為了加速建構與部署自然語言處理系統,臉書開源了PyText,這是建構於開源深度學習框架PyTorch之上的函式庫,不只能模糊實驗和大規模部署階段,簡化工作流程更快速進行實驗,同時還能存取預先建置的模型基礎架構,以及文字處理和詞彙管理工具,幫助大規模部署。
臉書使用自然語言處理技術,向使用者提供相關的語言輔助功能、標記違反政策貼文以及進行翻譯。由於對話式人工智慧技術發展快速,臉書以PyText來快速推進這些應用提高服務品質,PyText現在還被用於臉書新的影像通話裝置Portal和Messenger中的M建議功能。
透過使用PyText,Portal中支援Hey Portal的組合與嵌套呼叫查詢的語音命令,該功能允許使用者以語音命令,進行諸如打電話等動作,臉書舉例,使用者可以使用「打電話給我爸爸」這樣的語句,而這需要系統了解呼叫者與被呼叫者的關係,PyText的工作之一便是能進行語義分析,並快速的將該技術應用到產品。
臉書利用PyText快速迭代的方式,漸進改進Portal的自然語言處理模型,包括加入組合演算法、條件隨機域以及合併模型等技術。這樣的方法讓其核心領域的模型精確度提高5%到10%,並且也因為PyText支援分散式訓練,讓Portal模型的訓練時間縮短了3到5倍。
PyText快速迭代不只能以漸進的方式改進模型,還可以提高自然語言處理模型的效率和可擴展性,無論是在Portal或是Messenger等其他應用,臉書都需要能即時的執行模型並且做出回應,並且能夠大規模高效能執行的自然語言處理系統,PyText現還為臉書數十億人存在多語言的社交平臺,提供進階即時的自然語言處理功能。
PyText能利用臉書的其他自然語言系統為基礎,補充其功能上的不足,像是工程師可以使用fastText函式庫訓練單詞嵌入,並在PyText中使用。另外,PyText改進了臉書現有文字理解引擎DeepText的缺點,並得利於GPU還有分散式訓練技術,PyText加速了整體訓練過程。由於模型中的條件執行和自定義資料結構,導致PyText無法與DeepText在部分語意解析和多任務學習模型等工作合作,臉書正計畫讓PyText作為主要的自然語言平臺,以增加系統未來的發展性。
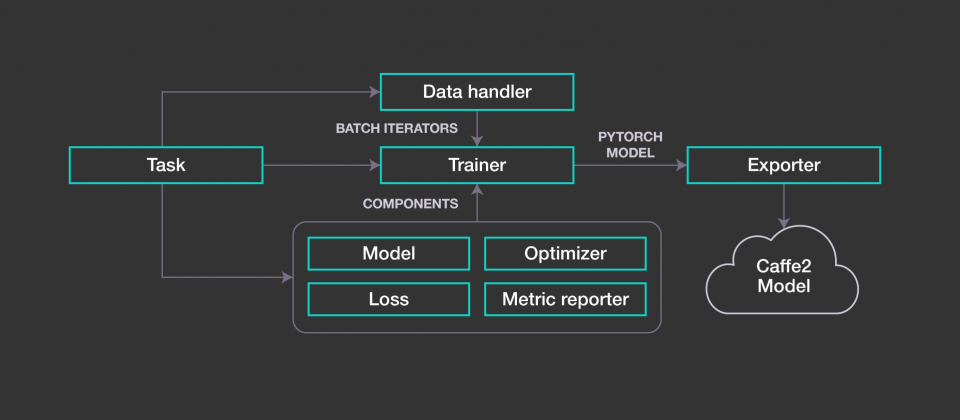
PyText建構於PyTorch之上,並且和ONNX與Caffe2互通,工程師可以將PyTorch模型轉換成ONNX,並以Caffe2輸出,作為大規模生產部署之用。PyText提供靈活模組化的工作流程,模型元件具有可配置的系統層與可擴展的介面,可作為端到端平臺,供開發人員開箱即用,創建完整自然語言處理工作管線。

其模組化的結構,允許工程師將各個元件整合到現有的系統中,每個元件的角色和與其他模組的交互作用,皆取決於特定的任務。這種模組化的設計方法增強了PyText的多功能性,幾乎可以在研究到生產的過程任一階段使用,無論是要從頭建構整個自然語言處理系統,抑或是對現有系統進行修改都可以。
PyText框架支援分散式訓練,以及可以同時訓練多個模型的多任務學習功能。由於 PyText模型建構在PyTorch之上,具高可移植性,可以在不同平臺間轉換,而且透過預建置的模型,例如文字分類,單詞標記、語意分析和語言建模,PyText可以簡單地在新的資料上使用預建模型。
為了最佳化產品階段的推理,PyText使用PyTorch 1.0的功能,輸出經過最佳化的Caffe2模型。原生PyTorch模型需要Python Runtime,但由於Python全局解釋器鎖(Global Interpreter Lock,GIL)多執行緒的限制,導致模型無法有效的擴展,但PyText使用者可以選擇輸出為Caffe2模型,就能利用高效能多執行緒C++後端,處理高吞吐流量。
經過內部部署後,臉書提到,PyText確實能夠快速迭代工程師的對自然語言建模想法,並將其框展至生產當中,PyText現為臉書提供每日超過10億次的推理。未來還會提供多語言建模和其他建模工具,讓模型更容易偵錯,並為分散式訓練進行最佳化,臉書也提到,目前要在行動裝置上部署複雜的自然語言處理模型仍然很具挑戰性,但他們仍朝向在裝置上建構端到端工作流程的方向努力。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02