最近有幾項研究,致力於讓癱瘓無法說話的人也能再次說話,方法是倚靠人工智慧解讀大腦神經訊號,重建出人們可以理解的單詞與句子。
現在中風與其他原因失去說話能力的患者,可以使用眼睛或是其他部位的小動作來操作游標,在螢幕上點選字母進行語句表達,不過,大腦如果能透過連接電腦介面產生語音的話,那原本無法說話的人,將能用更加直覺的方式與其他人互動,甚至是與他人順暢的交叉談話。儘管難度很高,但近期的研究說明了這樣的可能性。
加州大學舊金山分校的神經外科醫生Edward Chang與其帶領的團隊,根據3名癲癇患者大聲說話時的大腦說話規畫區域與運動區域的訊號,已經能重建出完整的語句。研究團隊邀了166個人聽取電腦重建的聲音,並在10個句子選項選出正確的配對,發現電腦合成語句可辨識度超過80%。
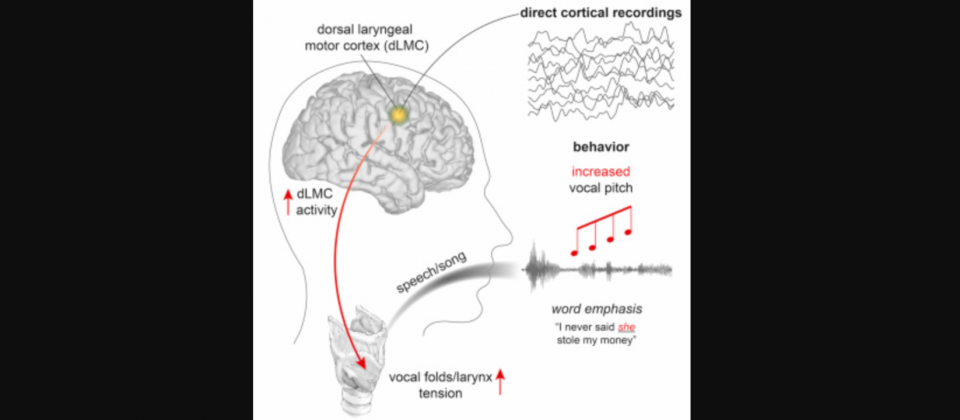
Edward Chang的研究甚至可以辨識出,人類大腦用來控制語音與歌聲高低的區域,喉嚨用發聲與控制音調的肌肉,由不同的神經群體編碼,他們透過刺激大腦皮層,證明了喉部肌肉控制的因果關係。
而哥倫比亞大學的電腦科學家Nima Mesgarani帶領的團隊,則是研究5名癲癇患者的腦部資料,他們讓病患聽錄音並且給予0到9的數字編號,並在同時錄製這些病患大腦聽覺皮層的訊號,透過神經網路分析這些訊號,電腦將能根據神經訊號重建口說的的數字,人們辨識這些電腦合成出來的數字語音的正確率能達75%。
該研究團隊根據神經元不同時間點開啟與關閉的模式推斷語音,Nima Mesgarani表示,要找到將神經訊號轉換成實際語音之間的映射關係很困難,他們需要對每個人進行特別的訓練,而且這個過程需要用到非常精確的資料,需要打開人類大腦頭骨以進一步獲得大腦神經元的訊號。
另一個研究是來自德國不萊梅大學神經克學家Miguel Angrick,與馬斯垂克大學Christian Herff帶領的研究團隊的合作成果,他們透過收集6位進行腦腫瘤手術患者的資料,以麥克風捕捉他們朗讀單音節單字的聲音,並同時以電極從大腦的說話規畫區域與運動區域紀錄訊號,這些區域在人們要說話時,會透過神經向聲道發送命令,類神經網路將電極收到的訊號,映射到患者的語音上,由系統重建的語音,約有40%的單字可供辨識。
不過,研究人員很少能進行這類侵入性的研究,因此除非是在切除腦部腫瘤,大腦暴露的時候,另一個時機則是癲癇患者在手術治療之前,需要植入電極數天以獲取準確癲癇發作來源時,但研究團隊仍最多只有20到30分鐘收集資料。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02