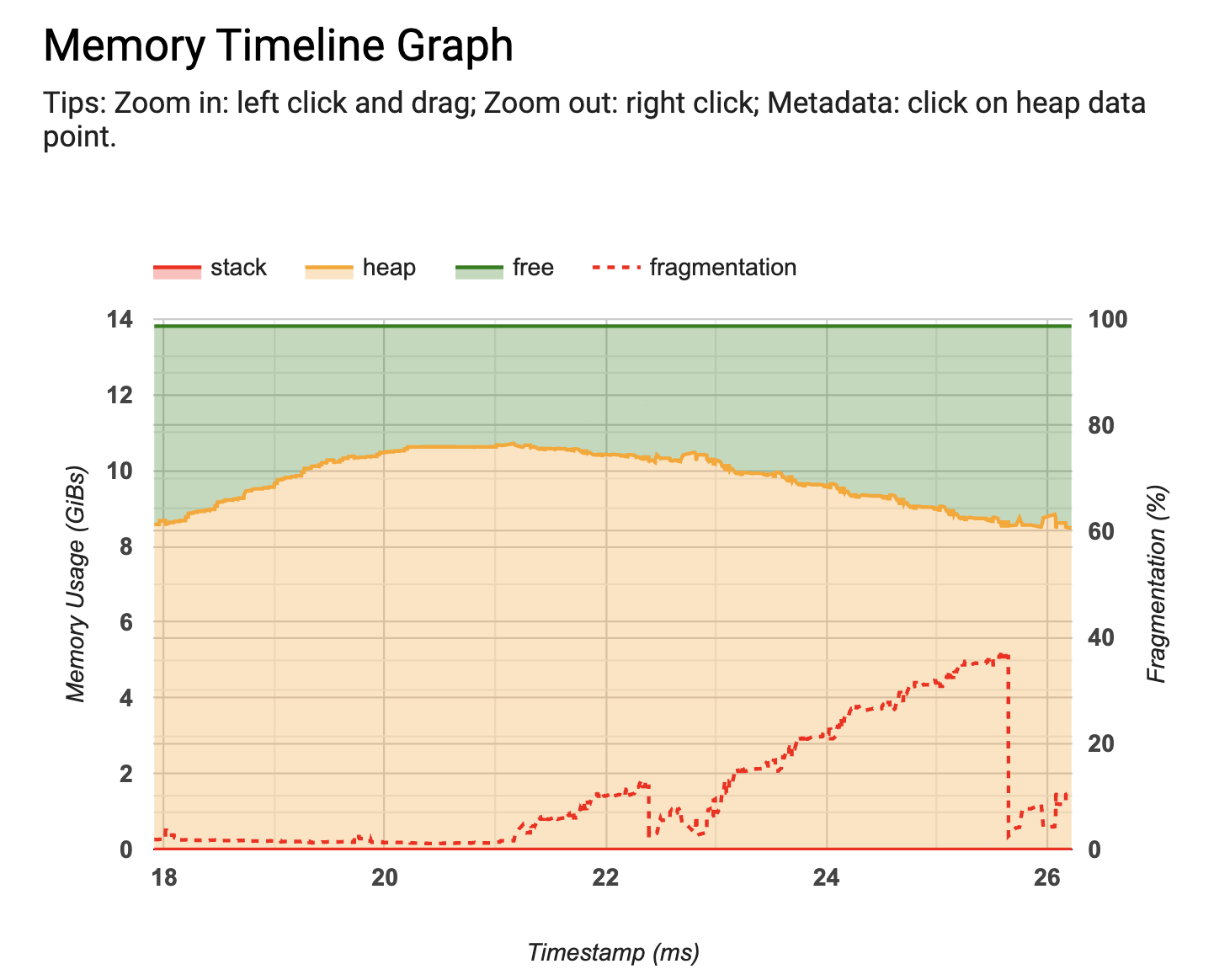
另外,TensorFlow 2.3的TF Profiler加入了兩個新功能,分別是記憶體分析器(下圖)以及Python追蹤器。記憶體分析器能讓用戶在模型訓練期間,監控記憶體的使用狀況,以便分析在訓練工作期間遭遇記憶體不足的情況,更全面了解記憶體高峰使用,以及大量消耗記憶體的操作。而Python追蹤器則能監控Python的呼叫堆疊,提供更多程式執行中的資訊。
而TensorFlow 2.3新加入了Keras預處理層,這是一個實驗性功能,讓用戶能夠將預處理邏輯,當作是模型中的一部分包含在模型內,因此在模型輸出時,預處理層就會像是模型其他層一樣,被儲存起來,並讓之後的部署更簡單。官方舉例,使用者可以利用這個新功能,創建物體偵測模型,模型本身就能包含調整大小、縮放和正規化層,也就是說,該模型的輸入可以接受任何尺寸的圖像,並自動正規化像素值。
對於結構化資料來說,可以使用諸如StringLookup之類的預處理層,對分類特徵進行編碼,因此開發者將可以開發模型,並將表格中的列資料作為模型的輸入。官方提到,這項功能仍在實驗階段,他們預計會在2.4版本使其脫離實驗階段,想要將其用在生產環境的用戶,可能還需要等等。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02