臉書
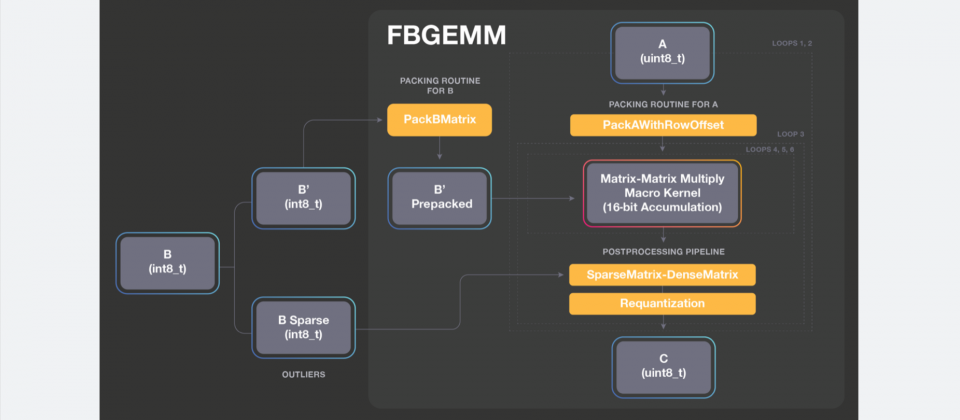
臉書開源特別針對伺服器推理進行最佳化的高效能核心函式庫FBGEMM,與其他函式庫不同的是,FBGEMM最佳化了CPU效能,透過降低精度計算以加速深度學習模型,目前臉書已經在自己的服務中使用了這個函式庫,對照於現今的生產基準,帶來了兩倍的性能提升。
為了讓大規模生產伺服器有效執行先進的深度學習模型,臉書因而建構了FBGEMM,這是一種低精度、高效能的矩陣相乘以及卷積網路函式庫,FBGEMM針對伺服器端的推理做了最佳化,在深度學習框架執行量化推理時,能夠同時兼顧準確性和效率,讓臉書基於CPU的系統,實現比前一代還要快兩倍的效能。
臉書把所有低精度推理需要的模組都打包進單一函式庫,開發者現在可以透過Caffe2前端來部署FBGEMM,並且在不久的將來,還能透過PyTorch 1.0的Python前端進行呼叫,而FBGEMM與前些時日開源的QNNPACK,同作為支援PyTorch 1.0平臺的一部分,全面支援量化推理。
FBGEMM最大的特色在於對低精準度資料的最佳化,與科學計算中使用的傳統線性代數函式庫不同,FBGEMM不使用FP32或FP64精度,能為小批次提供有效的低精度通用矩陣相乘(GEMM)運算,並且支援精準度損失最小化技術,像是Row-wise量化和異常值感知量化。
FBGEMM已經在臉書中大規模部署,加速了許多端到端的人工智慧服務,包括將英文翻譯成西班牙文的速度提高了1.3倍,減少了40%推薦系統資訊來源動態記憶體頻寬使用,並為機器學習系統Rosetta加速了2.4倍的字符檢測速度。Rosetta是臉書用來理解文字、圖片和影片內容的系統,被應用在臉書以及Instagram上的各式使用案例,包括自動識別違反社群規則或是個性化產品服務。
臉書提到,矩陣相乘的運算效率對機器學習來說至關重要,對臉書的資料中心來說,完全連接運算子(Fully connected Operators)是深度學習模型中浮點數運算的大宗。在臉書對自家資料中心進行分析,測量了24小時深度學習推理浮點數運算的分布,完全連接運算子占全部推理浮點數運算的77%。
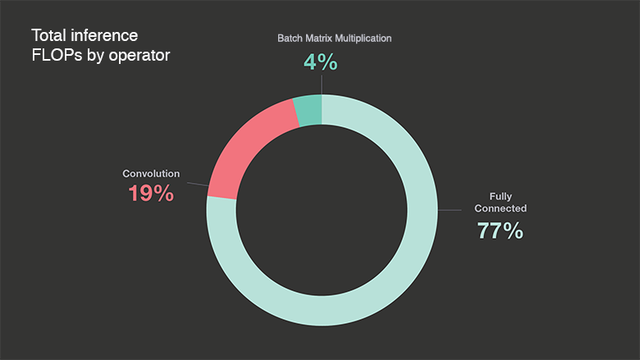
由於完全連接運算子就是一般的矩陣相乘運算,因此整體效率也就直接取決於矩陣相乘的效率,臉書提到,不少深度學習框架卷積依矩陣相乘運算實作為im2col,因為高效能運算領域中的線性代數函式庫,提供了高效能的矩陣相乘運算實作,但是im2col輸入資料的副本與複製動作,帶來了額外的成本,所以不少深度學習函式庫也實做了無im2col的卷積來提高效率。
而臉書提供了融合im2col和主要矩陣相乘運算核心的方法,以最大程度降低im2col帶來的額外成本,臉書提到,高效能矩陣相乘運算核心是一個重要的關鍵,通常在深度學習的高效能運算函式庫供給和需求都存在錯誤配對,高效能運算函式庫通常不支援有效率的量化矩陣相乘相關運算,也沒有針對深度學習推理中常見的矩陣形狀以及大小進行最佳化。
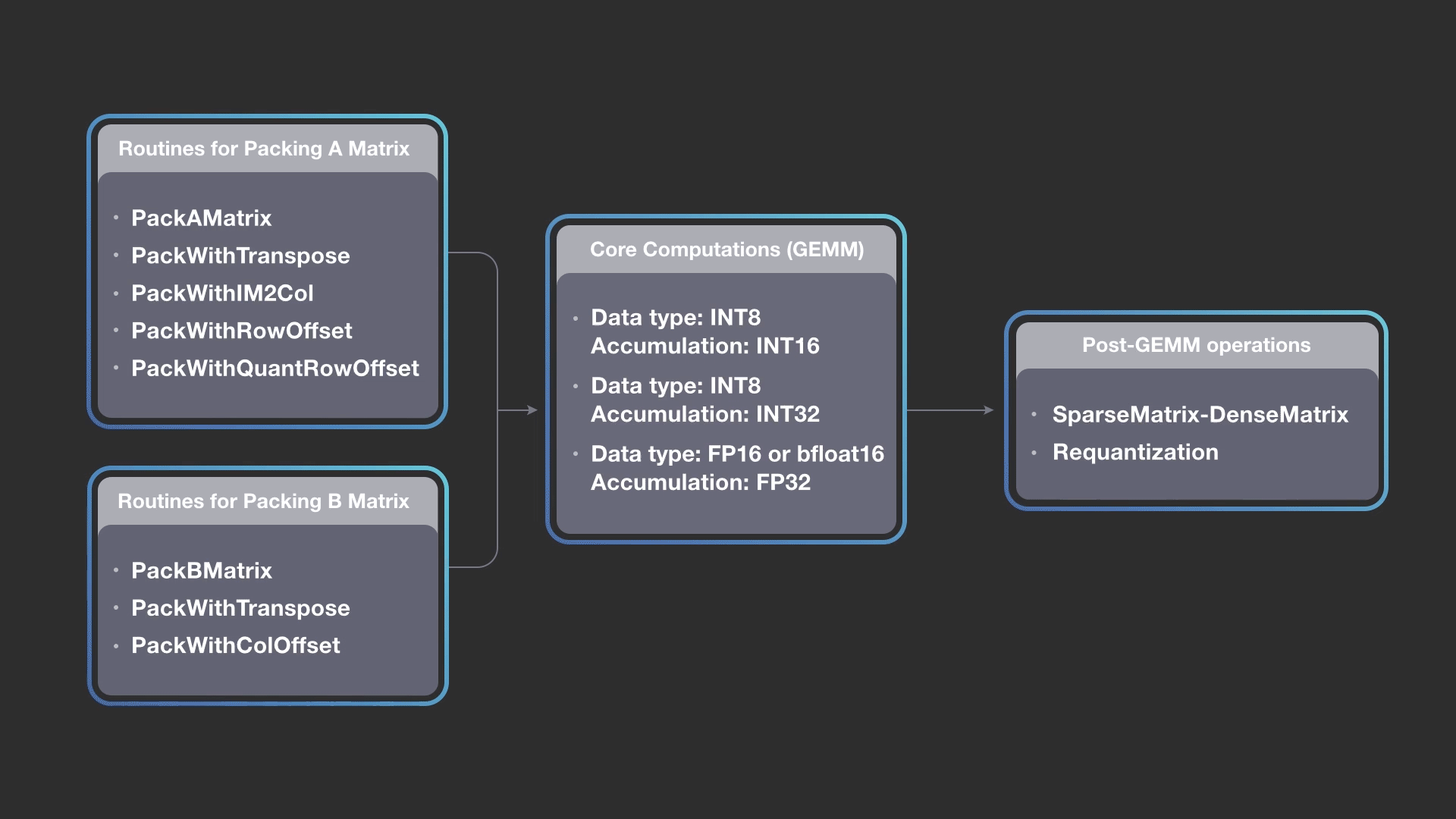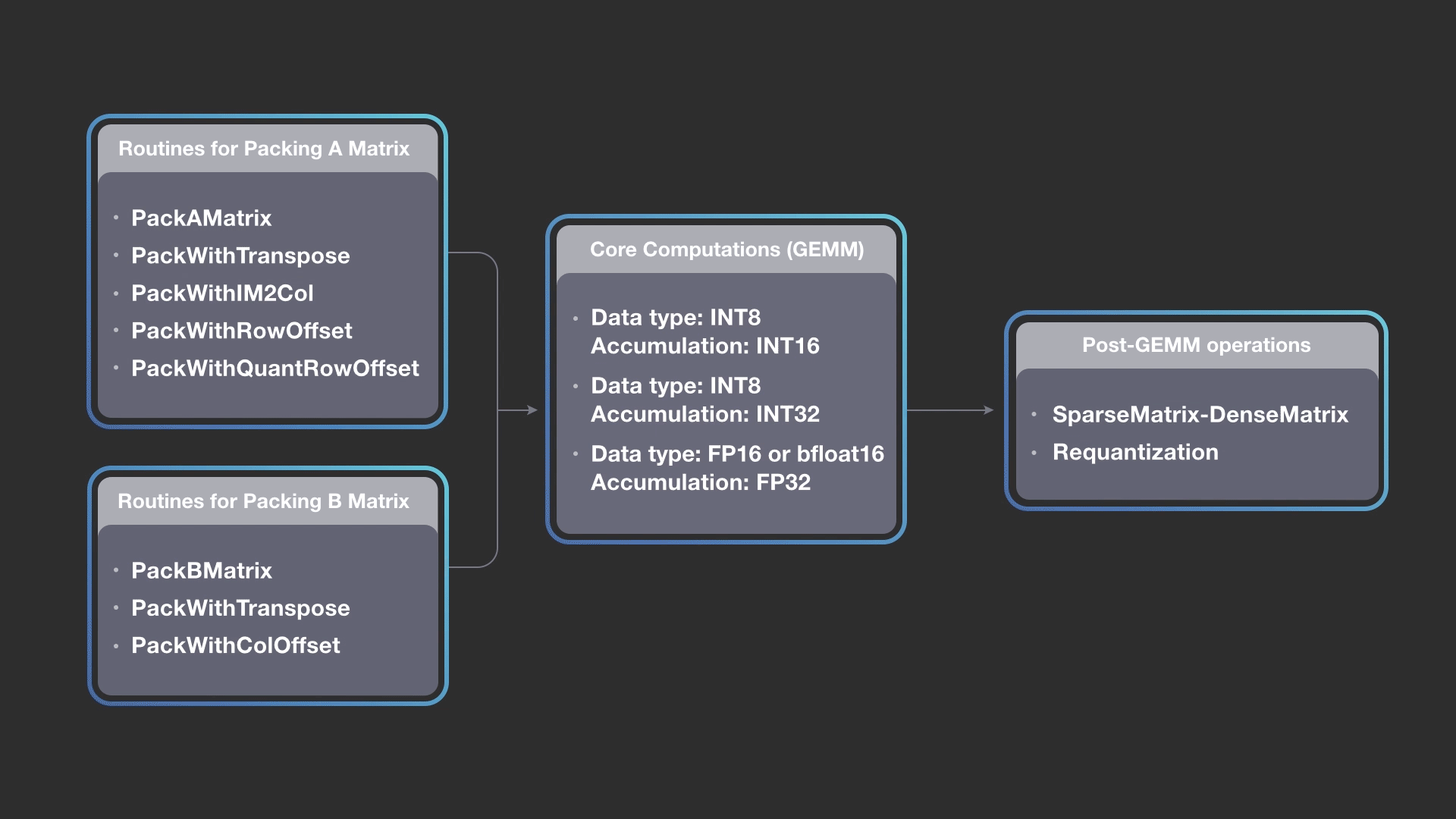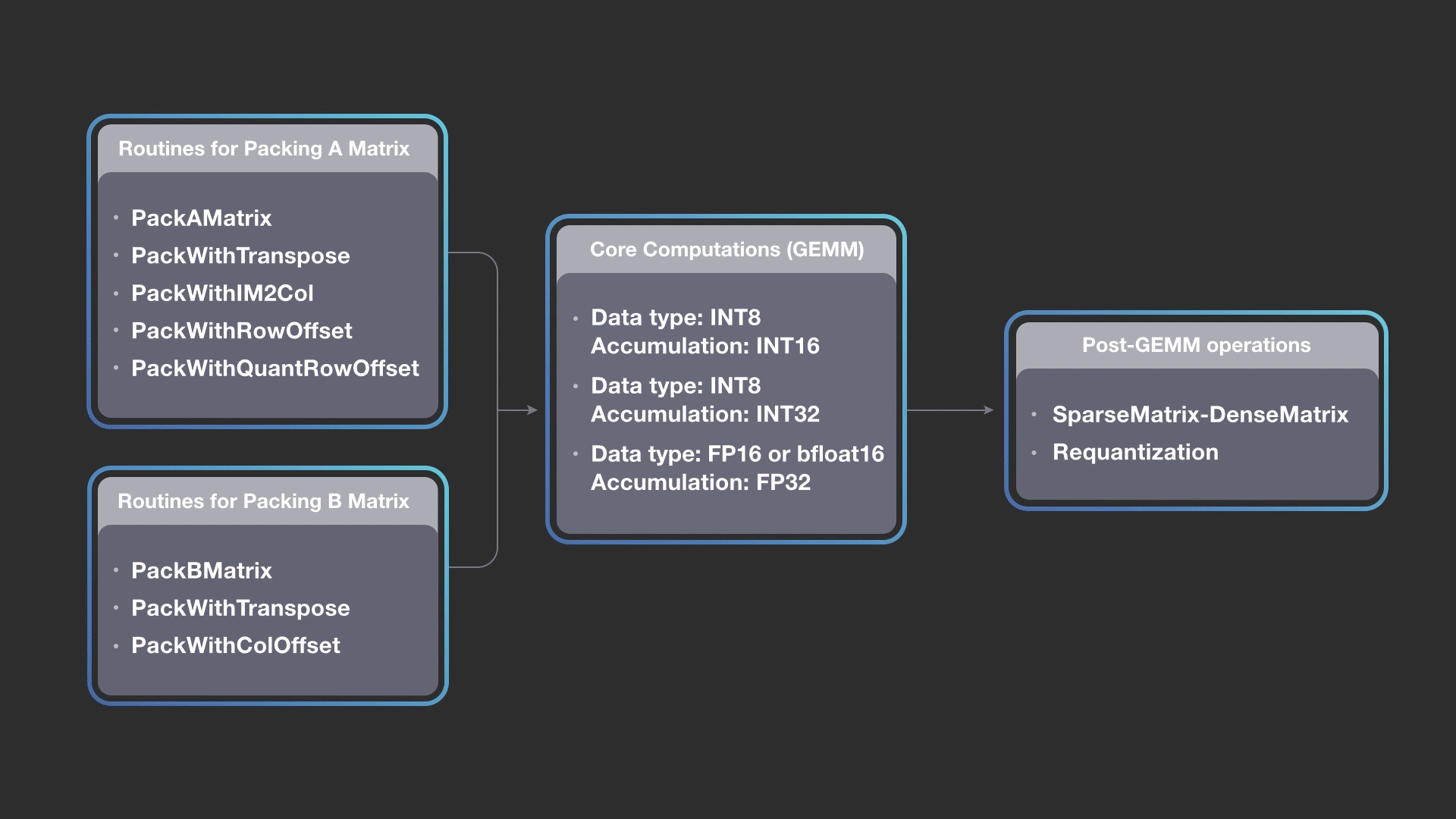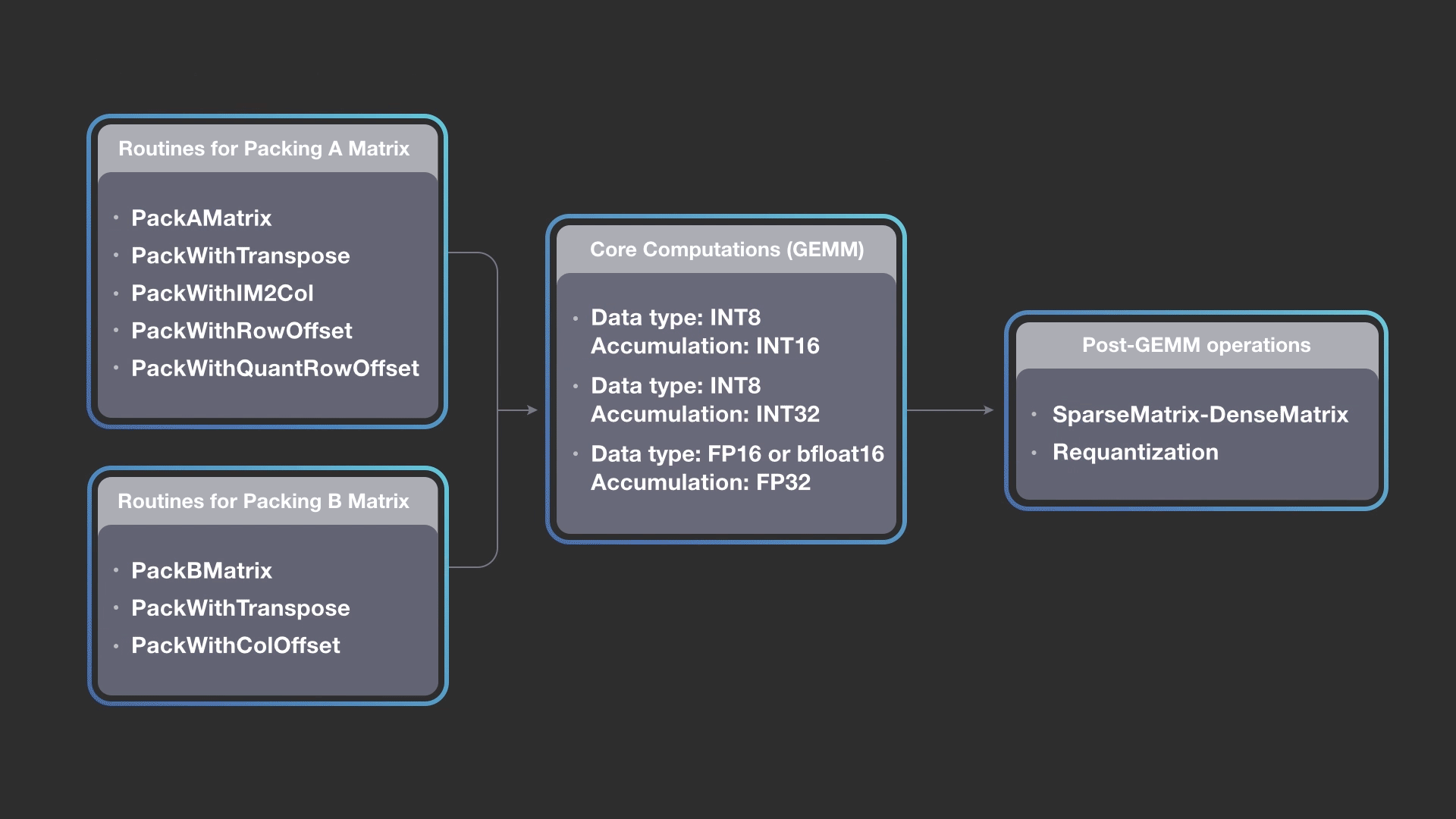
深度學習模型通常使用FP32資料類型來表達活躍度和權重,但使用具有混合精度資料類型的計算,通常更加有效率,臉書表示,最近的研究也都顯示,使用混合精度的推理,並不會對精確度產生不利的影響,FBGEMM透過這種替代性策略,加上量化模型來提高推理效能。
新一代的GPU、CPU和專用張量處理器,本身都支援低精度運算元,像是Nvidia張量核心中支援FP16和INT8,還有Google處理器也支援INT8,臉書提到,深度學習社群正往低精度模型發展,這也代表量化推理是正確的方向,而FBGEMM提供當前和下一代CPU,一種有效執行量化推理的方法。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02