
百度日前發表21個深度學習框架PaddlePaddle的新功能,其中包括1款自然語言處理預訓練模型ERNIE,號稱在基準測試GLUE的16個任務中,表現更勝Google的BERT。
百度研究院
重點新聞(1115~1121)
百度 深度學習框架 PaddlePaddle
百度一口氣發表21項深度學習框架PaddlePaddle新功能,首重輕量版框架、聯合學習模型與低門檻開發套件
繼3年前百度開源分散式深度學習框架PaddlePaddle至今,已獲150萬人次使用,日前更在自家開發者大會上,一口氣發布21項新功能,包括了輕量版深度學習框架Paddle Lite 2.0、注重資料隱私的PaddleFL聯合學習框架,以及低門檻深度學習開發套件等。
百度CTO王海峰表示,Paddle Lite 2.0鎖定邊緣裝置的AI推論需求,比如手機、內嵌式或IoT裝置。透過Paddle Lite 2.0,開發者只要用7行程式碼,就能在FPGA晶片上,執行影像辨識模型ResNet-50,並保持低延遲。
另一方面,由於資料隱私日益受重視,百度也推出聯合學習框架PaddleFL。百度指出,聯合學習是加密的去中心化機器學習方法,可針對大量分散的數據來訓練模型,不必經過傳統的集中式資料中心。同時,PaddleFL也支援FedAvg演算法、差分隱私SDG演算法,也可共享演算法研究。
為了降低AI模型開發門檻,百度也發布4款PaddlePaddle開發套件,包括用於自然語言理解的ERNIE、用於影像辨識的PaddleDetection和PaddleSeg,以及用於推薦系統的Elastic CTR。其中,ERNIE是一款預訓練框架,可從多任務學習中累積知識,百度稱ERNIE在NLP基準測試上的表現,較Google BERT和XLNet要好。(詳全文)
Nvidia Magnum IO 資料分析處理
速度快20倍!Nvidia推出資料處理軟體Magnum IO
鎖定巨量資料處理與高效能運算需求,Nvidia日前推出資料處理軟體Magnum IO,要加速資料科學家的資料處理流程,將原本需要幾小時的流程,縮短為數分鐘。Nvidia指出,Magnum IO突破了儲存和I/O(輸入/輸出)的瓶頸,可在執行複雜的高效能運算任務時,針對多伺服器、多GPU節點的環境,提供快上20倍的資料處理效能。
Nvidia也表示,Magnum IO的核心在於GPUDirect,可讓資料跳過CPU,直接進入GPU和記憶體,簡化傳輸過程。GPUDirect由點對點(P2P)和RDMA技術打造,與許多傳輸連結和API相容,像是NVLink、NCCL、OpenMPI和UCX等。Magnum IO目前已上市,Nvidia也計畫在明年推出GPUDirect Storage,讓使用者在存取資料時,可繞過CPU,直接從儲存系統中取得資料,來進行模擬、分析和視覺化等作業。(詳全文)
血液透析 血流量測 瘻管阻塞
洗腎病友福音!交大研發手持式AI血流量測器,在家就能自我檢測瘻管阻塞
交大電機工程系特聘教授趙昌博,日前發表自行研發的非侵入式手持AI血流量測器與App,只要10秒就能偵測洗腎患者的瘻管狀態,不必到大醫院檢查,病患在家就能自己量測。他透露,目前正在準備申請美國FDA驗證,若通過,最快明年上市。
對慢性腎病患者來說,需長期定期洗腎來維持生命。而洗腎前,患者須先在皮膚下方建置動脈瘻管才行。但在瘻管建立的兩年內,8成病人會發生瘻管阻塞,嚴重可能導致尿毒症等致命併發症。而交大開發的手持非侵入式光學血流量測器,可讓民眾自行在家檢測瘻管狀態。團隊利用光體積變化描記圖訊號(PPG)原理,藉血液流動對光吸收的變化,以特殊波長陣列來設計光學感測器,來感應皮下血管血流訊號,但蒐集到的大量資料帶有雜訊,團隊藉AI自動找出血管血流訊號,大幅提高準確度。該AI模型也已於兩家大型教學醫院測試,已累積200筆洗腎病友的量測資料,準確度約91%,接下來要達到1,000筆的測試。(詳全文)

Intel 邊緣運算 視覺處理器
Intel發表邊緣運算新一代VPU,每瓦推論運算效能比Nvidia TX2高6.2倍
Intel日前在AI Summit年會上揭露發表新一代Movidius視覺運算處理器(VPU)Keem Bay,要搶進邊緣運算的市場,也在VPU搭配的軟體工具集OpenVINO中,新增了DevCloud硬體部署測試平臺,企業能直接從雲端上傳訓練好的模型,來測試出最適合該模型的硬體設施。
VPU是Intel 3年前併購Movidius後,所推出的影像分析專用處理器。這次新發表的VPU Keem Bay是第三代VPU,專攻IoT邊緣運算,能推論影像以外的資料,像是語音、社群媒體中的用戶行為等邊緣端非結構化資料。Intel表示,Keem Bay的推論效能為同類產品Nvidia TX2的4倍,也是華為Ascend 310的1.25倍。雖然還比不上Nvidia另一款旗艦產品Xavier,但在同樣表現下,Keem Bay的功耗只有30瓦,約為Xavier的五分之一。(詳全文)
微軟Bing 圖片搜尋 深度學習
Bing揭露3大深度學習方法,讓圖片搜尋更精準
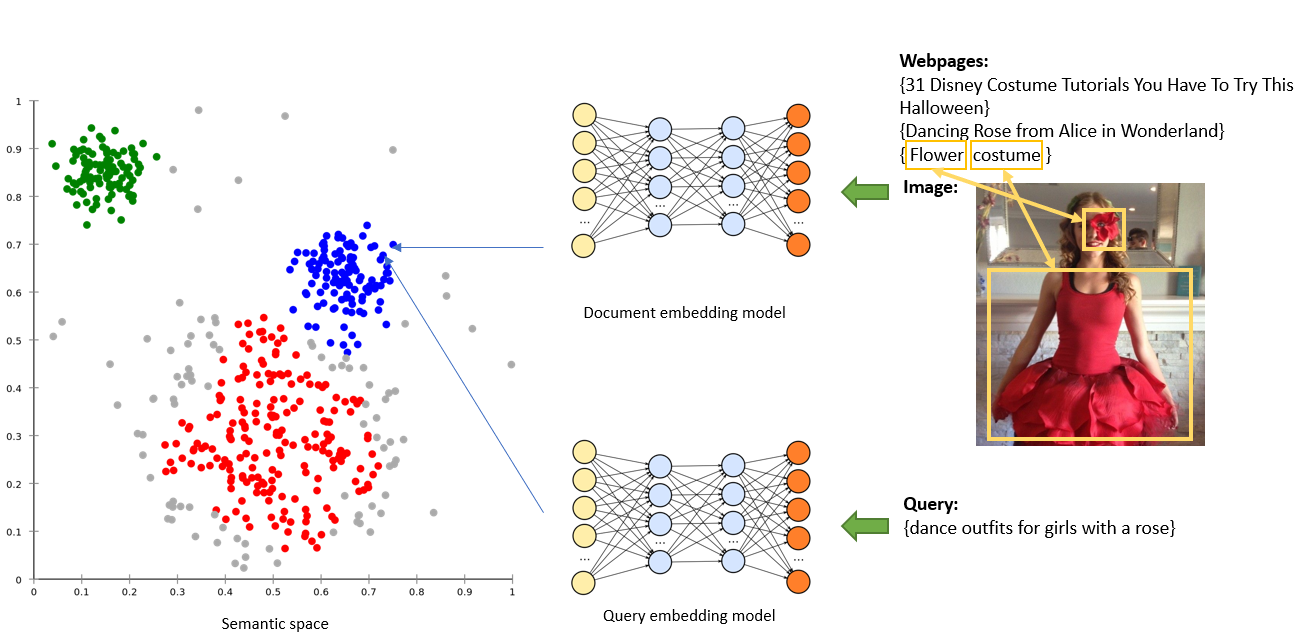
微軟Bing日前公布改善自家圖片搜尋的深度學習方法,包括了向量配對、屬性配對和最佳特徵搜尋(BRQ)配對。雖然Bing已採用多種深度學習方法來改善圖片搜尋功能,但仍美中不足,比如無法根據上下文或屬性,來精確給出使用者想搜尋的圖片。
於是,Bing團隊想出一個辦法,首先利用向量配對來映射詞彙間的相關性,以Google的自然語言預訓練模型BERT為基礎,來強化語意理解,透過注意力機制(Attention Mechanism)來強化圖片與詞彙的關係。接著利用屬性配對,從使用者輸入的長串關鍵字和圖片特徵中,找出相符的屬性;接著,他們使用BRQ配對,則可將長篇的網頁訊息縮短為一句總結,或是將圖片訊息簡化為最具代表性的描述;這些訊息會嵌入圖片中,並與使用者的搜尋作比對,來給出精確的結果。(詳全文)
Google 邊緣運算 MobileNetV3
Google發表最新邊緣機器學習模型MobileNetV3和MobileNetEdgeTPU
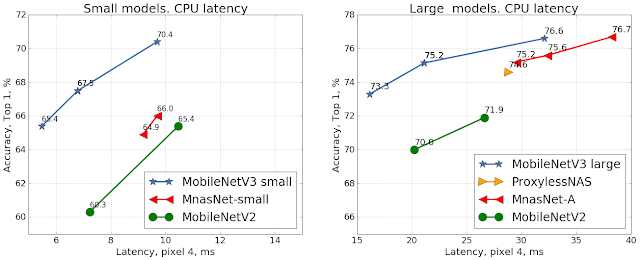
Google日前發表兩款邊緣運算模型,分別是:MobileNetV3和MobileNetEdgeTPU,要來提高機器學習模型在裝置上的運算速度,並減少功耗。Google表示,在同樣精準度下,MobileNetV3的運算速度比前一代MobileNetV2快上兩倍,而MobileNetEdgeTPU則提高了模型準確度,同時也減少模型運算時間、降低運算功耗。
這次釋出的兩款模型,都是以AutoML設計、優化產生的。就MobileNetV3來說,除了分類任務,這次還加入了物件偵測模型,與前一代相比,具有低延遲優點。而MobileNetEdgeTPU也具低延遲和高準確度的優點,同樣能在硬體Edge TPU上執行,而且比MobileNetV2和極簡型MobileNetV3還要省功耗,連極簡型MobileNetV3的一半都不到。(詳全文)
GitHub 程式碼代管 Arctic Code Vault
GitHub首個行動程式問世,明年還將啟用可保管程式碼上千年的Arctic Code Vault儲存庫
原始碼代管平臺GitHub日前宣布釋出GitHub行動程式測試版,更發表GitHub Arctic Code Vault,號稱可將重要的程式碼保存超過1,000年。GitHub首個應用程式GitHub for mobile主要是用來維持開發者與團隊的聯繫,比如針對某個設計來討論,或檢查程式碼、合併變更等。不過,該應用程式目前只支援iOS測試版,日後將釋出Android版。
另一方面,GitHub也揭露了GitHub Archive Program檔案封存專案,目的是要保存開源碼,讓後代使用。GitHub指出,該專案將使用自家位於北極永凍區200公尺深的程式碼儲存庫Arctic Code Vault,並將於2020年2月2日,拍下每個活躍的公開儲存庫快照,存放在這個儲存庫中。(詳全文)
攝影/王若樸
圖片來源/百度、Google、微軟Bing
AI趨勢近期新聞
1. 台電半年打造即時系統負載調度輔助工具,用AI預測用電減,少9成人力
2. 微軟開始於Azure提供Graphcore AI晶片雲端服務
3. IntelliCode獲OpenAI GPT-2模型強化,現可提供全行程式碼完成建議
4. 臉書設計出注視點渲染AI DeepFovea,讓VR開發更省運算資源
資料來源:iThome整理,2019年11月
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-02

2026-03-02