微軟
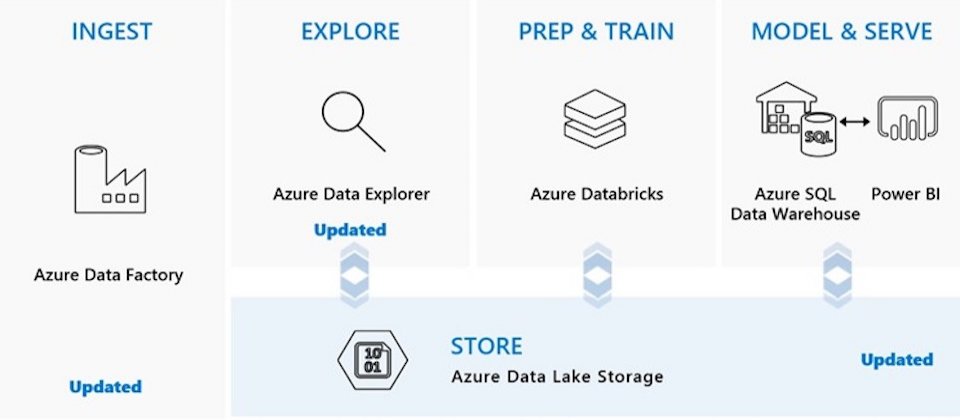
微軟雲端平臺Azure最近宣布針對3項資料服務的更新,包含推出正式版的資料湖儲存服務Data Lake Storage Gen2和資料完全託管服務Data Explorer,此外,還推出預覽版的混合資料整合服務Data Factory,期望提供用戶性價比高又安全的雲端資料分析服務。
資料湖儲存服務Data Lake Storage Gen2適用於巨量資料分析,結合了Azure非結構化儲存服務Blob Storage的可擴展性、安全模型和豐富的功能於一身,再加上為分析所設計的高效能的檔案系統,還能與Hadoop分散式檔案系統相容,讓用戶選擇雲端資料湖服務時,不需要在成本和效能中取捨。
.png)
圖片來源:微軟
微軟指出,自家資料湖儲存服務其中一項主要目標,即是要與Apache生態系統相容,為了做到這點,微軟開發Azure Blob檔案系統驅動程式,該驅動程式正式成為Apache Hadoop和Spark的一部分,並且附於許多 Hadoop的商業版本中。
為了進一步提升Data Lake Storage Gen2的分析效能,微軟用階層式命名空間,收集檔案集合並整理成階層式目錄和巢狀子目錄,此種命名空間對巨量資量分析架構相當重要,由於Hive或是Spark等工具經常將輸出寫入暫時位置,並在作業結束時重新命名該位置,若沒有階層式命名空間,重新命名所花費的時間通常會比分析流程本身更長,因此,階層式命名空間因為需要較少的運算執行,能夠加速job執行並減低成本。
而Data Explorer是一個快速且具有高擴展性的完全託管資料分析服務,能夠針對大量的串流數據進行即時分析,在不需要修改資料結構的情況下,一秒內能夠查詢10億筆記錄,此外,該服務能與微軟雲端其他服務相連,像是Data Lake Storage、SQL Data Warehouse、Power BI。為了提升速度和簡化操作,Data Explorer由兩個分別的服務組成:Engine服務和資料管理服務,這兩項服務都在Azure中,以運算節點的叢集形式部署。
.png)
圖片來源:微軟
資料管理服務負責消化多種不同型態的原始資料,並且管理資料清理、執行失敗和backpressure等任務,還能透過自動索引和壓縮機制快速處理資料。而Engine服務則是負責處理輸入的原始資料和用戶的查詢,透過自動擴展(Auto Scaling)和資料分割(data sharding)來達到高效能的目標。
最後,微軟這次的更新還推出混合資料整合服務Data Factory預覽版,Data Factory服務是用來將資料移動和轉換工作自動化的服務,內建超過80個與結構化、半結構化和非結構化資料源的連接器。除此之外,該服務還提供資料工作流程可視化工具Mapping Data Flow,提供用戶在設計、建置和管理資料轉換的過程有可視化的體驗,不需要學習Spark或是對分散式基礎架構有深入的了解。
.png)
圖片來源:微軟
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02