AWS
AWS近日在Alexa部落格中發表了一項只用新類別資料,來新增AI系統分類類別的研究成果,透過新方法將新增辨識類別的訓練工作最小化,該研究由Alexa研究團隊首席科學家Alessandro Moschitti和其來自義大利特倫托大學的同事Lingzhen Chen,近期會在美國AI協會舉辦的第33屆研討會中,發表只用新類別訓練資料,更新AI系統分類器技術的論文。
現今大部分熱門的AI系統核心都是分類器,藉由分類器將輸入資料分為多個不同的種類,舉例來說,分類器讀取狗的圖片後,能夠根據圖片的特徵,將該圖片分為狗,而不是貓,而語音的資料也是同理,但是,如果要在既有的分類器中加入新的種類,傳統的方法就需要大量的新類別訓練資料,經過繁雜的訓練的過程,才能更新分類器。
過去的方法需要大量地新類別資料,並將這些資料加入原本用來訓練分類器的資料中,最後再藉由整合的資料集,訓練出新的分類器,而現在的商用AI系統,都是透過數百萬的範例訓練而成,若要每新增一個類別就要重新訓練分類器,將會是非常費力的工作。
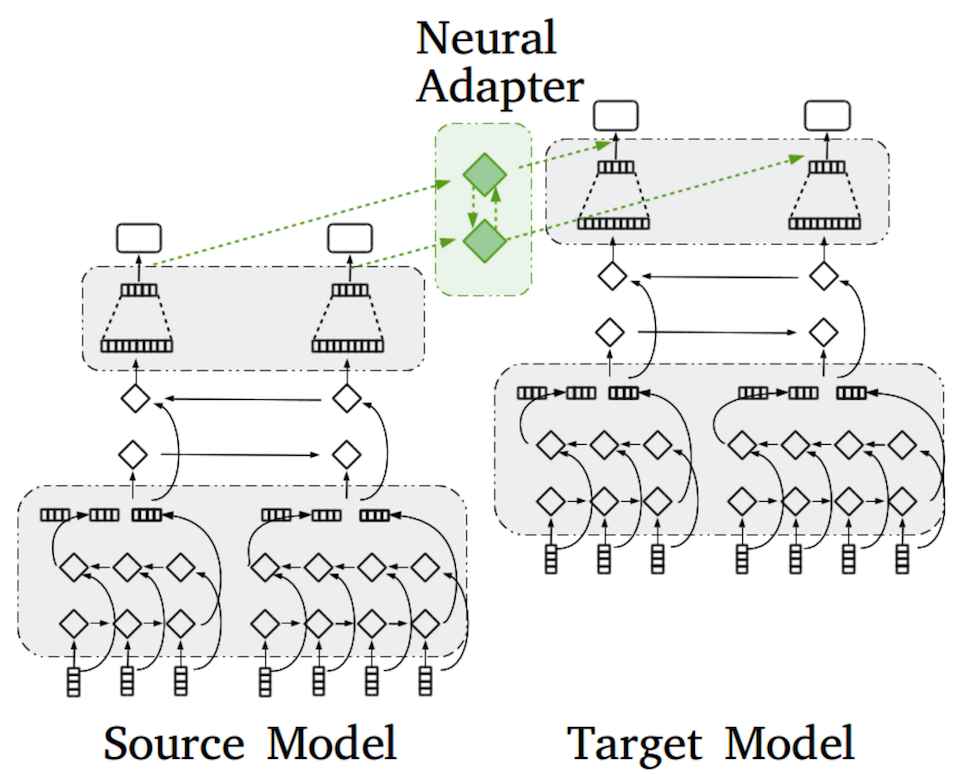
在研究實驗的範例中,研究人員訓練了可以辨識線上新聞文章中人和機構的神經網路,目標是要在原有的分類器中新增可以辨識地點的能力,實驗結果顯示,最有效地方法是保留既有的分類器,將分類器輸出的資料傳遞給一個獨立分開的分類器,研究人員稱之為神經適應器( neural adapter),接著,將神經適應器的輸出資料當作是第二個平行分類器額外的輸入資料,也就是說,適應器和新分類器是一起訓練的,在執行的過程,相同的輸入資料會一起通過分類器。
圖片來源:AWS
這項研究成果對Alexa意義重大,由於Alexa的開發團隊主要負責Alexa的核心功能,但是AWS也透過Alexa技能工具包,允許第三方開發者來打造自家的Alexa技能,現在已經有超過7萬個第三方開發的技能,這項研究成果能夠讓第三方開發者,在不需要存取訓練資料的情況下,直接利用Alexa的系統來開發新技能。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02