
臉書為建構更具吸引力以及個性的人工智慧聊天機器人,使用新的資料集、演算法及模型,改進聊天機器人普遍存在的一致性、特殊性和同理心等5大弱點,經臉書改進的對話機器人,現在除了會在回應中表現喜好之外,還能自然地在回應中加入額外的知識,提升對話品質。
臉書提到,對話研究是建構下一代智慧代理人很關鍵的部分,雖然現在聊天機器人可以在單個領域的對話,表現得很好,但是還遠無法跟人類進行跨多主題的開放領域對話。臉書想讓智慧代理人執行播放歌曲或是預定等任務時,還可以跟人類自然地就日常生活交談,以提升使用體驗,但要在對話中產生連貫且引人入勝的回應並不容易,人工智慧需要學習細微的對話技巧,包括語言理解和推理能力。
為此臉書針對目前5個人工智慧聊天機器人常見的弱點進行強化,包括一致性、特殊性、同理心、知識性和多模式理解。臉書表示,聊天機器人的對話普遍缺乏前後一致性,前面對話說自己有養兩隻貓,但是後面問他貓的名字時,可能又會說自己沒有養貓,為此臉書與紐約大學合作,開發自然語言推理(Natural Language Inference,NLI)技術,並創建對話NLI資料集。
對話NLI資料集會將對話中的兩個語句當作前提和假設,並標記前提和假設的關係,是相關、矛盾還是中性的,模型使用對話NLI資料集訓練後,經過3個測試資料集的實驗,證實有效降低聊天機器人3倍的對話矛盾。
聊天機器人傾向回應保守且安全的句子,像是我不知道,而經過實驗,人們更偏好特別的回答,臉書透過控制多個對話屬性,調整機器人回應的特殊性。當人類問聊天機器人的職業時,臉書新模型所產生的答案,不只回答自己是建築工人,還會進一步描述具體細節,回答自己正建造骨董屋和翻新房屋。

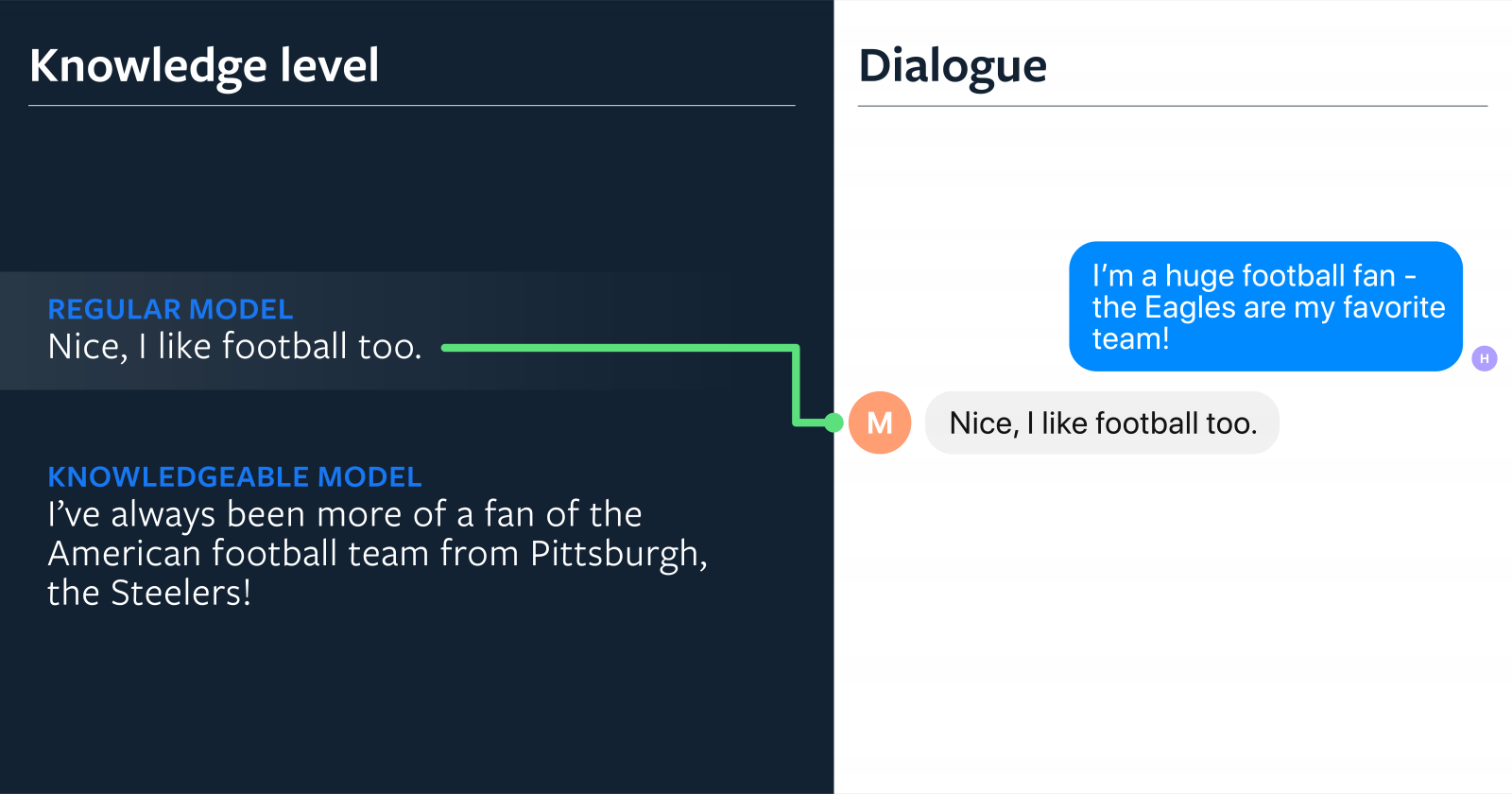
臉書也與華盛頓大學合作,開始研究讓聊天機器人更具同情心,這能夠解決因為人工智慧無法正確感受人類的情緒,而做出不洽當的回應,現在當人類提到自己工作升遷時,聊天機器人可以先給予祝賀,而不是反問人類為什麼能夠獲得升遷。

另外,人類談話的時候,通常能夠自然地將知識融入到對話中,但這點對於開放領域聊天機器人還難以辦到。臉書解決這個問題的想法,是在模型中採用更直接的知識記憶機制,收集基於維基百科知識的對話資料集,並使用新的模型基礎架構擷取與使用這些知識,改進對話模型展示知識的能力。
而在許多時機,對話會參雜圖片,因此聊天機器人不只需要理解對話,還要能理解圖像,臉書則努力使得聊天機器人對圖片的回應更具人性,而非只是給出傳統的圖說。臉書收集了人類圖像評論資料集,並建構名為TransResNet的檢索架構,將圖像、個性以及圖說資訊投影到同一個空間,以產生綜合的結果,臉書提到,在部分案例,新模型所產生的圖片註解,已經接近人類的表現,而比起一般的圖說,約有50%的人更喜歡新的圖片評論。
熱門新聞

2026-03-06




2026-03-06

2026-03-09

2026-03-09

2026-03-09